표본추출 ?
Sampling ?
1. 애니메이션
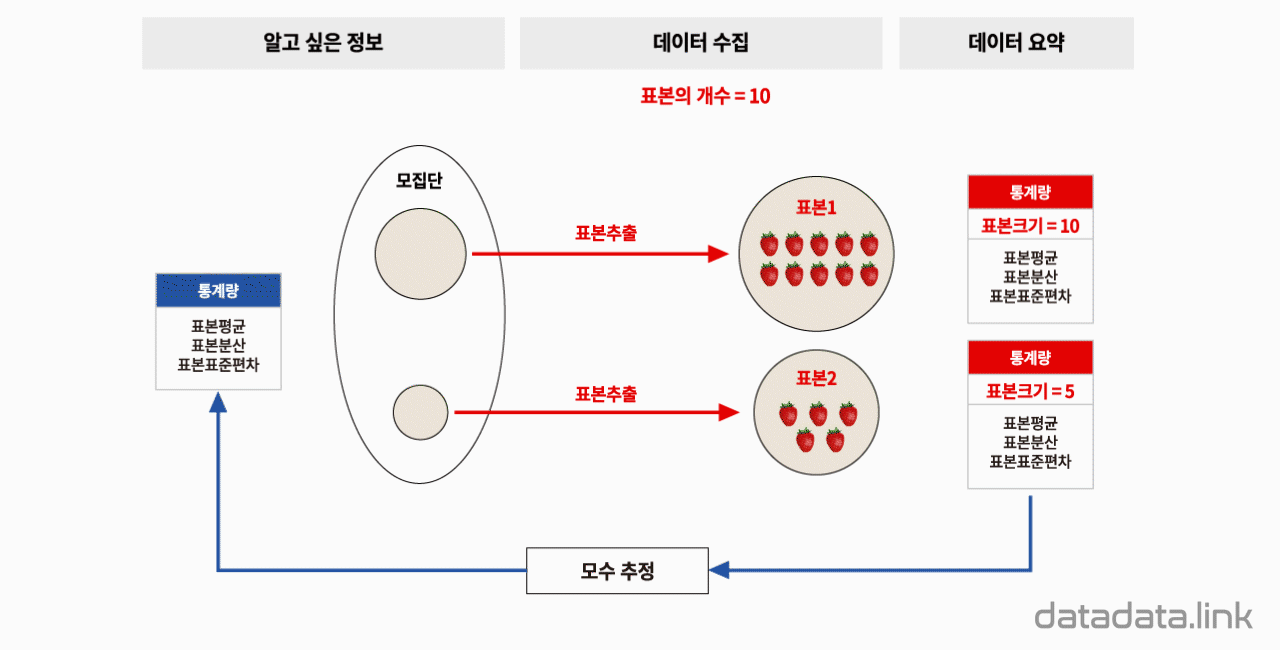

표본추출과 표본통계량
표본으로 모집단을 추측하여 중재효과 검정
2. 설명
2.1. 표본추출(Sampling)
표본데이터(표본자료)를 이용하여 모집단의 특성을 추론하기 위해서 표본을 뽑아야 하는데 이것을 표본추출(Sampling)이라 합니다.
표본추출(Sampling)시 고려사항
| 항목 | 고려사항 | |
| 모집단과 표본 | 대부분의 모집단은 개체 수가 많아서 모집단 전체를 관측 하는 것(전수 조사)이 불가능하거나 비경제적, 비효율적이므로 모집단에서 표본을 추출하여 모집단을 추측 | |
| 표본데이터 | 표본은 모집단의 특성에 대하여 완전한 정보를 가지고 있지 않으므로 추출된 표본에 의한 모집단의 추정정보는 다름, 따라서, 표본크기가 크고 표본데이터의 정확성이 높아야 함. | |
| 표본크기 | 표본크기가 크면 모집단을 잘 대표할 수 있지만 표본추출의 경제성, 신속성, 가능성, 정확성 등을 고려하여 표본크기를 정함. 반면, 표본크기가 작으면 모집단을 대표하는 것이 어려움. 표본크기의 결정요인은 연구 과제의 유형 및 목적, 표본오차의 크기, 시간 제약, 비용 제약, 선행 연구 등이 있음. | |
| 표본오차 | 표본오차는 표본관측을 통해 추정한 결과와 모집단 전체를 조사할 때 얻게 될 결과의 차이. 표본오차의 오차한계는 표본오차의 최대허용값 | |
2.2 모집단크기와 표본크기
표본을 추출한다는 것은 모집단(population)이 존재한다는 것을 의미합니다. 표본추출(sampling)의 가장 큰 목적은 추출한 표본을 통하여 모집단을 추측하기 위함입니다. 쉽게 생각하면, 알고 싶은 정보를 얻기 위하여 데이터를 수집하는 것입니다.
표본의 크기가 클 수록 모집단에 가까워지므로 표본크기는 모집단을 추측하는에 있어 정확성과 관계된 매우 중요한 표본통계량입니다. 하지만 실제에서는 표본의 크기를 늘리면 비용이 늘어나는 등의 여러가지 어려움이 있습니다. 표본의 크기가 충분히 크면 표본의 속성을 모집단의 속성으로 볼 수 있습니다. 표본크기가 충분히 크다는 것을 표현하는 방법에는 표본의 크기와 모집단의 크기의 비로 표현하는 방법과 표본크기가 특정숫자(예를들면 30)보다 크다고 표현하는 방법이 있습니다. 표본의 크기가 커지면, 표본평균을 모평균으로 추정할 때 정확성이 증대되고 표본분산을 모분산으로 추정할 때도 마찬가지입니다. 그리고 데이터수집에 사용할 수 있는 리소스가 고정되어 있다면 표본추출의 횟수와 표본의 크기를 결정함에 있어 리소스투입에 대한 성과에 대한 고려를 해야 합니다. 따라서 표본추출의 횟수와 표본의 크기는 중요한 실험설계의 요소입니다.
통계조사의 대상이 되는 집단, 즉, 모집단은 일반적으로 아주 큽니다. 그러므로, 전체 모집단을 모두 조사하는 것은 엄청난 비용과 시간을 필요로 합니다. 그래서 모집단의 일부를 추출한 표본을 이용하여 전체 모집단의 속성을 예측하고 있으며 이를 추측통계(inferential statistics)라 합니다. 그러나 모집단크기와 표본크기가 크게 다르므로 모집단 관측결과와 표본의 관측결과는 차이가 있을 수 있습니다. 이러한 차이를 줄이기 위해 표본의 여러 가지 추출 방법이 연구되어 왔습니다. 모집단에서 표본을 추출하는 방법에는 다음과 같은 것들이 있습니다.
– 단순임의추출법
– 집락추출법
– 층화무작위추출법
2.3. 표본추출법
간단한 표본추출에는 다음의 세가지 방법이 있습니다.
단순임의추출법(단순무작위추출법, Simple Random Sampling)
단순임의추출법(Simple Random Sampling)은 $n$개의 개체를 모집단으로부터 무작위(임의)로 추출하는 방법입니다. 즉, 단순임의추출법은 모집단의 모든 원소가 표본으로 뽑힐 확률이 같도록 표본을 추출하는 방법입니다. 단순확률추출법이라 부르기도 합니다.
모집단의 각 개체들은 추출될 가능성이 동일하다고 “가정”하며, 모집단이 큰 경우에 정확한 무작위 추출이 어려울 수 있는 단점이 존재합니다.
단순임의 표본추출 시 한번 추출한 원소를 다시 모집단에 포함시키는 복원추출(with replacement )이나, 추출된 원소를 다시 모집단에 넣지 않는 비복원추출(without replacement)도 가능합니다. 그러나 실제 거의 모든 표본추출은 비복원추출로 이루어집니다.
표본추출시 모집단의 각 원소가 표본으로 뽑힐 확률이 같도록 하려면 어떠한 수단이 필요한데 예전에는 난수표(random number table)를 많이 사용하였습니다. 난수표란, 0에서 9까지의 숫자를 특별한 규칙성이나 편중성이 없이 흩어 놓은 표입니다. 요즘에는 컴퓨터로 [0, 1] 균등분포를 이용한 난수 생성을 주로 활용합니다.
집락추출법(Cluster Sampling)
집락추출법(cluster sampling)은 먼저 모집단을 여러 개의 작은 집단으로 구분하는 집락(cluster)을 하고, 몇 개의 집락을 무작위 추출하여, 추출된 집락에서 단순무작위추출법을 실시하는 방법입니다. 집락(cluster)은 조밀하게 모여 있는 개체(예를 들면, 사람, 동물 등)의 무리라는 뜻입니다.
층화무작위추출법(Stratified Random Sampling)
계층(stratum)은 사전적으로 사회 계층. 암석층, 지층, 단층을 의미하며 층화(stratify)는 층을 이루게 함을 의미합니다. 층화(Stratified)는 계층화된 상태를 의미합니다. 층화무작위추출법(Stratified Random Sampling)은 모집단을 성질이 비슷한 개체들로 구성된 몇 개의 층(stratum) 으로 구분하고 각 층에서 단순무작위추출법을 실시하는 표본추출 방법입니다.
2.4. 표본(Sample)의 통계량(Statistic)
표본은 모집단으로부터 표본추출한 결과입니다. 따라서, 표본은 모집단으로부터 추출된 개체들의 집합입니다. 표본의 예로는 학교의 수학적 창의력을 추측하기 위하여 전교에서 무작위로 선발된 학년과 반이 있을 수 있습니다. 표본의 크기는 표본을 구성하는 개체들의 수이며 일반적으로 알파벳 소문자 $n$을 사용합니다. 개체의 예로는 반을 구성하는 학생이 있을 수 있습니다. 모집단의 평균와 분산은 변하지 않는 상수입니다. 모집단에 추출한 표본의 평균과 분산은 표본을 추출할 때마다 변하는 변수(Variable)입니다. 더 나아가 표본평균은 확률분포를 가지는 확률변수이며 중심극한정리에 따르면 표본크기가 커짐에 따라 정규분포로 수렴하는 종모양의 확률분포를 가집니다. 마찬가지로 표본분산도 확률변수이며 표본크기에 따라 달라지는 확률분포를 가집니다. 표본의 관측값으로 구하는 표본크기와 표본평균과 표본분산 등을 표본의 통계량(Statistic)이라고 합니다.
표본평균의 식
$$\bar{X}=\dfrac{1}{n}(x_1+x_2+\cdots+x_n)=\dfrac{1}{n}\sum_{i=1}^{n}x_i$$
표본분산의 식
$$s^2=\dfrac{\sum\limits_{i=1}^{n}(x_i-\bar{x})^2}{n-1}$$
3. 실습
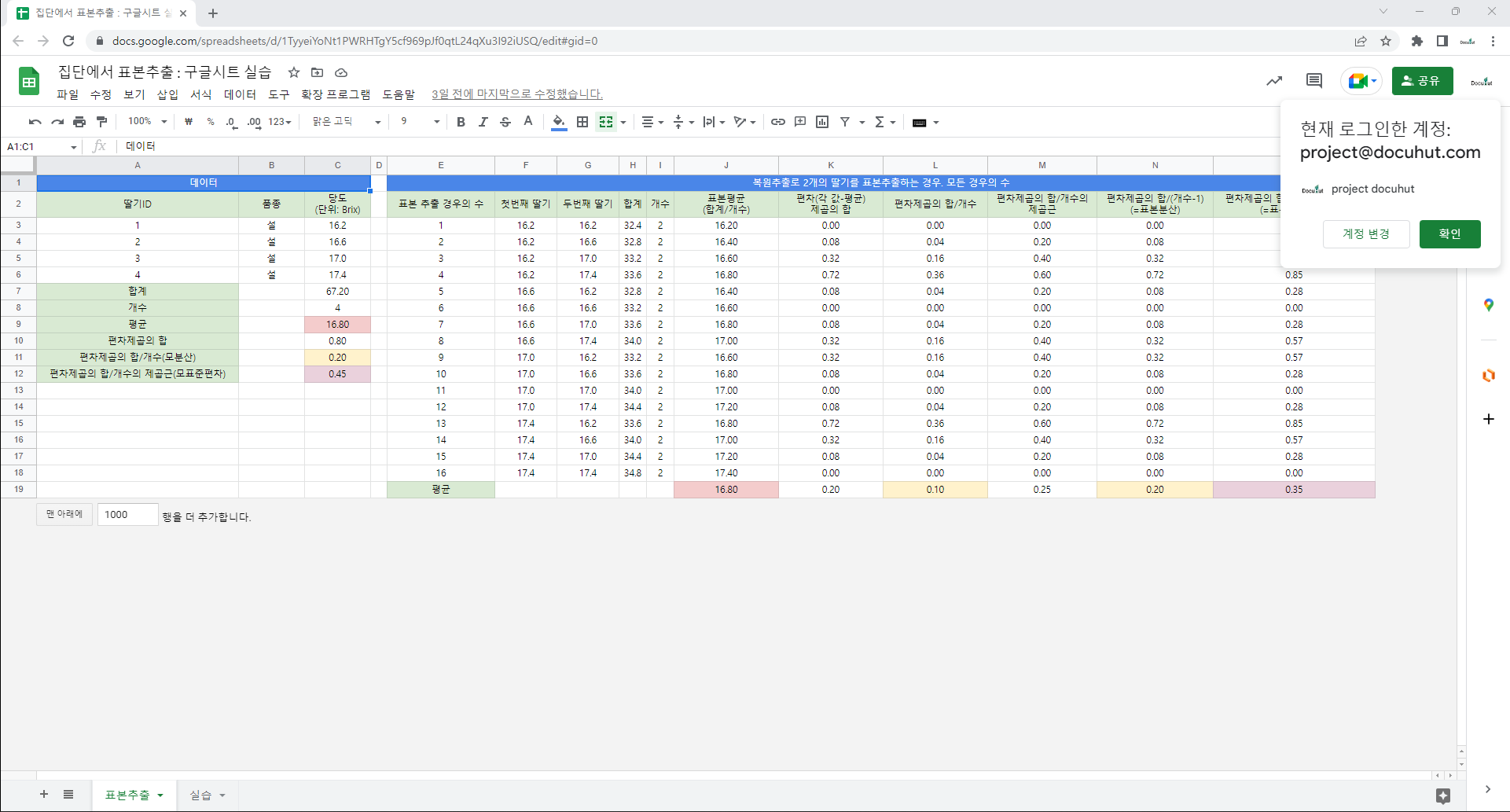
3.2. 함수
=ROWS(F2:F2) : 지정된 배열 또는 범위에 있는 행의 개수.
3.3. 실습강의
– 데이터
– 데이터 요약
– 표본추출
– 표본통계량
– 표본통계량의 평균
– 모수와 표본통계량의 평균 비교
4 참조
4.1 용어
표본추출(sampling)
통계, 품질보증 및 조사방법론에서 표본추출은 모집단(통계의 대상이 되는 집단)의 특성을 추정하기 위해 모집단 내에서 하위집합(통계표본)을 선택하는 것입니다. 통계학자들은 표본을 통해 모집단을 표현하기 위해 연구합니다. 표본추출의 2가지 장점은 전수조사에 비해 비용이 저렴하고 데이터수집이 빠르다는 것입니다.
각 관측값(관측치)은 관측이 가능한 독립개체 또는 개인이나 구분될 수 있는 대상의 하나 이상의 속성(예를 들어 무게, 위치, 색)을 관측(관찰, 측정)한 것입니다.
측량 표본추출(survey sampling), 특히 층화 표본추출(stratified sampling)에서 설계된 표본을 조정하기 위해 가중치를 적용할 수 있습니다. 확률이론과 통계의 결과는 실험을 조정하는데 사용됩니다. 비즈니스 및 의학연구에서 표본추출은 집단에 대한 정보를 모으는데 널리 쓰입니다. 채택 표본추출(acceptance sampling)은 생산제품이 관리사양을 충족시키는지를 결정하는데 사용됩니다.
Reference
Sampling (statistics) – Wikipedia