대표값 ?
Measure of central tendency ?
1.1. 편향성을 가지는 확률밀도함수와 그에 따른 평균, 중앙값, 최빈값
1.2. 회귀점 : 1차원 선형회귀
1.3. 회귀직선 : 2차원 선형회귀
1.4. 회귀평면 : 3차원 선형회귀
1. 애니메이션
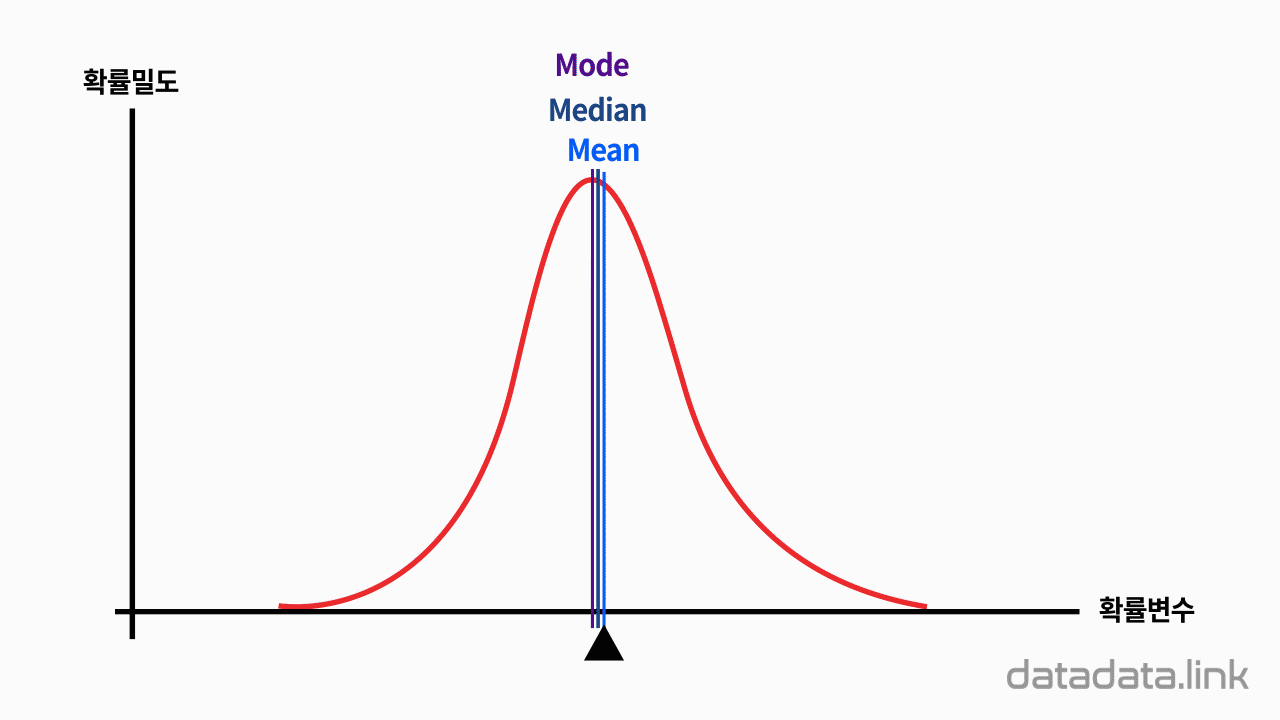
편향성을 가지는 확률밀도함수와 그에 따른 평균, 중앙값, 최빈값
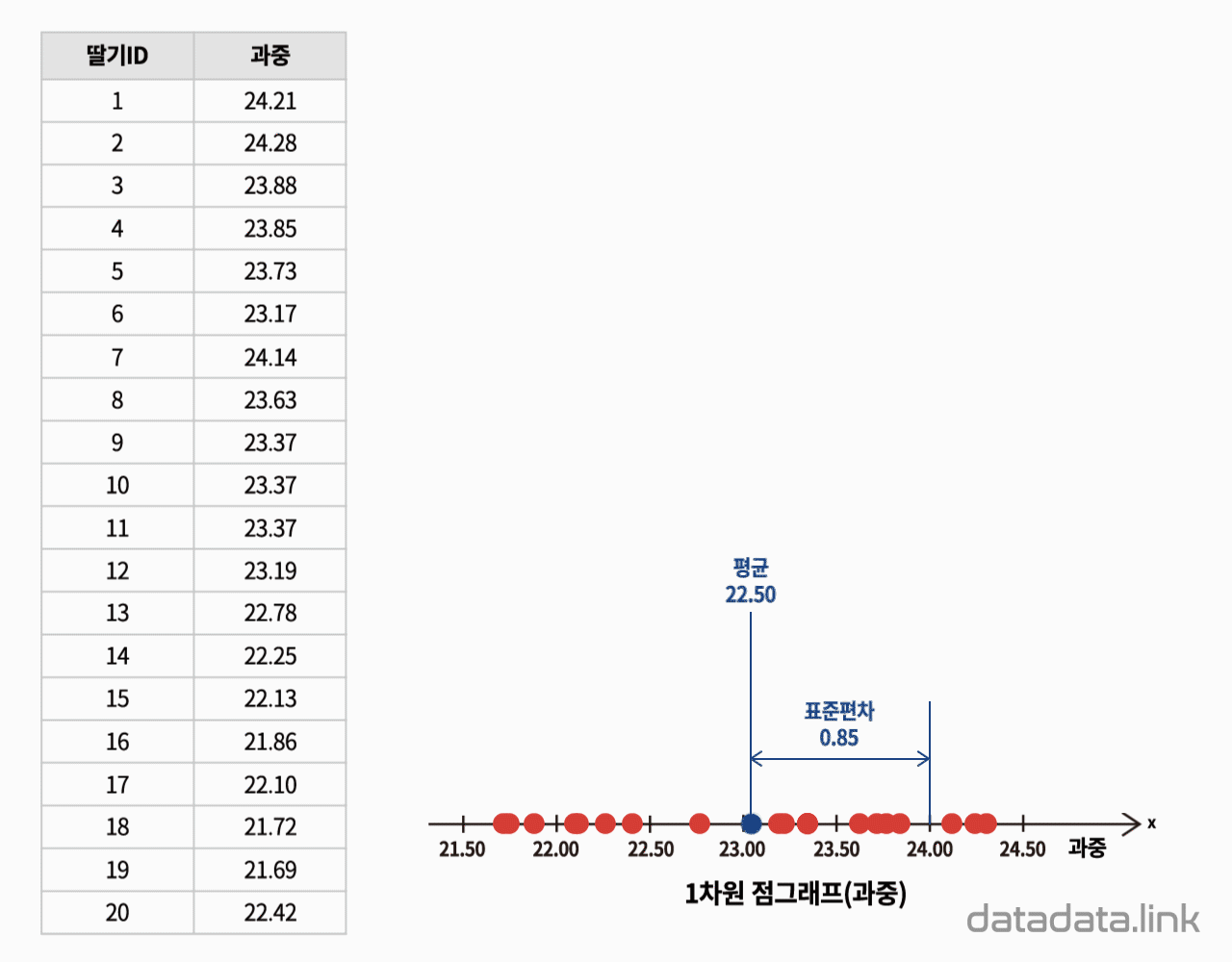
회귀점 : 1차원 선형회귀
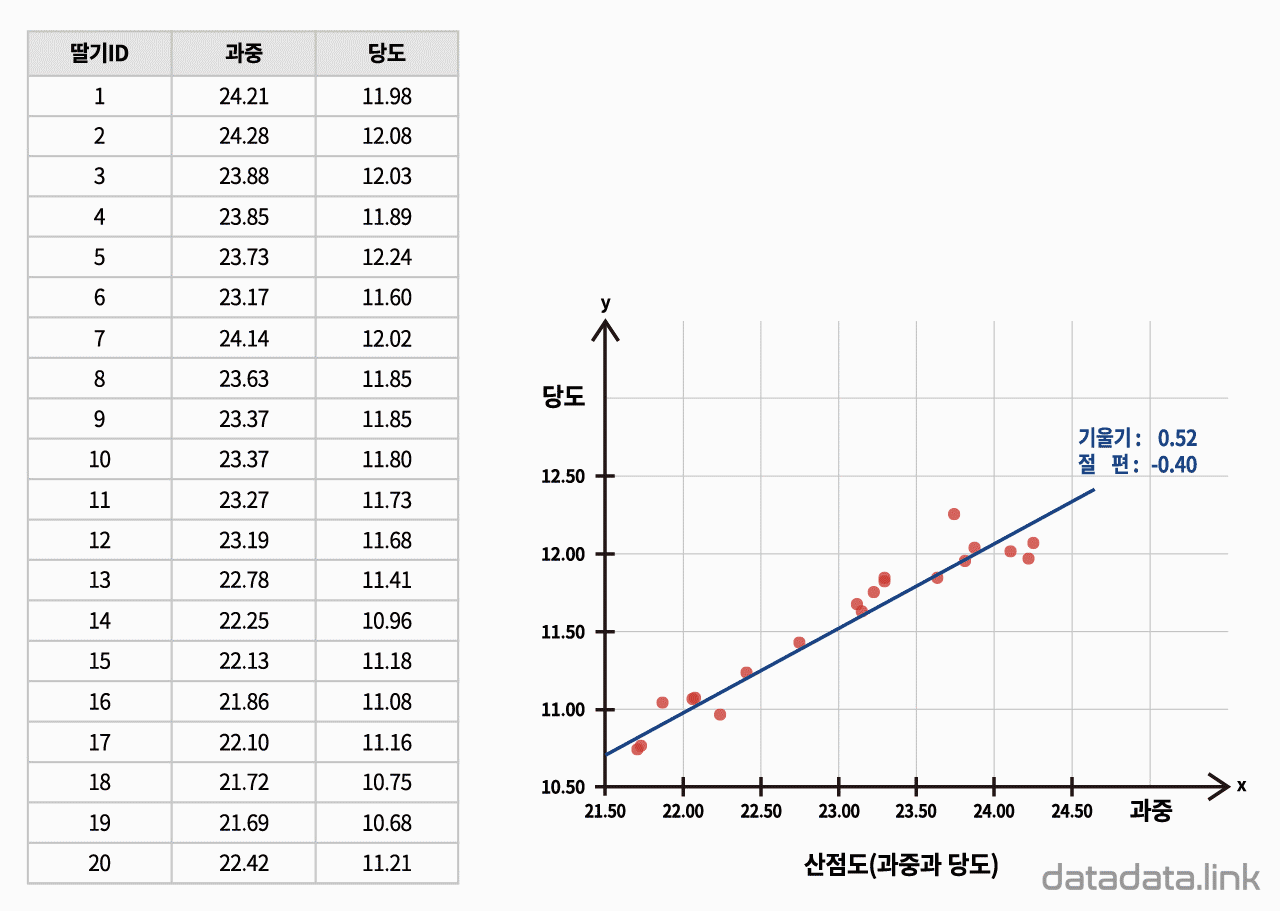
회귀직선 : 2차원 선형회귀
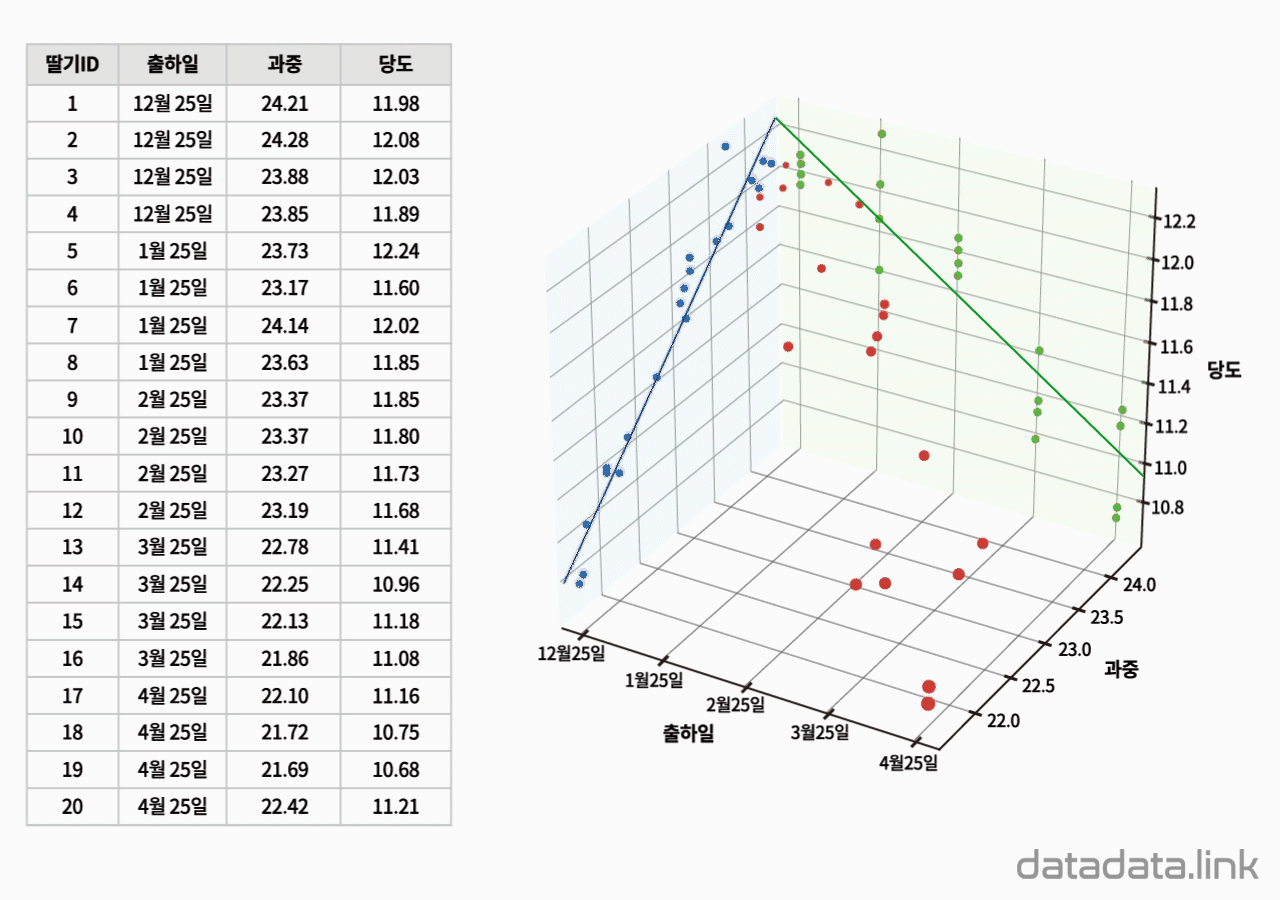
회귀평면 : 3차원 선형회귀
2. 설명
2.1. 데이터의 대표값
대표값은 값들의 무리(데이터)를 대표하는 값(representative value)입니다. 그리고 대표값은 데이터의 퍼짐정도를 나타내는 분포값(measure of dispersion)의 원점위치(measure of location)로 사용됩니다. 대표값에는 평균(mean), 중앙값(median), 최빈값(mode)이 있습니다.
중앙값(median)은 데이터를 크기 순서로 나열할 때 중앙에 놓이는 값입니다. 중앙값은 특별히 크거나 작은 변수값이 있는 경우에 왜곡이 심하지 않아 데이터의 대표값으로 많이 쓰입니다.
최빈값(mode)은 변수값 중 가장 빈도수가 큰 변수값입니다.
평균에는 산술평균, 가중평균 등이 있습니다. 평균은 중앙값과 비교하여 어느 한 변수값이 아주 크거나 작은 경우 왜곡이 나타납니다. 보통 평균이라고 하면 산술평균을 의미합니다. 가중평균(weighted mean)은 산술평균의 다른 변형형태로 각 변수값에 가중치를 곱하여 평균을 구합니다. 특별히 변수가 확률변수이고 가중치의 합이 1이 되면 가중평균은 기대값이 됩니다. 여기서 각 확률변수의 가중치는 그 확률변수의 확률이 됩니다.
애니메이션에서 가로축은 확률변수를, 세로축은 확률밀도함수값을 표시합니다. 애니메이션처럼 확률밀도함수가 정규분포를 이루면 평균, 중앙값, 최빈값은 같은 확률변수값을 가집니다. 그러나 편향이 일어날 경우 다른값을 가집니다.
평균은 무게중심을 나타내는 확률변수값입니다. 중앙값은 지나는 직선의 양쪽 면의 면적이 같은 확률변수값입니다. 최빈값은 확률밀도함수의 정점을 나타내는 확률변수값입니다.
2.3. 설명강의
– 준비 중

3. 실습
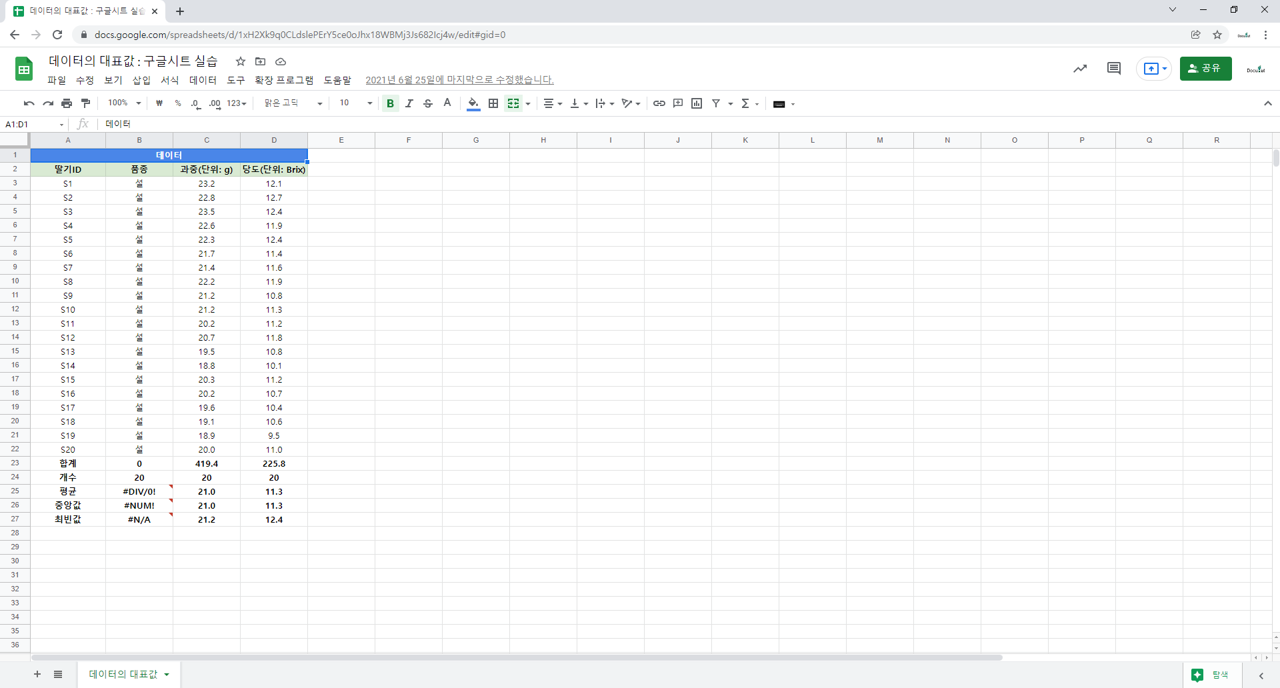
3.2. 함수
=SUM(B3:B22) : 합계. 셀의 합계 혹은 입력한 숫자의 합계를 계산해서 표시. B3와 B22의 범위에 있는 모든 숫자의 합계를 계산해서 표시.
=COUNTA(B3:B22) : 데이터 개수. 숫자와 텍스트로 표시된 모든 데이터의 개수를 표시함. B3에서 B22에 있는 모든 데이터의 개수를 표시함.
=COUNT(C3:C22) : 데이터 개수. 숫자로 표시된 데이터의 개수만 표시함. C3에서 C22에 있는 숫자로 표시된 데이터의 개수를 표시함.
=AVERAGE(B3:B22) : 평균. B3에서 B22에 있는 데이터의 평균을 구함. 데이터를 모두 더해서 개수로 나눔. 산술평균.
=MEDIAN(B3:B22) : 중앙값(중간값). B3에서 B22에 있는 모든 숫자의 중앙값을 표시함. 데이터의 개수가 짝수일 경우, 가운데 있는 두 수의 평균을 계산해서 표시함.
=MODE(B3:B22) : 최빈값. B3에서 B22에 있는 데이터 중 가장 자주 나오는 데이터.
3.3. 실습강의
– 데이터
– 평균
– 중앙값
– 최빈값
– 대표값 비교
4. 용어
4.1 용어
데이터
데이터는 질적 또는 양적 변수값의 집합입니다. 데이터와 정보 또는 지식은 종종 같은 의미로 사용하지만 데이터를 분석하면 정보가 된다고 볼 수 있습니다. 데이터는 일반적으로 연구의 결과물로 얻어집니다. 한편, 데이터는 경제(매출, 수익, 주가 등), 정부(예 : 범죄율, 실업률, 문맹율)와 비정부기구(예 : 노숙자 인구 조사)등 다양한 분야에서도 나타납니다. 그리고 데이터를 수집 및 분석하고 시각화할 수 있습니다.
일반적인 개념의 데이터는 응용이나 처리에 적합한 형태로 표현되거나 코딩됩니다. 원시 데이터 ( “정리되지 않은 데이터”)는 “정리”되기 전의 숫자 또는 문자의 모음입니다. 따라서 데이터의 오류를 제거하려면 원시 데이터에서 데이터를 수정해야 합니다. 데이터 정리는 일반적으로 단계별로 이루어지며 한 단계의 “정리 된 데이터”는 다음 단계의 “원시 데이터”가 됩니다. 현장 데이터는 자연적인 “현장”에서 수집되는 원시 데이터입니다. 실험 데이터는 관찰 및 기록을 통한 과학적 조사에서 생성되는 데이터입니다. 데이터는 디지털 경제의 새로운 자원입니다.
Reference
기대값
확률에서 임의 변수의 기대값은 직관적으로는 동일한 실험을 무한 반복했을 때 나온 값들의 평균값입니다. 예를 들어, 6면 주사위를 던지는 시행의 기대값은던진 횟수가 무한대에 가까워졌을 때의 결과값들의 평균값(이경우는 3.5)이 됩니다. 다시 말해, 큰 수의 법칙은 반복 횟수가 무한대에 가까워질수록 값의 산술평균은 기대값에 점점 수렴한다는 것을 의미합니다. 이 기대값은 기대치, 수학적 기대치, EV, 평균, 평균값이라고도 불립니다.
보다 현실적으로, 이산확률변수의 기대값은 모든 가능한 값의 가중평균입니다. 즉, 기대값은 확률변수가 취할 수 있는 각 값에 발생확률을 곱한 결과값들의 합이 됩니다. 연속적인 확률변수에 대해서는 합계 대신에 변수의 적분이 들어간다는 것 외에는 동일한 원칙이 적용됩니다. 공식적인 정의는 이 둘을 모두 포함해 이산적이거나 완전히 연속적이지 않은 분포에서도 같게 작용되어, 확률변수의 기대값은 간단히 “확률 측정값에 대한 변수의 적분 값”으로도 말할 수 있습니다.
기대값은 큰 꼬리가 있는 분포(예를 들어 Caushy 분포)에서는 존재하지 않습니다. 이런 무작위 변수의 경우에는 분포의 긴 꼬리가 합이나 적분값이 수렴하지 못하도록 합니다. 기대값은 위치 매개 변수의 한 유형으로 사용할 수 있기 때문에 확률 분포를 특징 짓는데 중요한 역할을 합니다. 그에 반해, 분산은 기대값 주위의 확률변수의 가능한 값들이 얼마나 퍼져 있는 지를 나타내는 값입니다. 분산은 크게 2가지 방법으로 구할 수 있습니다. 모든 값에 평균을 빼고 제곱을 해 평균을 구하거나, 모든 값의 제곱의 평균에 평균의 제곱을 빼서 구할 수 있습니다.
Reference
산술평균
확률과 통계에서 데이터의 평균은 보통 산술평균을 의미합니다. 산술평균 (기대값)은 중심값으로서 데이터 값의 합을 데이터 수로 나눈 값입니다. 숫자 집합 x1, x2, …, xn의 산술평균은 일반적으로 “엑스 바(X bar)”라고 발음되는 $\bar {X}$로 표시됩니다. 집단의 모평균($\mu$ 또는 $\mu_{X}$로 표시)은 “뮤”라고 발음합니다. 집단에서 추출하여 얻은 여러 개의 표본의 산술평균을 집단의 표본평균 ($\bar {X}$)의 표집(Sample distribution)이라고 부릅니다.
확률 및 통계에서 집단의 모평균(기대값)은 확률분포 또는 그 분포로 특정되는 확률변수의 중심을 표현하는 대표적인 척도입니다. 확률변수 $X$의 이산확률분포의 경우, 평균은 그 값의 확률로 가중치화된 모든 값의 합과 동일합니다. 즉, $X$의 가능한 값 $x$와 그 확률$p (x)$의 곱을 취한 다음 이들을 모두 합하여 구합니다. $ \mu = \sum xp(x)$. 연속확률 분포의 경우에도 유사한 공식이 적용됩니다. 예를 들어, 구성원의 평균 키는 모든 구성원의 키를 합하여 전체 개체 수로 나눈 값과 같습니다. 모든 확률분포에 정의된 평균이 있는 것은 아닙니다. 예를 들어 Cauchy 분포입니다.
집단의 표본평균은 집단의 모평균과 다를 수 있으며, 특히 표본크기가 작을수록 집단의 표본평균과 모평균은 다를 가능성이 높아집니다. 큰 수의 법칙은 표본의 크기가 클수록 집단의 표본평균이 집단의 모평균에 가까울 확률이 높다는 것을 나타냅니다.
Reference
가중평균
가중평균은 일반적인 산술평균(가장 일반적인 유형의 평균)과 비슷하지만 각 데이터 값이 평균에 동등하게 기여하지 않고 일부 데이터 값이 다른 값보다 더 많은 기여를 한다는 점이 다릅니다. 가중평균의 개념은 설명통계(기술통계)에서 사용되며 수학의 다른 영역보다 더 일반적인 형태로도 사용됩니다.
모든 가중치가 같다면 가중평균과 산술평균은 같습니다. 가중평균은 보통 산술평균과 비슷하게 작동하지만 Simpson의 역설에서 보이는 것과 같이 직관적이지 않은 속성도 있습니다.
Reference
weighted arithmetic mean – Wikipedia
증앙값
중앙값은 데이터세트(유한집단 또는 표본 또는 이산확률분포)의 하반부와 상반부를 분리하는 값이며 “중간”값으로 간주 될 수 있습니다. 예를 들어, 데이터세트 {1, 3, 6, 7, 8, 9}에서 중앙값은 데이터 집합에서 네 번째로 크고 네 번째로 작은 숫자입니다. 연속적인 확률분포의 경우, 중앙값은 숫자가 상반부 또는 하반부로 정해질 가능성이 같은 값입니다. 중앙값은 통계 및 확률 이론에서 데이터 집합의 속성에 일반적으로 사용되는 척도입니다.
데이터를 요약하거나 설명할 때, 평균에 비해 중앙값의 좋은 점은 매우 크거나 작은 값으로 데이터의 대표값이 왜곡되지 않으므로 더 나은 대표성을 제공 할 수 있습니다, 예를 들어, 평균가계소득이나 평균자산과 같은 통계량을 이해할 때 적은 수의 매우 크거나 작은 데이터로 인해 평균은 극단적으로 왜곡 될 수 있습니다.반면에 가계소득의 중앙값은 “전형적인”수입이 무엇인지를 제시하는 더 좋은 방법 일 수 있습니다.이 때문에 중앙값은 중요한 통계에서 가장 신뢰할 만한 대표값이며 50 %의 분해점을 갖는 가장 믿을 만한 통계량이므로 데이터의 절반 이상이 실제와 다르지 않는 한 중앙값은 크게 달라지지 않습니다.
Reference
가중중앙값
통계에서 표본(Sample)의 가중중앙값은 50% 가중 백분위 수입니다. 이것은 1988년에 F.Y.Edgeworth에 의해 처음 만들어졌습니다. 중앙값과 마찬가지로 중심 경향을 예상하는데 유용하며, 이상치에 더욱 근접합니다. 이것은 균일적이지 않은 통계적 무게(표본에서의 다양한 정밀도 측정)를 표현 가능하게 합니다.