회귀분석이란
회귀선과 잔차
1800년대 후반 유전학자 프랜시스 골턴은 아들들의 키는 아버지들의 키를 닮아가는 것과 함께 사람들의 평균키가 구심점으로 작동한다는 것을 알게 되었습니다.
이 현상을 골턴은 “평범으로의 회귀(regression toward mediocrity)”라고 칭하였습니다.
1970년대 이후 컴퓨터의 발달은 두 변수사이의 상관분석을 용이하게 만들었습니다.
그리고 현대에서는 상관을 분석하는 것을 회귀분석(regression analysis)이라고 부르고 있습니다.
두개 이상의 독립변수(설명변수, 예측변수)를 가지고 자연현상이나 사회현상을 예측하는 경우를 다중선형회귀분석(mulitiple linear regression analysis)이라고 합니다.
반면, 하나의 독립변수만 다루는 경우를 단순선형회귀분석(simple linear regression analysis)이라합니다.
단순선형회귀모델(simple linear regression model)을 만들어 보면
딸기의 과중(설명변수)과 당도(반응변수)
학생의 키(설명변수)와 몸무게(반응변수)
인간의 혈압(설명변수)과 기대수명(반응변수)
여기서 “딸기”, “학생”, “인간”으로 명명된 요소들은 2가지의 변수를 가지고 있다고 볼 수 있습니다.
이 변수의 관계를 모델링하여 하나의 변수를 가지고 다른 변수를 예측합니다.
여기서 중요한 것은 분석을 위하여 반응변수는 확률변수로 규정하여야 한다는 것입니다.
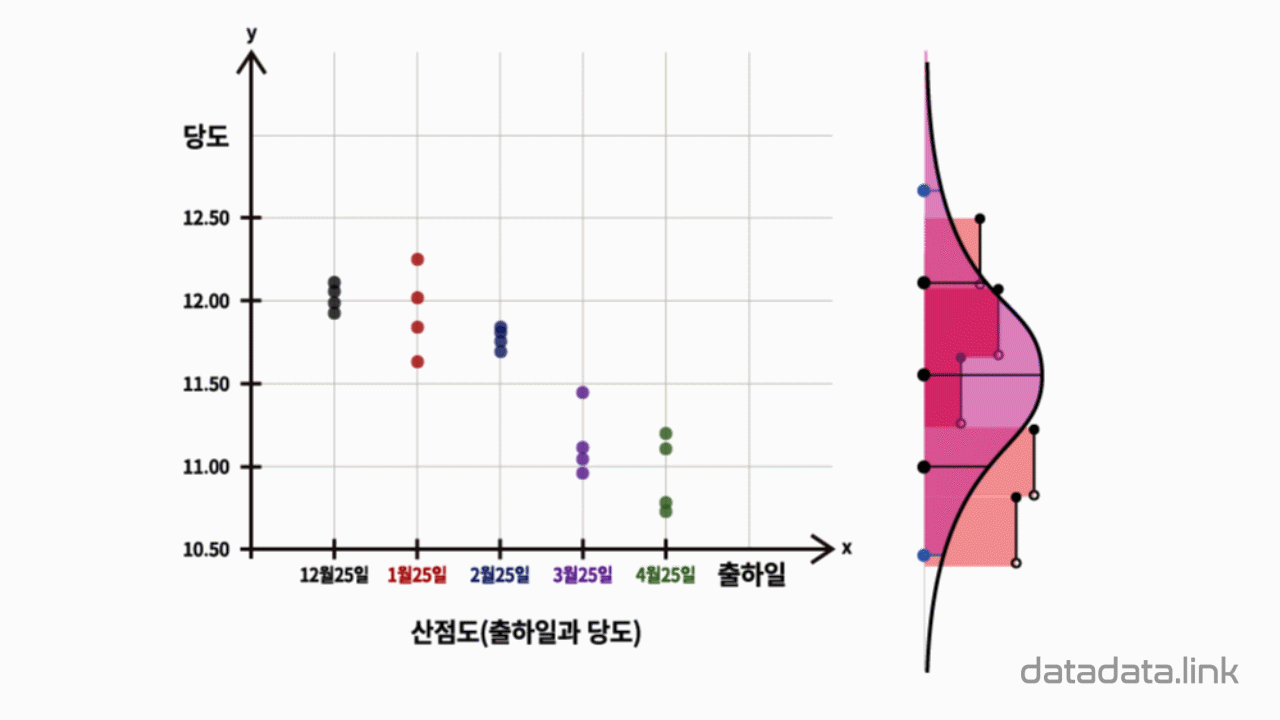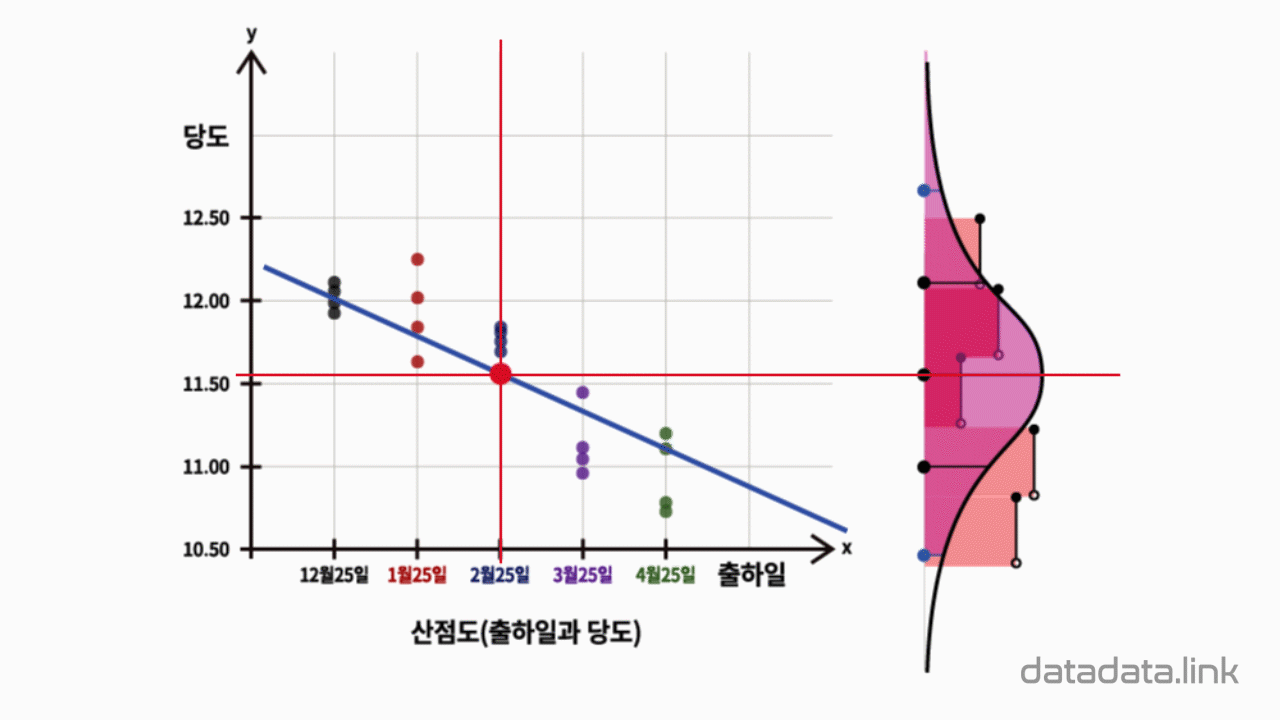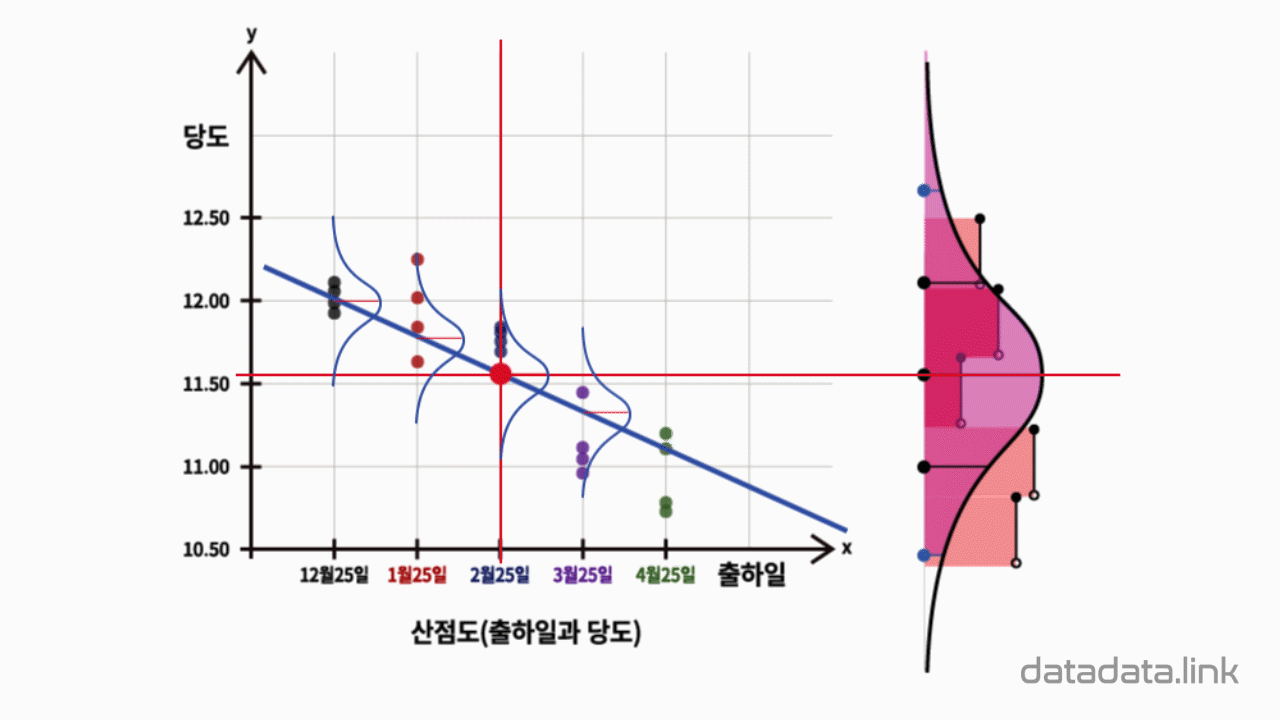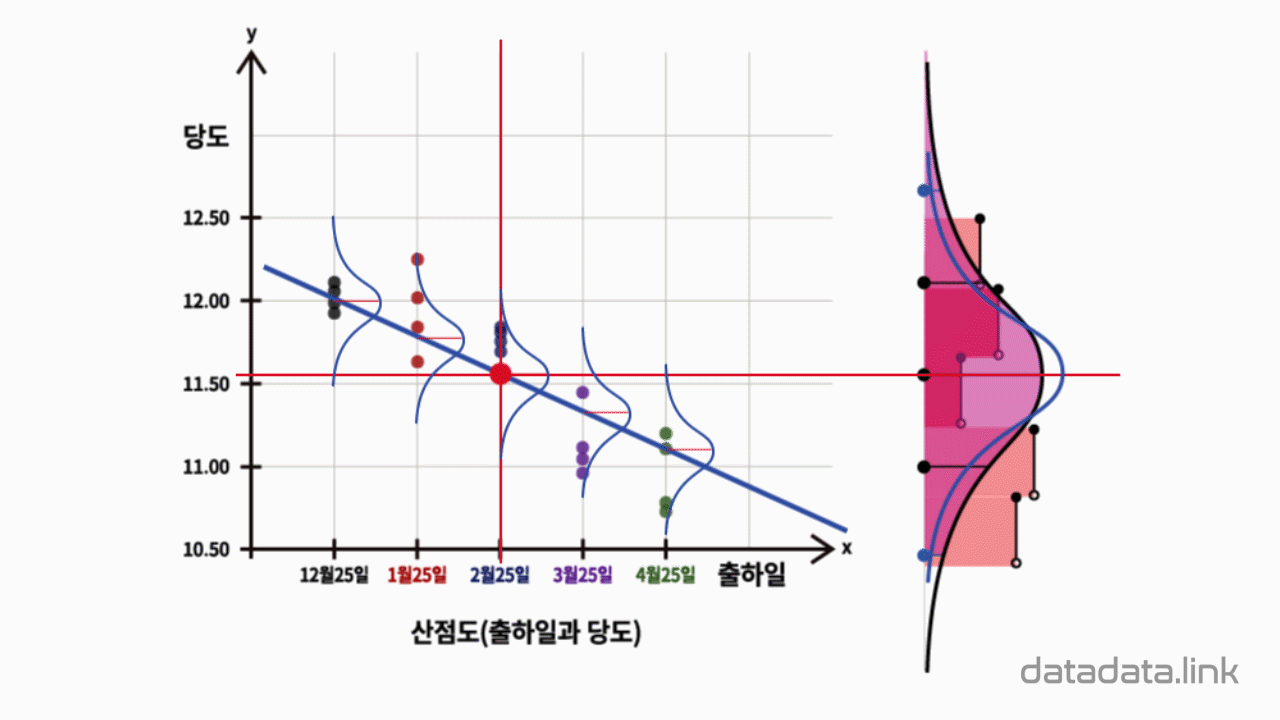
딸기의 당도를 Y좌표로 과중을 X좌표로 하는 딸기의 점(Point)들을 표시해 봅니다.
여기서 당도를 종속변수(반응변수)라하고 과중을 독립변수(설명변수, 예측변수)라합니다.
즉. (x, y)를 가지는 점을 2차원 좌표계에 나타냅니다. 이를 산점도(Scatter plot)라 합니다.
점들이 한 직선에 모이는 경향을 보이고 그 직선의 식을 추정한다면 딸기의 과중을 보고 당도를 예측할 수 있게 됩니다.
더 나아가 예측의 정확도도 제시할 수 있습니다.
이러한 예측을 위해서 산점도에서 주로 컴퓨터를 이용하여 회귀선을 구합니다.
직선상의 점들을 대표하는 것은 평균이 있습니다.
대응하여 평면상의 점들을 대표하는 것은 회귀선이라고 할 수 있습니다.
한편, 직선상에서 평균과의 거리를 나타내는 편차는 회귀모델에서는 무엇일까요.
회귀선이 평균과 같은 역할을 하므로 회귀모델에서는 회귀선에서 Y축방향의 편차인 잔차(residual)입니다.