| 성숙일 $(^2x)$ |
$$^2X \sim N(\mu_{^2X}, \sigma_{^2X}^2) $$
여기서, $^2X$는 성숙일: 성숙일은 0과 양의 실수
$\mu_{^2X}$는 성숙일의 모평균
$\sigma_{^2X}^2$은 성숙일의 모분산
$^2X_i$, $i$는 출하연속월수
출하연속월수는 각각 1=12월, 2=다음해 1월, 3=다음해 2월, 4=다음해 3월, 5=다음해 4월 |
${^2X} \sim N(36, 2^2)$
위의 정규분포를 5개의 구간으로 나누어 각 구간의 누적확률밀도로 수준(level)의 크기를 정하고 각 구간의 중앙값을 수준(level)의 값으로 정함.
$P({^2X} = {^2x_i}) =
\begin{cases}
P(X \leq -1.5) = \displaystyle \int_{-\infty}^{-1.5} \frac{1}{\sqrt{2\pi}} e^{-\frac{x^2}{2}} \, dx \approx 0.0668 & \text{if } {^2x_1} = 40 \\
P(-1.5 \leq X \leq -0.5) = \displaystyle \int_{-1.5}^{-0.5} \frac{1}{\sqrt{2\pi}} e^{-\frac{x^2}{2}} \, dx \approx 0.2417 & \text{if } {^2x_2} = 38 \\
P(-0.5 \leq X \leq 0.5) = \displaystyle \int_{-0.5}^{0.5} \frac{1}{\sqrt{2\pi}} e^{-\frac{x^2}{2}} \, dx \approx 0.3829 & \text{if } {^2x_3} = 36 \\
P(0.5 \leq X \leq 1.5) = \displaystyle \int_{0.5}^{1.5} \frac{1}{\sqrt{2\pi}} e^{-\frac{x^2}{2}} \, dx \approx 0.2417 & \text{if } {^2x_4} = 34 \\
P(1.5 \leq X) = \displaystyle \int_{1.5}^{\infty} \frac{1}{\sqrt{2\pi}} e^{-\frac{x^2}{2}} \, dx \approx 0.0668 & \text{if } {^2x_5} = 32 \\
\end{cases}$ |
| 저온숙성 $(^3x)$ |
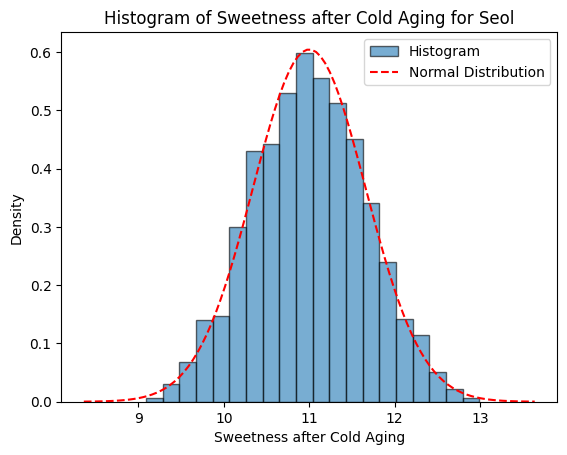
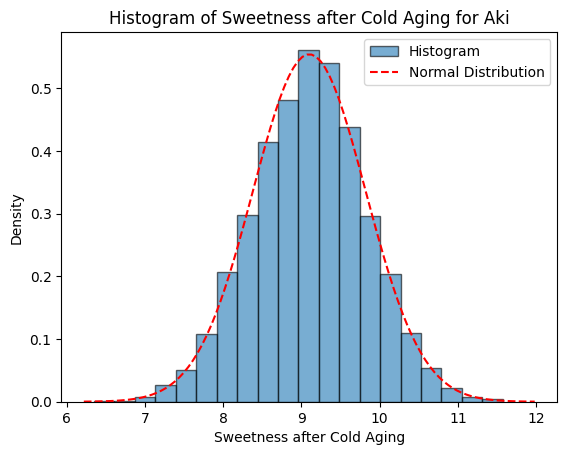
$${^1y}_{2}={^1y}_{1}+\bar{D}+\epsilon_{D}$$
여기서, ${^1y}_{2}$는 저온숙성 후 개체의 당도
${^1y}_{1}$은 저온숙성 전 개체의 당도
$D$는 저온숙성 전후 당도차이이며 확률변수: $d={^1y}_{2}-{^1y}_{1}$, $D=\bar{D}+\epsilon_{D}$
$\bar{D}$는 저온숙성으로 인한 당도변화의 평균
$\epsilon_{D}$는 오차항이며 평균이 0이고 분산이 $\sigma_{D}^2$인 정규분포를 나타냄: $\epsilon_{D} \sim N(0, \sigma_{D}^2) $
|
$\bar{_1D}=0.20$
$\epsilon_{_1D} \sim N(0, \sigma_{_1D}^2) $
$\sigma_{_1D}^2=0.10^2$ |
$\bar{_2D}=0.10$
$\epsilon_{_2D} \sim N(0, \sigma_{_2D}^2) $
$\sigma_{_2D}^2=0.10^2$ |
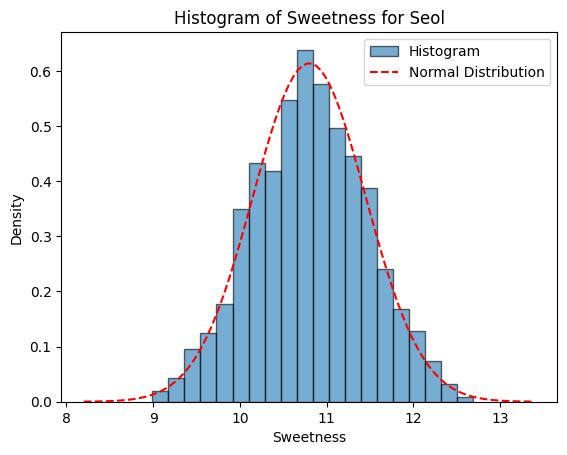
| 당도 $(^1y)$ |
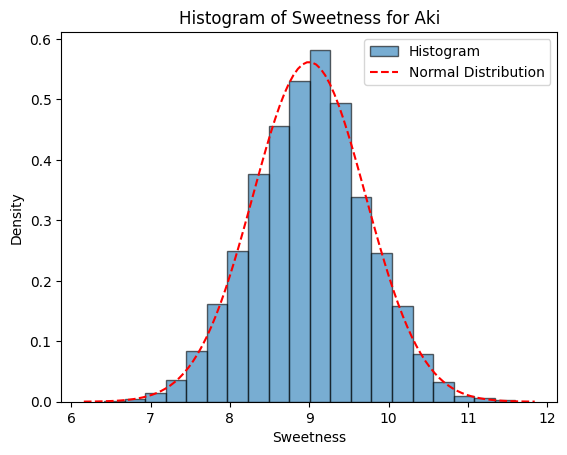
$$^1y=\beta_{0,^1Y}+\beta_{1,^1Y}{\cdot} {^2x}+\epsilon_{^1Y}$$
여기서, $^1y$는 당도
$\beta_{0,^1Y}$는 성숙일에 대한 당도의 회귀직선의 절편이며 값이 0
$\beta_{1, ^1Y}$는 성일에 대한 당도의 회귀직선의 기울기
$\epsilon_{^1Y}$은 오차항이며 평균이 0이고 분산이 $\sigma_{^1Y}^2$인 정규분포: $\epsilon_{^1Y} \sim N(0, \sigma_{^1Y}^2)$
|
$\beta_{1, {_1^1Y}}=0.30$
$\epsilon_{_1^1Y} \sim N(0, \sigma_{_1^1Y})$
$\sigma_{_1^1Y}^2=0.25^2$ |
$\beta_{1, {_2^1Y}}=0.25$
$\epsilon_{_2^1Y} \sim N(0, \sigma_{_2^1Y})$
$\sigma_{_2^1Y}^2=0.50^2$ |
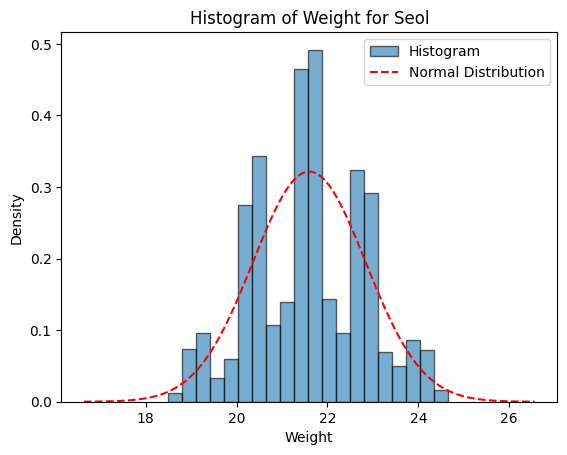
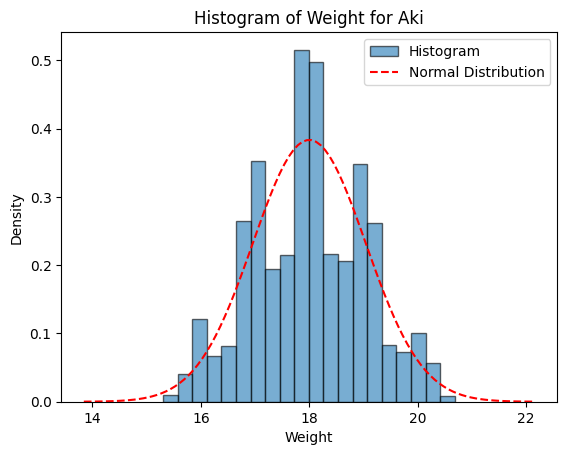
| 과중 $(^2y)$ |
$$^2y=\beta_{0,^2Y}+\beta_{1,^2Y}{\cdot} {^2x}+\epsilon_{^2Y}$$
여기서, $^2y$는 과중
$\beta_{0,^2Y}$는 성숙일에 대한 과중의 회귀직선의 절편이며 값이 0
$\beta_{1, ^2Y}$는 성숙일에 대한 과중의 회귀직선의 기울기
$\epsilon_{^2Y}$은 오차항이며 평균이 0이고 분산이 $\sigma_{^2Y}^2$인 정규분포: $\epsilon_{^2Y} \sim N(0, \sigma_{^2Y}^2)$
|
$\beta_{1, {_1^2Y}}=0.60$
$\epsilon_{_1^2Y} \sim N(0, \sigma_{_1^2Y})$
$\sigma_{_1^2Y}^2=0.25^2$ |
$\beta_{1, {_2^2Y}}=0.50$
$\epsilon_{_2^2Y} \sim N(0, \sigma_{_2^2Y})$
$\sigma_{_2^2Y}^2=0.25^2$ |