
네, 연속형 데이터는 두 값 사이에 무한히 많은 값이 존재해야 하기 때문에 반드시 실수 체계에서 정의됩니다.
연속형 데이터는 수학적으로 실수 집합에서 정의됩니다.
연속형 데이터는 정수나 유리수와 같은 이산적인 수 체계로는 정확히 설명될 수 없습니다.
데이터(data)는 수집된 정보의 형태와 해석 방식에 따라 구분되며, 데이터의 속성과 그에 따른 유형은 통계, 수학, 인공지능 등의 분야에서 매우 중요한 분류 기준입니다. 데이터는 속성에 따라 질적 데이터(범주형)와 양적 데이터(수치형)으로 나뉩니다. 데이터 속성에 따른 유형으로 절적 데이터는 명목형과 순서형의 두가지 유형을 가지며 양적 데이터는 이산형과 연속형의 두가지 유형으로 분류합니다.
Table 1. 데이터 속성과 그에 따른 유형
|
데이터 속성 (nature of data) |
데이터 유형 (data type) |
설명 | 예시 |
|---|---|---|---|
| 질적 데이터 (qualitative / categorical) |
명목형 (nominal) | 순서 없이 범주만 존재, 숫자는 단순 라벨 역할 | 성별(남/여), 혈액형(A/B/AB/O), 국가명 |
| 순서형 (ordinal) | 순서는 있으나, 간격의 크기는 불명확 | 설문 응답(매우 좋음 > 좋음 > 보통), 교육 수준(초등 < 중등 < 고등) | |
| 양적 데이터 (quantitative / numerical) |
이산형 (discrete) | 셀 수 있는 수치, 값 사이에 다른 값이 없음 | 자녀 수, 주사위 눈 |
| 연속형 (continuous) | 측정 가능한 수치, 두 값 사이에 무한히 많은 값 존재 | 키, 무게, 시간, 온도 |
수체계(number Systems)는 수학적으로 정의된 숫자들의 집합으로, 각 데이터 유형이 표현되는 수학적 기반입니다. 각 체계는 수의 성질에 따라 구분됩니다.
Table 2. 수 체계
| 수 체계 | 기호 | 포함 관계 | 특징 | 예시 | 자연수 (Natural Numbers) | ℕ | ℕ ⊂ ℤ | 0 또는 1부터 시작하는 양의 정수 | 0, 1, 2, 3, … |
|---|---|---|---|---|
| 정수 (Integers) | ℤ | ℤ ⊂ ℚ | 양의 정수, 음의 정수, 0 포함 | …, -2, -1, 0, 1, 2, … |
| 유리수 (Rational Numbers) | ℚ | ℚ ⊂ ℝ | 분수로 표현 가능한 수 | 1/2, -3, 0.75 |
| 실수 (Real Numbers) | ℝ | ℝ ⊂ ℂ | 유리수와 무리수를 포함하는 연속적인 수 | π, √2, -1.5, 0, 2 |
| 복소수 (Complex Numbers) | ℂ | – | 실수와 허수의 조합 | 3 + 2i, -1 – i, 0 + i |
데이터 유형은 해당하는 수 체계 중 어떤 것과 연결되는지에 따라 해석 및 분석 방법이 달라집니다.
Table 3. 데이터 유형에 따른 수 체계
| 데이터 속성 | 데이터 유형 | 정의 | 수 체계 | 예시 |
|---|---|---|---|---|
| 질적 데이터 (qualitative / categorical) | 명목형 (nominal type) | 순서 없이 범주만 존재 | 기호 집합 (set of labels) | 성별, 혈액형, 국가명 |
| 순서형 (ordinal) | 범주 간 순서는 있으나 간격은 불명확 | 자연수(ℕ): 순서를 의미 | 설문 응답(좋음 > 보통), 학년 | |
| 양적 데이터 (quantitative / numerical) | 이산형 (discrete type) | 값과 값 사이에 다른 값이 존재하지 않음 | 자연수(ℕ), 정수(ℤ), 실수(ℝ) | 자녀 수, 건물 층, 디지털 오디오 볼륨 |
| 연속형 (continuous) | 두 값 사이에 무한히 많은 값이 존재 | 실수(ℝ) | 키, 무게, 시간, 온도 |
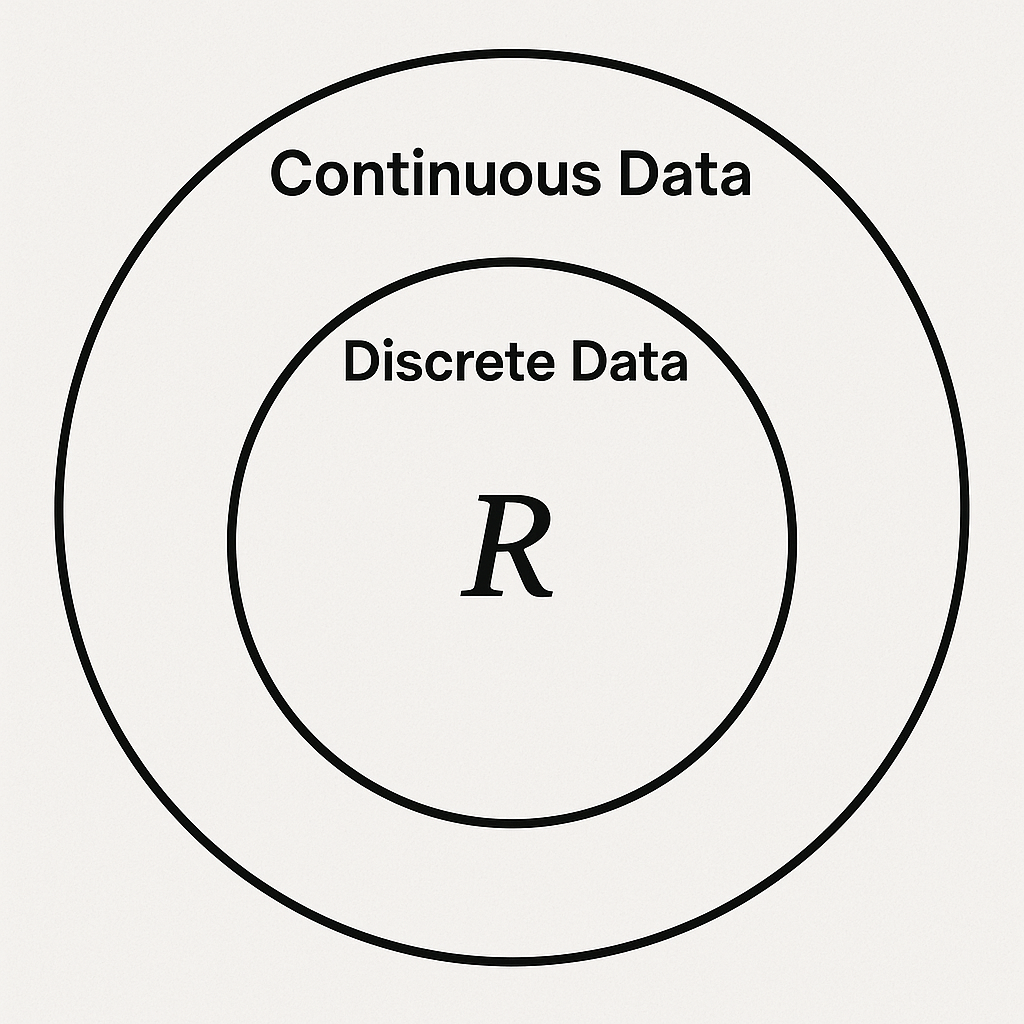
Fig. 1. 연속형 데이터와 이산형 데이터의 관계와 수 체계
연속형 데이터는 두 값 사이에 무한히 많은 실수 값이 존재하기 때문에, 반드시 실수 체계에서 정의됩니다. 이산형(discrete) 데이터는 일반적으로 정수(integer, ℤ) 또는 유한한 집합의 원소로 정의됩니다. 즉, 값과 값 사이가 끊겨 있고, 두 값 사이에 다른 값이 존재하지 않는 데이터입니다.
Table 4. 연속형 vs 이산형 데이터: 전체 비교
| 항목 | 연속형 데이터 (continuous) | 이산형 데이터 (discrete) |
|---|---|---|
| 수 체계 | 실수(ℝ) | 자연수, 정수(ℤ), 유한 실수(ℝ) 집합 |
| 값의 수 | 조밀하고 무한히 많음 | 셀 수 있음 (countable) |
| 예시 | 키, 무게, 온도, 시간 | 자녀 수, 주사위 눈, 고장 횟수 |
| 표현 방식 | 측정값 (measured) | 계산값 또는 개수 (counted) |
| 수학적 특징 | 두 값 사이에 무한히 많은 값 존재 | 값 사이에 간격 존재 |
Table 5. AI/통계 모델 적용 차이
| 항목 | 연속형 데이터 | 이산형 데이터 |
|---|---|---|
| 문제 유형 | 회귀 (Regression) | 분류 (Classification) |
| 예측 대상 | 수치값 (예: 키, 가격, 온도) | 범주 (예: 고양이/강아지, 합격/불합격) |
| 대표 모델 | 선형 회귀, 다항 회귀, MLP 회귀 | 로지스틱 회귀, 의사결정나무, 소프트맥스 |
| 출력 값 | 실수(float) | 클래스 또는 확률 벡터 |
| 손실 함수 | 평균제곱오차(MSE), MAE | 교차엔트로피(Cross-Entropy) |
Table 6. 확률 분포 예시 비교
| 항목 | 연속형 데이터의 확률분포 표현 | 이산형 데이터의 확률분포 표현 |
|---|---|---|
| 대표 함수 | 확률밀도함수 (PDF) | 확률질량함수 (PMF) |
| 확률 계산 | 적분: $P(a ≤ X ≤ b) = \int_a^b f(x)\, dx$ | 합: $P(X = x) = p(x), \sum p(x) = 1$ |
| 대표 확률분포 | 정규분포, 지수분포, 감마분포 | 베르누이, 이항, 포아송 |
| 그래프 형태 | 연속 곡선 | 막대 그래프 |
연속형 데이터를 이산형 데이터로 변환하는 기법을 구간화(discretization)라고 합니다.
연속형(실수형) 데이터를 일정한 규칙에 따라 여러 개의 이산형(범주형) 구간으로 나누는 작업입니다. 예를 들면,
연령(실수값) → “청소년”, “성인”, “노인”
소득(실수값) → “저소득”, “중간소득”, “고소득”
Table 7. 구간화의 주요 목적
| 목적 | 설명 |
|---|---|
| 분류 모델 입력값으로 변환 | 연속형 변수를 범주형 변수로 바꾸어 분류 알고리즘에 활용 가능 |
| 해석 용이성 향상 | 숫자보다 범주 구간이 사람에게 직관적으로 이해되기 쉬움 |
| 이상값 영향 감소 | 극단값을 같은 구간에 묶음으로써 모델의 안정성 향상 |
Table 8. 주요 구간화 기법
| 기법 | 설명 | 예시 |
|---|---|---|
| 고정 구간 방식 (Equal-width) | 전체 범위를 동일한 폭으로 나눔 | [0–10), [10–20), [20–30) |
| 빈도 균등 구간 (Equal-frequency) | 각 구간에 데이터 수를 균등하게 배분 | 사분위수 기반 4개 구간 |
| 클러스터 기반 (K-means 등) | 데이터 분포에 따라 유사한 값끼리 그룹화 | k=3으로 클러스터링 후 3구간 생성 |
| 도메인 기반 구간 | 전문가 지식에 따라 구간을 지정 | 나이: 청소년, 성인, 노인 |
| 결정트리 기반 | 정보 이득 등 기준으로 자동 구간화 | CART가 자동으로 경계값 선택 |
Table 9. 구간화시 주의점
| 주의 사항 | 설명 |
|---|---|
| 정보 손실 | 연속형 데이터를 범주로 묶으면서 세부 정보가 사라질 수 있음 |
| 경계 효과 | 경계 근처의 값들이 인위적으로 구분될 수 있음 (예: 19.9 vs 20.0) |
| 정확도 저하 가능성 | 회귀나 세밀한 예측에서는 오히려 성능이 나빠질 수 있음 |
| 구간 수 민감도 | 구간이 너무 많으면 과적합, 너무 적으면 정보 부족 |
이산형 데이터를 연속형 데이터로 변화하는 것을 과정에 따라 연속화(continuization), 연속 근사 (continuous approximation, 실수값 변환 (real-valued transformation, 임베딩(embedding), 완화(relaxation)이라고 부릅니다.
Table 10. 이산형 데이터의 연속형 데이터로 변환을 표현하는 방식
| 변환 표현 방식 | 설명 | 예시 |
|---|---|---|
| 연속화 (continuization) | 이산형 데이터를 연속형 실수값으로 변환하는 일반적 표현 | 고장 횟수 데이터를 회귀 분석에서 실수로 간주하여 예측 |
| 연속 근사 (continuous Approximation) | 이산 분포나 값을 연속 함수 또는 분포로 근사 | 이항분포를 정규분포로 근사 (n이 클 때) |
| 실수 값 변환 (real-valued transformation) | 범주형 또는 이산적 실수를 연속형으로 변환하여 모델에 투입 | 학년 1, 2, 3, 4 → 1.0, 2.0, 3.0, 4.0 |
| 임베딩 (embedding) | 범주형 값을 고차원 실수 벡터 공간으로 매핑 | 단어 “apple” → 300차원 임베딩 벡터 |
| 완화 (relaxation) | 이산 선택지를 연속 확률 표현으로 변형 (딥러닝에서 미분 가능성 확보 목적) | 클래스 선택 → Gumbel-softmax로 확률 분포 벡터화 |
Table 11. 이산형 데이터를 연속형 데이터로 변환하는 목적
| 목적 | 설명 |
|---|---|
| 모델 호환성 확보 | 선형 회귀, 신경망 등 연속 입력을 요구하는 모델에 사용할 수 있도록 변환 |
| 유사도 표현 가능 | 숫자 간 거리나 유사성을 반영할 수 있음 |
| 미분 가능성 확보 | 딥러닝 모델에서 이산 변수는 미분이 불가능하므로, 연속화하여 학습 가능하게 함 |
| 정규화 및 스케일링 가능 | 연속 값으로 변환하면 표준화나 정규화를 적용할 수 있음 |
| 시계열/신호 처리 적용 | 이산 이벤트를 연속 신호로 바꿔 필터링, 파형 분석 등에 활용 |
Table 12. 이산형 데이터를 연속형 데이터로 변환하는 주요 기법
| 기법 | 설명 | 예시 |
|---|---|---|
| 정수 실수화 | 정수형 데이터를 float형으로 변환 | 주사위 눈 1 → 1.0 |
| 임베딩 (Embedding) | 범주형 데이터를 실수 벡터 공간으로 매핑 | 단어 “apple” → [0.1, 0.4, …, 0.7] |
| 연속 근사 | 이산 분포를 연속 분포로 근사 | 이항 분포 → 정규 분포 |
| Gumbel-softmax | 이산 선택지를 확률 벡터로 표현 (딥러닝 미분 가능) | 분류를 softmax 확률로 표현 |
| 수치 기반 대체값 | 범주에 평균값, 점수 등 의미 있는 실수 매핑 | 학점 A, B, C → 4.0, 3.0, 2.0 |
Table 13. 이산형 데이터를 연속형 데이터로 변환할 때 주의점
| 주의점 | 설명 |
|---|---|
| 의미 없는 수치화 위험 | 명목형 데이터를 순서 있는 수처럼 처리하면 잘못된 해석 유발 |
| 분포 왜곡 | 이산 데이터를 연속화하면 원래의 이산적 특성이 사라질 수 있음 |
| 해석력 저하 | 변환된 연속 값은 원래 범주의 의미를 잃을 수 있음 |
| 모델 과적합 위험 | 불필요한 자유도가 생겨 과적합될 수 있음 |
Table 14. 측정대상에 따른 데이터 유형과 척도 유형
| 관측 대상 | 연속형 데이터 (continuous data) | 이산형 데이터 (discrete data) | |||
|---|---|---|---|---|---|
| 간격척도 | 비율척도 | ||||
| 순서척도 | 명목척도 | 이분척도 | |||
| 시간 | 시, 분, 초 | – | 육상 1, 2, 3 등 | – | 오전 / 오후 |
| 날짜 | 연, 월, 일 | – | 1월, 2월, 3월 | – | 이전 / 이후 |
| 사이클 시간 | – | 월, 일, 시, 분, 초 | 10, 20, 30 등 | – | 이전 / 이후 |
| 속도 | – | 시속 km / 초당 m | 느림, 중간, 빠름 | – | 빠름 / 느림 |
| 밝기 | – | 루멘 | 어두움, 중간, 밝음 | – | 켬 / 끔 |
| 온도 | 섭씨 / 화씨 | – | 낮음, 중간, 높음 | – | 차가움 / 뜨거움 |
| 개수 | – | 측정 가능한 개수 | 1개, 2개, 3개 | – | 많음 / 적음 |
| 시험 점수 | 점수 | 백분율 | A, B, C, D, F 학점 | – | 합격 / 불합격 |
| 결함 수 | – | – | 균열 1개, 2개 … | – | 있음 / 없음 |
| 결함 종류 | – | – | – | Error1, 2, 3, … | 좋음 / 나쁨 |
| 색상 | – | – | – | 빨강, 파랑, 초록 | – |
| 위치 | – | – | – | 서울, 부산, 대전 | 국내 / 해외 |
| 소속 그룹 | – | – | – | 인사팀, 마케팅팀, 연구팀 | 정규직 / 계약직 |
| 기타 | 비율 | 백분율 | 낮음, 중간, 높음 | – | 이상 / 이하 |