1. 정규분포의 확률밀도함수 (PDF)
정규분포 \( \mathcal{N}(\mu, \sigma^2) \) 의 확률밀도함수는 다음과 같습니다.
$$
f(x \mid \mu, \sigma^2)
= \frac{1}{\sqrt{2\pi\sigma^2}}
\exp\left( -\frac{(x – \mu)^2}{2\sigma^2} \right)
$$
2. 표본이 여러 개인 경우
표본이 \( n \)개, 즉 \( x_1, x_2, \ldots, x_n \)이 독립이고 동일분포(i.i.d.)라고 하면,
공동확률밀도함수(joint pdf)는 곱으로 표현됩니다.
$$
f(x_1, \ldots, x_n \mid \mu, \sigma^2)
= \prod_{i=1}^n f(x_i \mid \mu, \sigma^2)
$$
3. 우도함수 (Likelihood function)
주어진 데이터 \( \mathbf{x} = (x_1, \ldots, x_n) \)에 대해
모수 \( \mu, \sigma^2 \)를 변수로 보는 함수가 바로 우도함수입니다.
$$
L(\mu, \sigma^2; \mathbf{x})
= \prod_{i=1}^n \frac{1}{\sqrt{2\pi\sigma^2}}
\exp\left( -\frac{(x_i – \mu)^2}{2\sigma^2} \right)
$$
4. 로그우도함수 (Log-likelihood function)
곱을 취급하기 편하게 로그를 취하면 다음과 같습니다.
$$
\ell(\mu, \sigma^2; \mathbf{x}) = \log L(\mu, \sigma^2; \mathbf{x})
$$
$$
= -\frac{n}{2} \log (2 \pi \sigma^2)
– \frac{1}{2\sigma^2} \sum_{i=1}^n (x_i – \mu)^2
$$
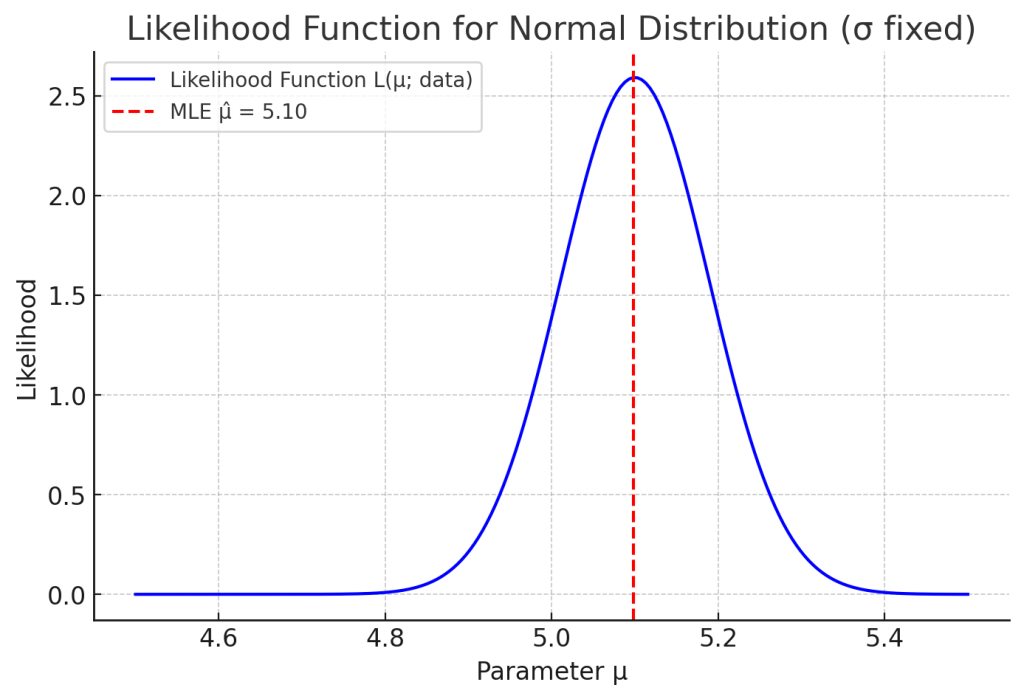
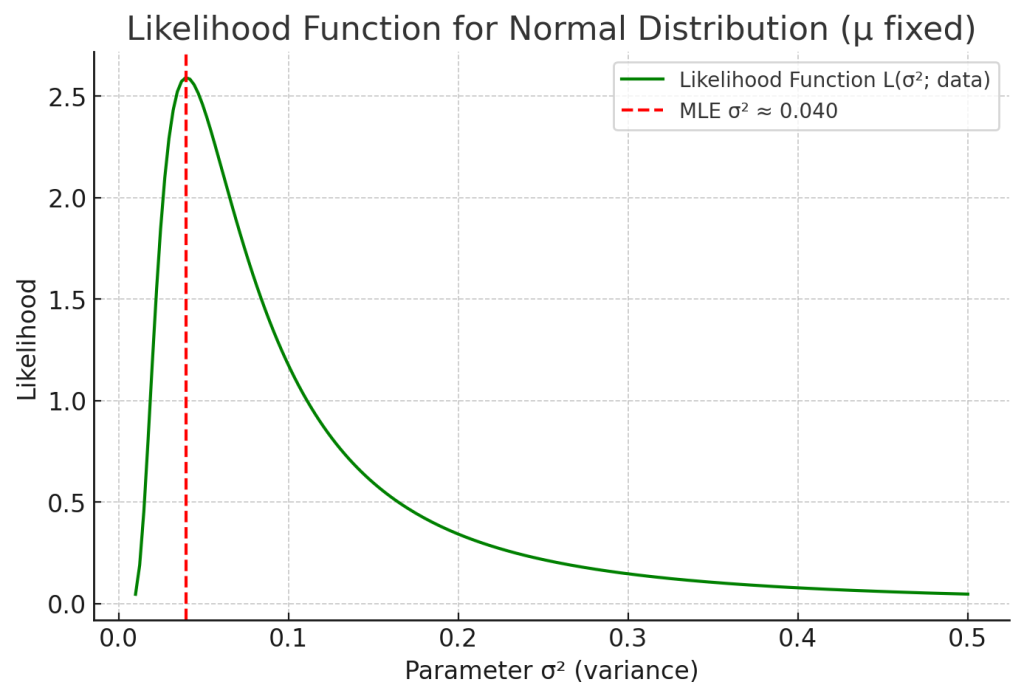
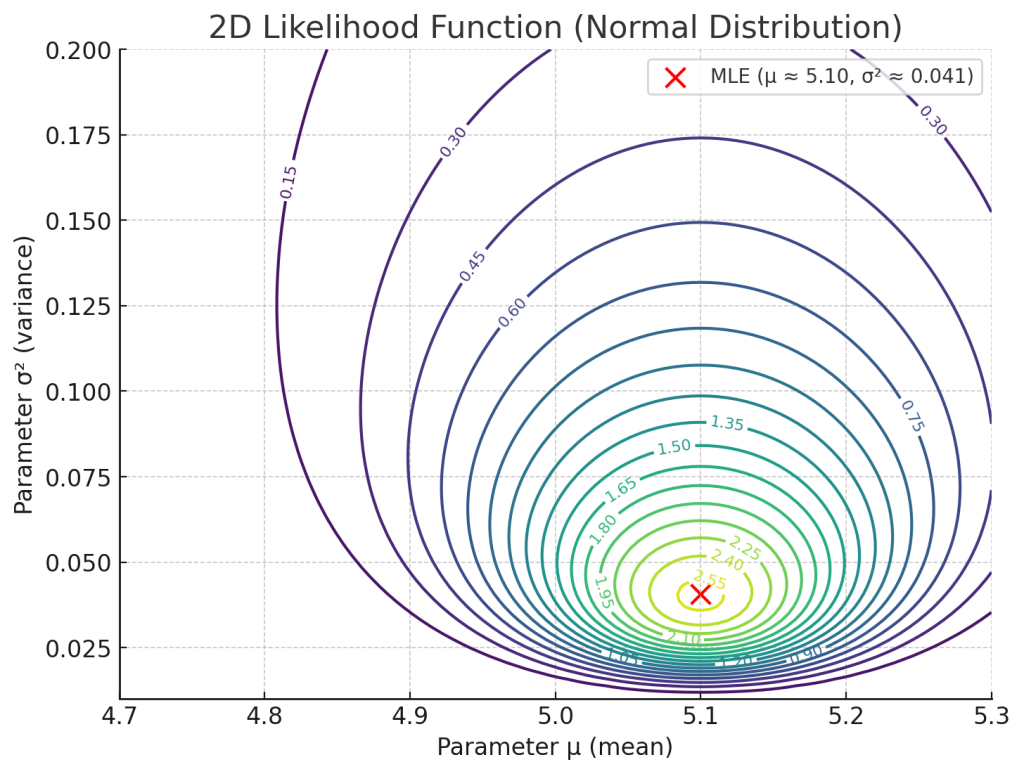
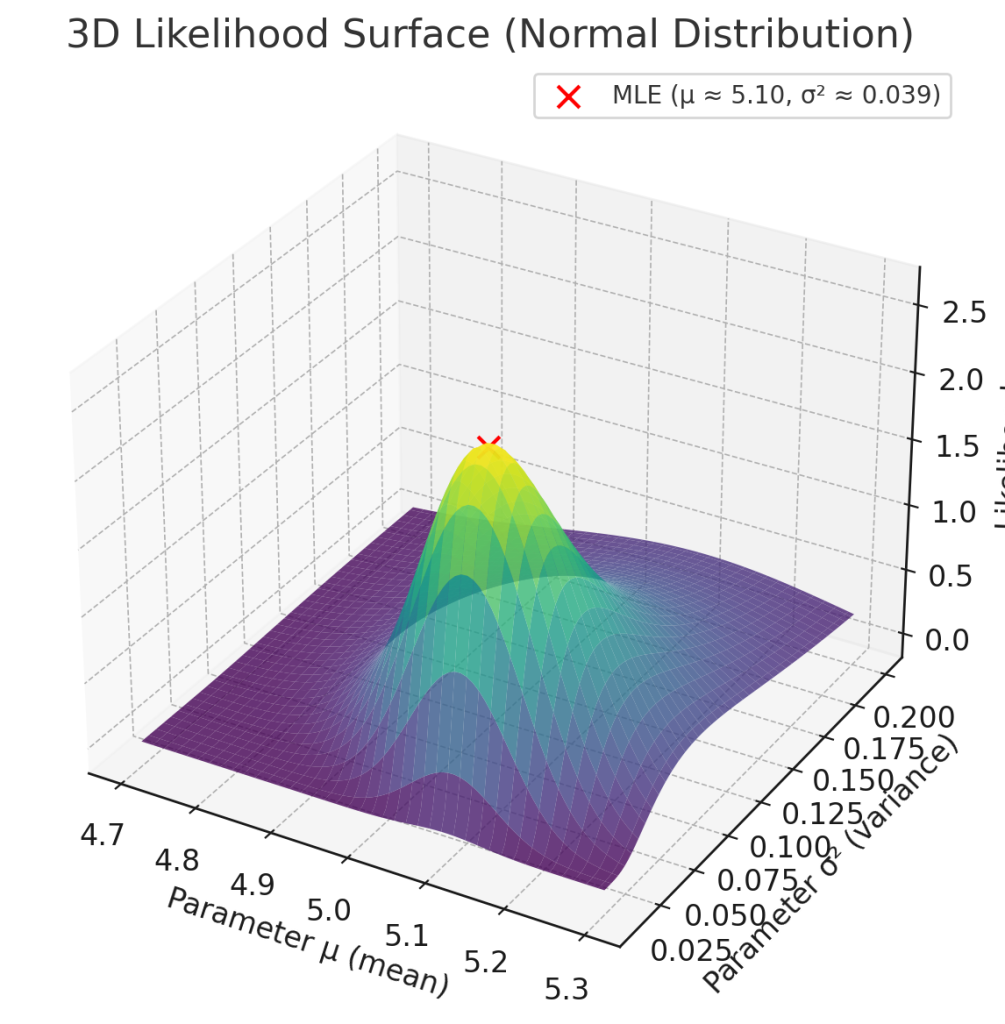
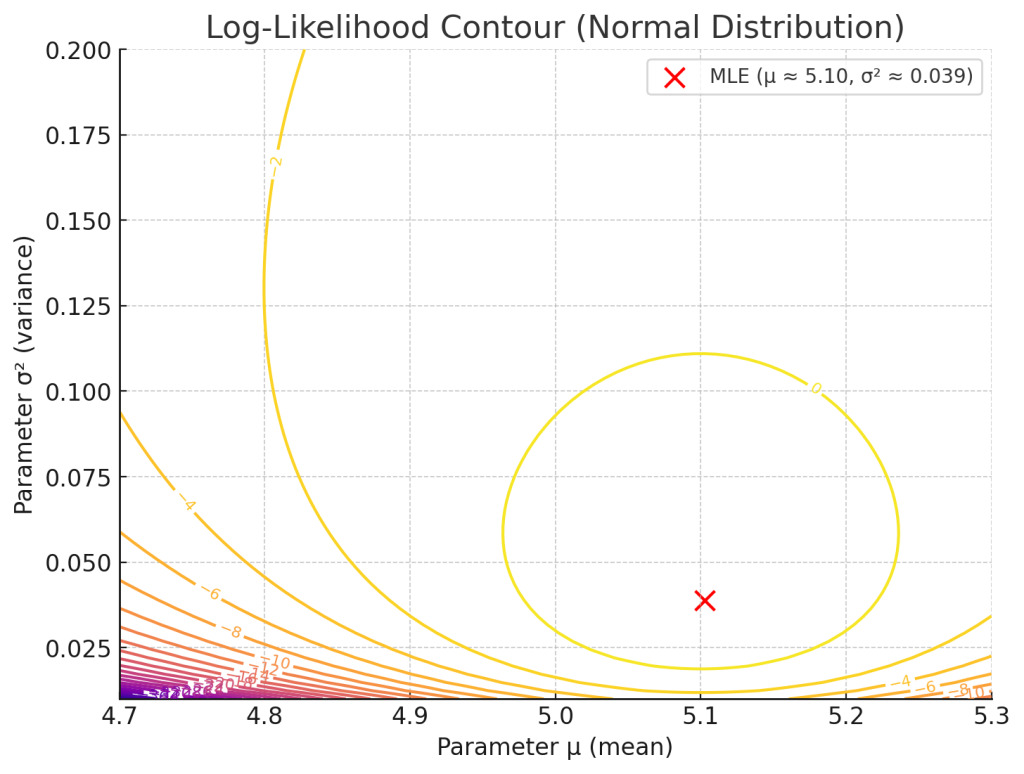
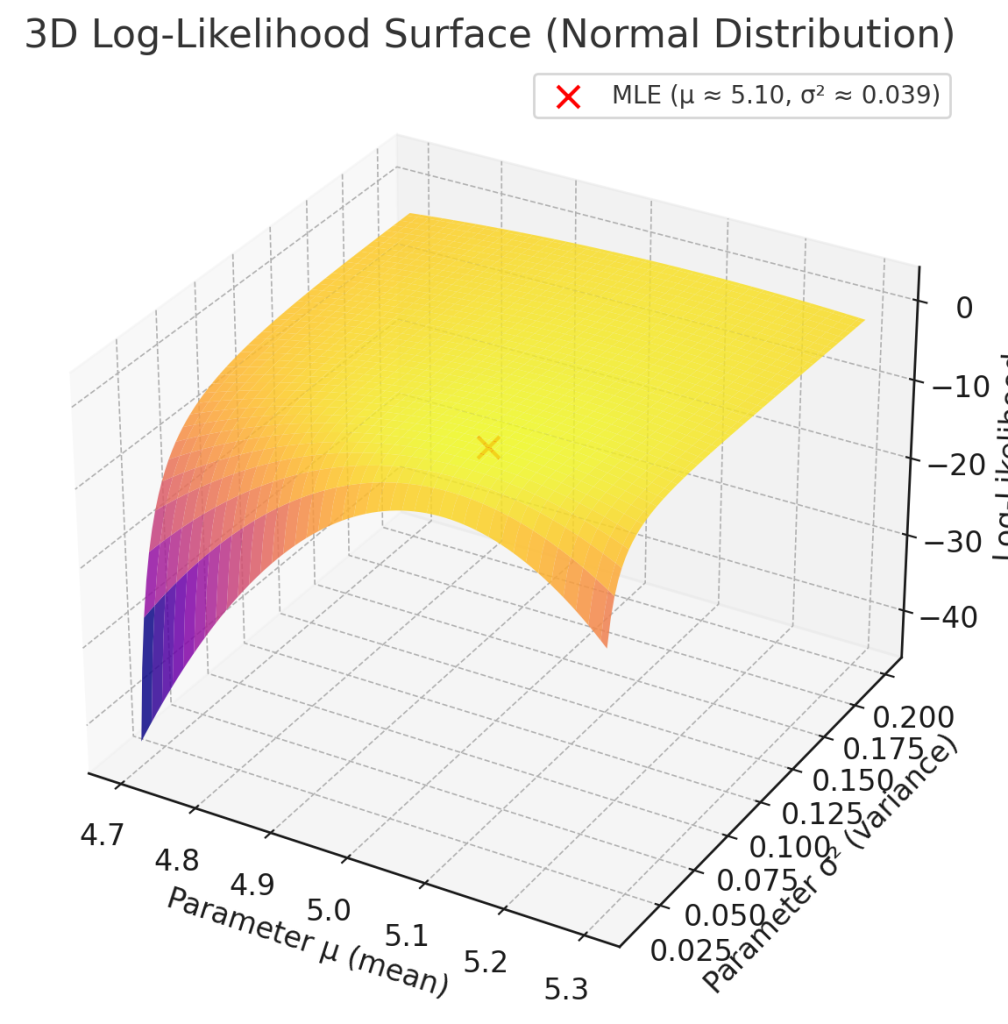
5. 해석
– 우도함수 \( L(\mu, \sigma^2; \mathbf{x}) \) 는 데이터가 주어졌을 때, “이 데이터가 해당 모수값에서 얼마나 그럴듯하게 나왔는가”를 나타냅니다.
– 최대우도추정량(MLE)은 이 우도함수를 최대화하는 \(\mu, \sigma^2\)입니다.
$$
\hat{\mu} = \bar{x}, \quad
\hat{\sigma}^2 = \frac{1}{n} \sum_{i=1}^n (x_i – \bar{x})^2
$$