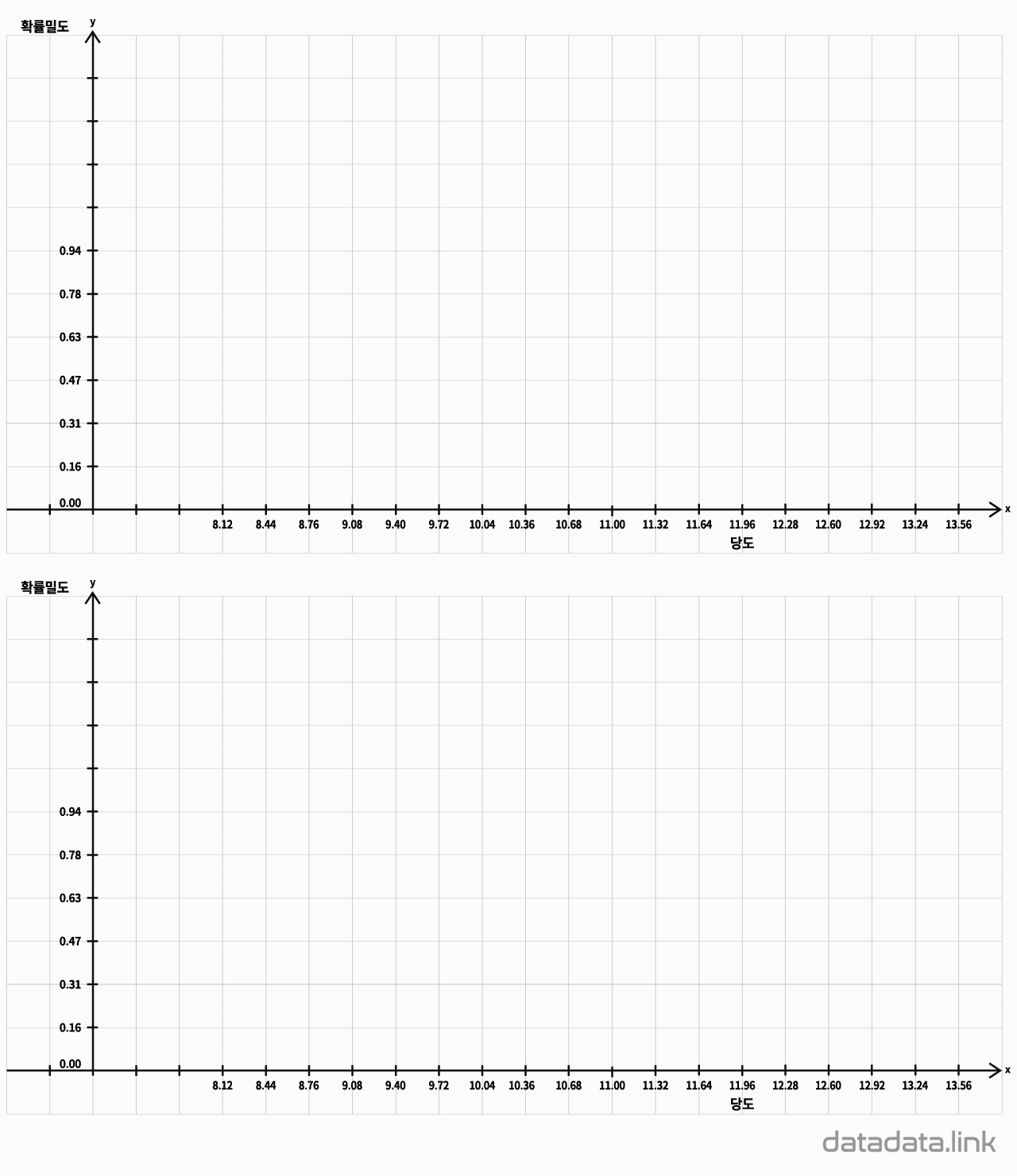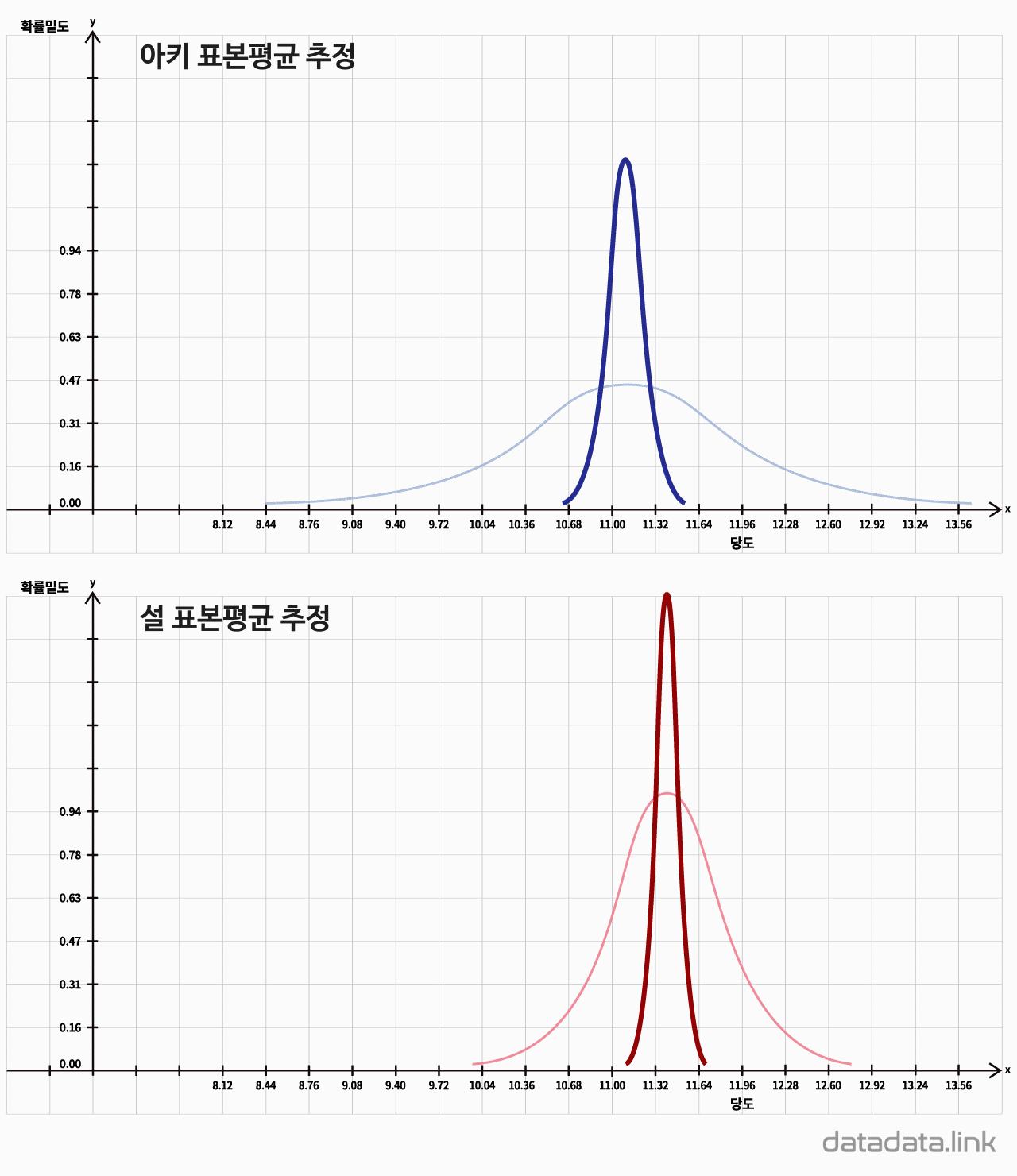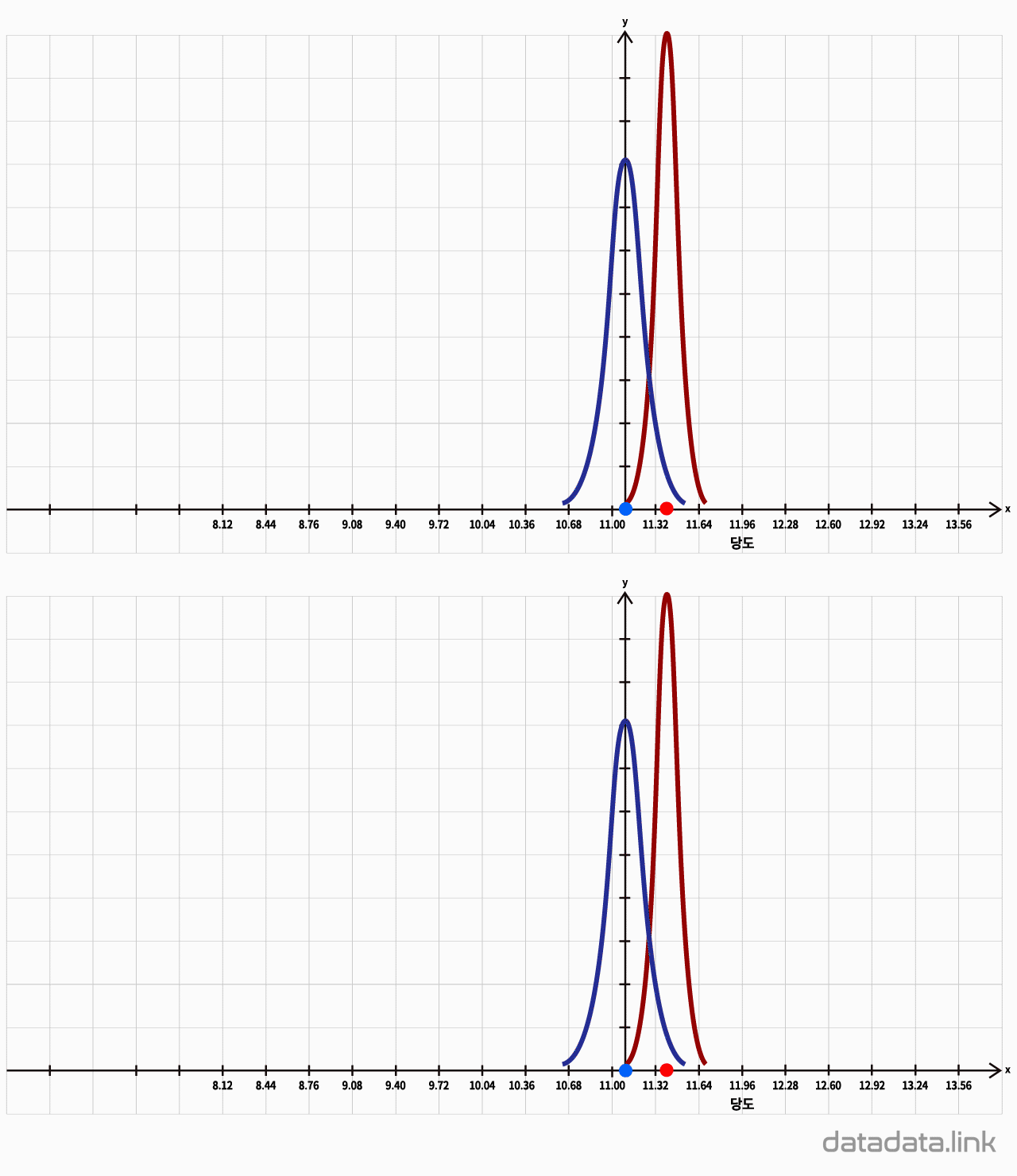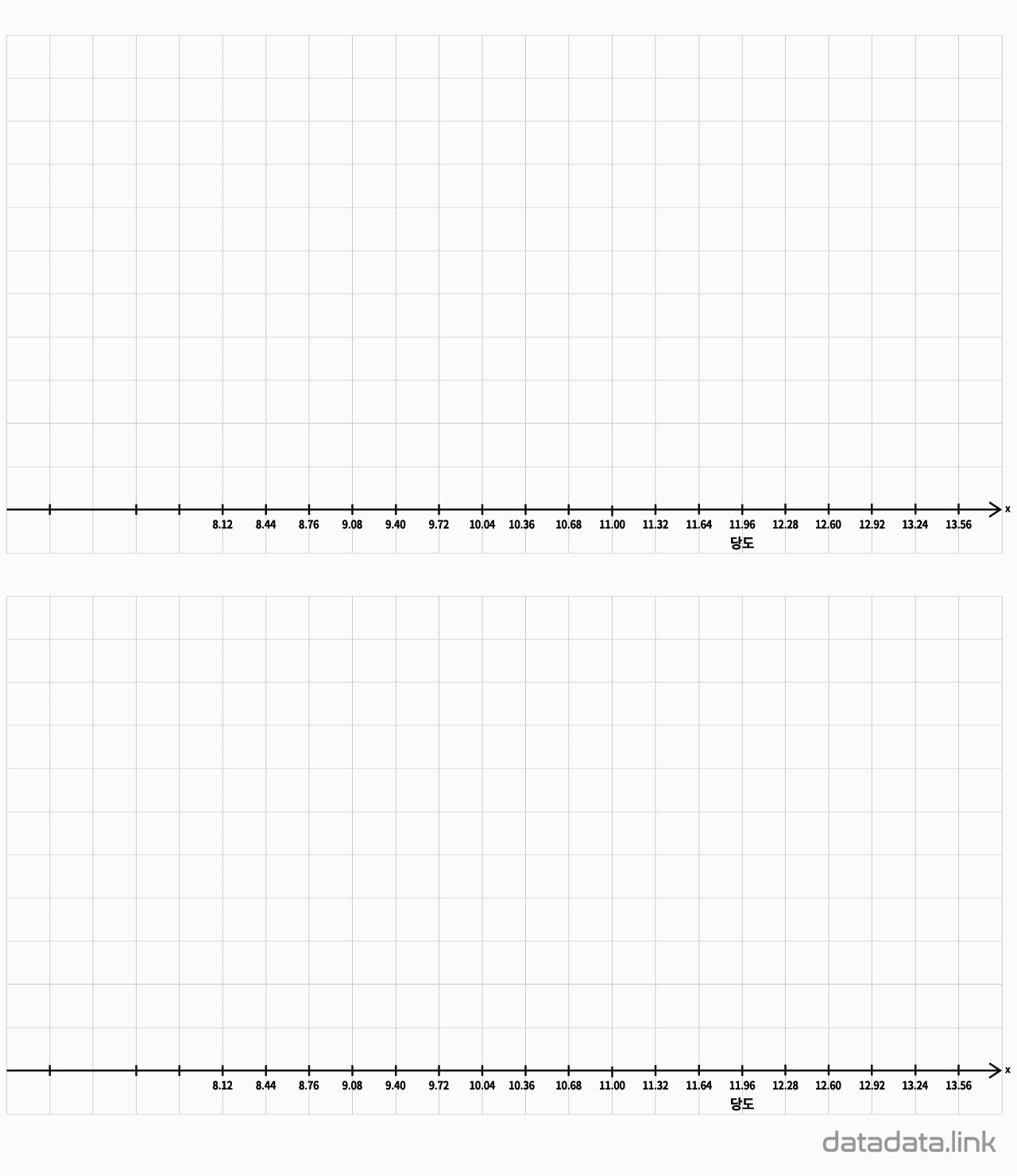
코로나백신 효과 시험은 어떻게 하나

표본추출
코로나 백신의 효과를 시험하기 위해서는 코로나백신을 접종한 사람들과 그렇지 않은 사람들을 비교하는 방법을 사용합니다.
우선 승인기관에서 요구하는 적당한 조건의 임상시험 참가자를 모집합니다. 참가자를 다시 코로나 백신을 접종한 사람들을 실험군, 코로나 백신을 접종하지 않은 사람들을 대조군으로 구분합니다. 그리고 접종 후 일정기간이 지난 후 코로나에 감염되는 인원을 조사합니다.
그런데, 대조군은 아무래도 실험군에 비해 코로나에 걸리지 않기 위해 더욱 조심할 것이므로, 실험군과 대조군을 동일한 조건에서 실험을 했다고 보기 어렵습니다.
따라서, 이러한 임상시험에서는 대조군에도 접종을 하게 되는데, 이는 항체형성에 전혀 도움이 되지 않는 가짜 약제로 하는 접종으로, 위약 또는 플라시보(placebo)라고 합니다.
다음으로 임상시험에 참여하는 참가자의 입장에서 내가 실험군 혹은 대조군에 속해있다는 것을 안다면, 이 또한 임상시험 결과에 영향을 미치게 됩니다. 만약, 나에게 접종을 하는 사람 혹은 나를 관찰하는 사람의 표정이나 몸짓으로부터 내가 실험군 혹은 대조군에 속해있다는 정보를 얻을 수 있다면, 이 또한 문제가 됩니다. 따라서, 임상시험에서는 참가자 뿐만 아니라 실험자에게도 누가 실험군이고 대조군인지, 그리고 어떤 약이 백신이고, 위약인지 정보를 공개하지 않는데, 이를 이중맹검(더블블라인드, double-blind)라고 합니다.
실험군과 대조군이 얼마나 공평하게 나누어져 있는가도 매우 중요한 문제입니다. 이 문제는 따로 다루겠습니다.