네. 회귀는 중심극한정리의 개념확장으로 볼 수 있습니다.
회귀계수는 중심극한정리의 결과로 정규분포를 따르는 추정량입니다.
중심극한정리는 “표본 평균이 반복 표집을 통해 확률변수로 표현되며 정규분포로 수렴”한다는 내용을 담고 있습니다.
회귀분석에서는 회귀계수가 표본에 따라 변하는 추정량(확률변수)이며, 이 역시 정규분포로 수렴합니다. 이건 다변량 중심극한정리의 적용 결과입니다.
회귀는 중심극한정리의 수학적 확장은 아니지만, “평균을 확률적으로 추정한다”는 통계적 사고의 다차원적·함수적 확장으로 이해할 수 있습니다. 특히 베이지안 회귀나 함수공간 기반의 회귀(Gaussian Process Regression)에서는 이 연결이 더욱 명확해집니다.
중심극한정리: 스칼라 평균을 추정하는 문제
$$\hat{\mu} = \frac{1}{n} \sum X_i$$
회귀: 입력에 따라 변하는 평균 함수를 추정하는 문제
$$\mathbb{E}[Y \mid X] = f(X) = \beta_0 + \beta_1 X_1 + \cdots + \beta_p X_p$$
따라서 회귀는 CLT의 추정 대상을 “상수 → 함수”로 확장한 것이라고 볼 수 있습니다.
Table 1. 평균 추정의 통계적 구조 비교
중심극한정리는 모평균점($\mu$) 하나를 정규분포로 예측합니다.
회귀는 회귀선($f(x)$)를 계수벡터의 정규분포로 예측합니다, 즉 함수 전체가 확률적으로 변동하는 대상이 됩니다.
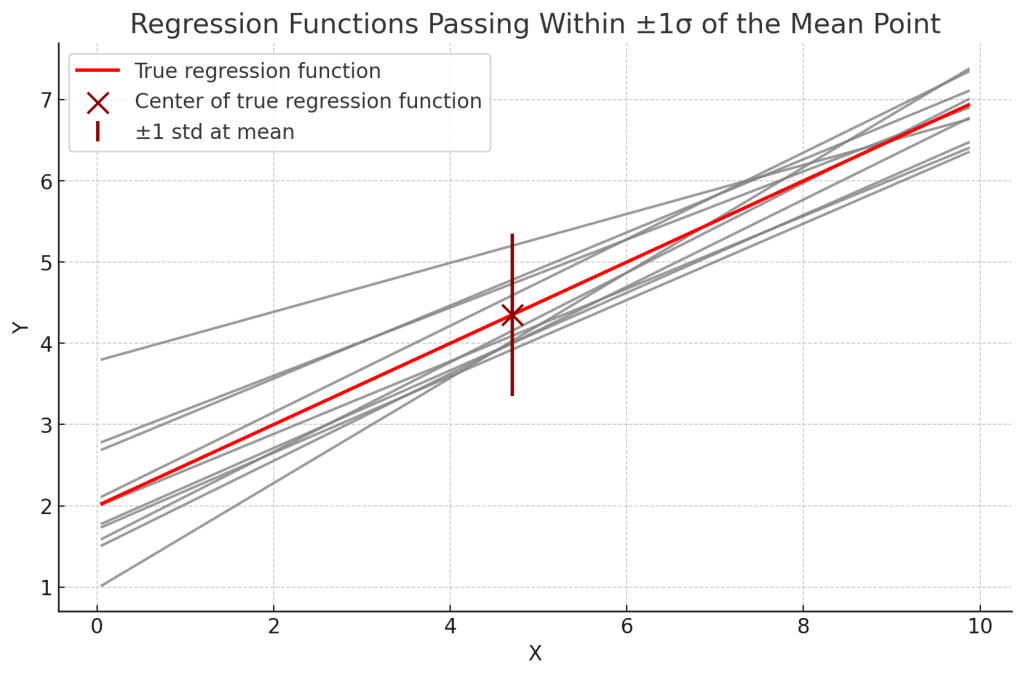
Fig. 1. 은 실제 현실에서 표본평균점조차 모델 오차(노이즈)로 인해 정확히 예측되지 않는 상황을 반영한 것입니다.
중심극한정리 관점에서, 평균 추정의 함수적 확장인 회귀에서도 평균점의 예측은 분산을 가짐을 보여줍니다.
Fig. 1. 모평균점에서의 오차항