완전확률화 실험설계 ?
Random design of experiment ?
1.1. 완전확률화 실험설계
2.1. 완전확률화 실험설계 적용예
1. 애니메이션
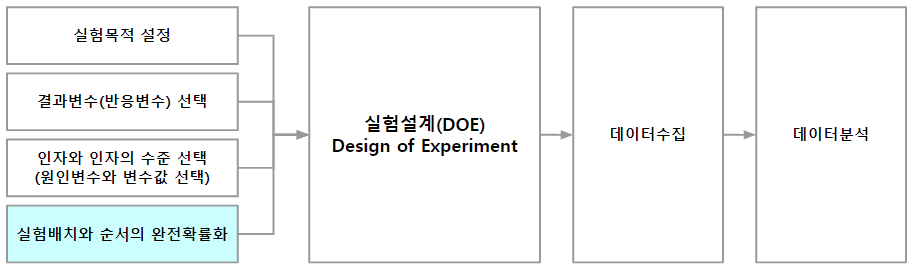
완전확률화 실험설계
2. 설명
2.1 완전확률화 실험설계 적용예
원인(인자, 요인, 중재, 처치, factor, intervention, treatment)에 따른 결과(반응, 효과)를 살펴보는 실험을 설계한다고 할 때, 가장 중요한 것은 관심을 가지는 원인이외의 다른 원인이 결과에 영향을 미치면 안된다는 점입니다. 예를 들어, 자동차 모델(A, B, C)의 1리터당 주행거리(연비)를 비교하는 실험을 설계한다고 하면 우선 관심을 가지는 인자(factor)는 자동차 모델이며 관심을 가지는 결과변수는 연비입니다. 그리고 원인변수가 갖는 변수는 변수값 A, B, C를 가지는 자동차 모델입니다. 원인변수(인자, factor)는 명목척도로 구해지는 범주형변수이며, 결과변수는 비례척도로 구해지는 연속형변수입니다. 차종(자동차 모델)별로 연비를 관측할 때 실험 기간이 길 수도 있고 비용 등 여러 가지 이유로 차종별 차를 많이 추출하기 어렵습니다.
한 원인변수(차종)의 변수값(A, B, C)인 차종간에 존재할 수 있는 차이를 정확하게 파악하기 위해서는 다른 원인들의 영향을 될 수 있는 대로 적게 해 주는 것이 좋습니다. 이를 위한 방법 중의 하나는 실험 전체를 완전확률화(무작위, random)하게 하는 것입니다. 같은 자동차 모델이라도 연식에 따른 영향과 각 차종에서 차량별 다름을 최대한 줄이기 위해서 각 자동차 모델 중에서 실험시간과 실험비용을 고려해서 무작위(완전확률화)로 신차 5대를 선정하였습니다. 표본을 무작위로 추출하였다고 해도 동일한 조건하의 연비측정을 위해 한 운전자가 모든 15대의 차를 운전해 실험해 볼 수도 있지만 하루에 3대밖에 측정할 수 없다면 총 5일에 걸쳐서 측정을 하게 됩니다. 이 경우 연비를 측정하는 5일동안 날씨나 풍속, 풍향 등 여러 환경이 달라 질 수 있어 측정된 값이 실험날짜에 영향을 받게 됩니다.
최종적으로 하루에 모든 차의 연비를 측정하기 위하여 다섯 명의 운전자(1, 2, 3, 4, 5)가 차를 운전하는 실험설계를 하였다면 이번에는 자동차의 연비는 운전자에 따라 영향을 받을 수 있는 문제가 발생합니다. 그래서 15대의 차를 5명의 운전자에게 무작위(random)로 3대씩 배정한 후 실험의 순서 역시 무작위로 하는 완전확률화 실험설계를 이어 갑니다. 15대의 차에 1번부터 15번까지의 번호를 부여한 다음, 추첨으로 나오는 번호순서대로 연비를 측정합니다. 이와 같이 실험하면 운전자에 의한 변동이 전체 관측값에 균등하게 영향을 미치어 다른 운전자로 인해 연비가 달라질 가능성이 줄어듭니다. 이와 같이 모든 실험과정에서 무작위를 도입하는 실험방법을 완전확률화 실험계획법(completely randomized design)이라 부릅니다.
위의 요인외에도 연비에 대한 운행조건별 차종의 장점(예를 들면 정차가 심한 도심보다는 고속도로에서 연비가 높게 개발된 차)을 모두 동일하게 하는 완전화확률 실험설계를 하는 것은 어렵습니디. 즉, 어느 도로에서 실험할 것인지를 무작위(추첨)으로 하기에는 무리가 있습니다. 따라서 완전확률화 실혐설계는 적용하는 범위를 정해야 하며 이는 실험의 목적에 따르는 것이 중요합니다. 정리하면 실험의 목적을 분명히 정하고 완전확률화 실험설계를 적용하는 것이 순서입니다.
다음의 표는 추첨(제비뽑기, 프로그램으로 난수를 발생시켜 정하기)에 의해 운전자와 차종별 5대의 차가 배치된 실험설계를 보여 줍니다. 기호 A, B, C는 다른 차종을 의미합니다.
완전확률화 실험설계에 따른 실험설계의 예
| 운전자 | 1 | 2 | 3 | 4 | 5 |
| 표본추출된 차종(자동차모델) | B1 | A2 | B2 | C1 | A4 |
| B5 | C4 | A1 | A3 | C3 | |
| C5 | B4 | A5 | B3 | C2 |
3. 실습
3.2. 구글시트 함수
=ROWS(F2:F2) : 지정된 배열 또는 범위에 있는 행의 개수.
=RANDBETWEEN(1,100) : 두 값 사이(두 값 포함)의 고르게 분산된 정수인 난수를 반환.
=INDIRECT(D3&”:”&E3) : 문자열로 지정된 셀 참조를 반환.
=COUNTIF(F2:F2, ROW(D3:E3)) : 범위에서 조건에 맞는 개수를 표시.
=NOT(논리표현식) : 논리 값의 역을 반환.
=LARGE(데이터집합, n) : 데이터 집합에서 n번째로 큰 요소를 반환.
=ARRAYFORMULA : 배열 수식에서 여러 행 또는 열에 반환된 값을 표시.
=ARRAY_CONSTRAIN : 배열 결과를 지정된 크기로 제한.
=VLOOKUP(H3,A:B,2,FALSE) : 열 방향 검색. A:B열의 첫 번째 열에서 H3값이 있는 행의 2번째 값을 표시합니다. FALSE를 입력하면, 완전히 일치된 값만 표시합니다. FALSE가 아닌 TRUE를 입력하면, H3에 근접한 값(H3보다 작거나 같은 값)이 있는 행의 2번째 값을 표시합니다.
=AVERAGE(B3:B1002) : 평균. B3에서 B1002에 있는 데이터의 평균.
=VARP(B3:B1002) : 모분산. B3에서 B1002에 있는 데이터의 모분산. 편차제곱합을 데이터 개수로 나눔.
=STDEV.P(B3:B1002) : 모표준편차. B3에서 B1002에 있는 데이터의 모표준편차. 모분산의 제곱근.
=COUNT(I3:I22) : 데이터 개수. I3에서 I22에 있는 숫자로 표시된 데이터의 개수.
=VAR.S(I3:I22) : 표본분산. I3에서 I22에 있는 데이터의 표본분산. 편차제곱합을 데이터 개수 -1로 나눔.
=STDEV.S(I3:I22) : 표본표준편차. I3에서 I22에 있는 데이터의 표본표준편차. 표본분산의 제곱근.
=AK3/SQRT(AH3) : AK3 값을 AH3의 제곱근으로 나눔. 이 실습에서는 표준오차를 계산함.
=T.INV(1-(1-AN3)/2,AH3-1) : T확률분포에서 T값을 계산. T.INV(확률, 자유도)로 구성. 이 실습에서는 AN3에 95% 신뢰수준을 입력하였는데, 양측검정에서는 양쪽 끝 확률이 각각 2.5%가 되어야 함. 따라서, 1-(1-0.95)/2를 하면 누적확률밀도가 0.975, 즉 97.5%가 되어서, 양쪽 끝 확률이 각각 2.5%인 T값을 얻을 수 있음.
=AND(AR3>=AP3, AR3<=AQ3) : 입력된 조건이 모두 참이면 TRUE, 입력된 조건 중 하나라도 거짓이면, FALSE를 표시. AR3값이 AP3 이상이고, AQ3 이하이면 TRUE를 표시함.
3.3. 실습강의
– 집단
– 랜덤 샘플링(완전확률화하여 표본을 추출)
– 표본통계량
– 표본통계량으로 집단의 모수 추정 : 점 추정, 구간 추정
– 샘플링된 빈도 수
– 실습 안내
4. 용어
4.1 용어
시행
확률이론에서, 실험이나 시행은 무한히 반복되어 행해 질 수 있고 표본공간으로 알려진 가능한 모든 결과의 집합을 얻는 과정을 말합니다. 실험은 하나 이상의 결과가 있을 경우는 “무작위”로, 하나만 있는 경우는 “결정적”으로 표현합니다. 예를 들면, 2 가지(결과는 상호 배타적) 가능한 결과를 갖는 무작위 실험은 베르누이 시험이 있습니다.
실험이 수행 될 때, 시행의 결과는 보통 하나로 나타납니다. 그 결과는 모든 사건에 포함됩니다. 이 모든 사건은 시행에서 발생했다고 말합니다. 같은 실험을 여러 번 수행하고 결과를 모으고 나면 실험자는 실험에서 발생할 수 있는 다양한 결과 및 사건의 경험적 확률을 평가하고 통계분석방법을 적용할 수 있습니다.
Reference
Experiment (probability theory) – Wikipedia
확률
확률은 사건이 일어날 가능성을 정량화하는 척도입니다. 확률은 0에서 1 사이의 숫자로 정량화됩니다. 여기서, 0은 불가능함을 나타내며 1은 확실함을 나타냅니다. 시행(event)의 확률이 높을수록 시행이 발생할 가능성이 큽니다. 간단한 예가 동전 던지기입니다. 동전 던지기는 결과가 명확하게 두 가지 결과인 “앞면(Head)”와 “뒷면(Tale)”으로 나타납니다. 그리고 쉽게 앞면과 뒷면의 확률은 동일하다고 동의가 이루어집니다. 다른 결과가 없기 때문에 “앞면”또는 뒷면”의 확률은 1/2 (0.5 또는 50 %)입니다.
이러한 확률개념은 수학, 통계, 금융, 도박, 과학 (특히 물리학), 인공지능, 기계 학습, 컴퓨터 과학, 게임 이론 등과 같은 분야에 공리적 수학적 형식화를 제공합니다. 빈도에 관한 추정을 이끌어내거나 복잡한 시스템의 기본 역학 및 규칙성을 기술하는 데에도 사용됩니다.
Reference
확률공간
확률이론에서, 확률공간 또는 확률 3요소($\Omega, \mathcal{F}, P$)는 무작위로 발생하는 상태로 구성된 실제 프로세스 (또는 “실험”)입니다. 확률공간은 특정 상황이나 실험을 염두에 두고 구성됩니다. 그런 종류의 상황이 발생할 때마다 가능한 결과의 집합이 동일하고 확률도 동일하다는 것을 보여줍니다.
확률공간은 다음 세 부분으로 구성됩니다
– 가능한 모든 결과의 집합인 표본공간 : $\Omega$
– 0개 이상의 결과가 포함된 시행(event)의 집합 : $\mathcal{F}$
– 시행에 확률을 할당하는 함수 또는 시행에서의 확률 : $P$
결과는 모델을 한 번 실행한 결과입니다. 개별 결과는 거의 실용적이지 않을 수 있기 때문에 더 복잡한 시행을 하여 결과 집단을 특성화합니다. 그러한 모든 사건의 집합은 $\sigma$ 대수인 $\mathcal F$입니다. 마지막으로 각 시행의 발생 가능성을 지정해야 할 필요가 있습니다. 이것은 확률측정함수, $P$를 사용하여 수행됩니다.
확률공간이 설정되면 “자연”이 이동하고 표본공간($\Omega$)에서 단일결과 ($\omega$)를 선택한다고 가정합니다. 선택된 결과($\omega$)를 포함하는 $\mathcal {F}$의 모든 시행($\Omega$)이 “발생했다”고합니다. 각 시행은 $\Omega$의 하위집합 입니다. 본질적으로 수행되는 선택은 실험이 무한 반복 될 경우, 각 사건의 발생 빈도는 함수에 의해 규정 된 확률과 일치 할 수 있는 방식으로 수행됩니다.
러시아의 수학자 Andrey Kolmogorov는 1930년대 확률공간의 개념을 다른 확률의 공리와 함께 소개했습니다. 오늘날 확률론의 공리화를 위한 대체 접근법이 존재합니다. 무작위 변수의 대수학입니다. 이는 확률 조작에 관한 수학과 관련있습니다. “확률해석”은 “확률”의 의미와 해석 방법에 대한 몇 가지 대안을 설명합니다. 또한, 개념적으로는 확률과 유사하지만 모든 규칙을 따르지 않는 양에 대한 이론을 수립하려는 시도가 있었습니다. 예를 들어 자유확률, 퍼지이론, 가능성이론, 부정확률 및 양자확률입니다.
Reference
확률변수
확률이론 및 통계에서 임의의 양, 임의의 변수, 즉 확률변수는 비공식적으로 값이 임의의 현상의 결과에 의존하는 변수로 설명됩니다. 확률변수에 대한 공식적인 수학적 설명은 확률이론의 주제입니다. 그 맥락에서, 확률변수는 결과가 일반적으로 실수인 확률공간에서 정의된 측정 가능한 함수로 이해할 수 있습니다.
확률변수의 가능한 값은 아직 수행되지 않은 실험의 가능한 결과 또는 이미 존재하는 값 불확실한 과거 실험의 가능한 결과인 경우를 나타내는 이미 존재하는 값으로 나타낼 수 있습니다 (예 : 부정확한 측정 또는 양자 불확실성으로 인해). 그들은 또한 개념적으로 “객관적”무작위 과정의 결과 또는 양에 대한 불완전한 지식으로 인한 “주관적인”무작위성”을 나타낼 수 있습니다. 확률변수의 잠재 가치에 할당된 확률의 의미는 확률 이론 자체의 일부가 아니며 확률의 해석에 대한 철학적 주장과 관련이 있습니다. 수학은 사용되는 특정 해석과 상관없이 동일하게 작동합니다.
함수로서 확률변수는 측정 가능해야 하며 확률은 잠재가치 집합으로 표현할 수 있습니다. 결과는 예측할 수 없는 몇 가지 물리적 변수에 달려 있을 수 있습니다. 예를 들어, 공정한 동전 던지기의 경우, 앞면 또는 뒷면의 최종 결과는 불확실한 동전의 물리적 조건에 달려 있습니다. 관찰되는 결과는 확실하지 않습니다. 동전의 표면에 균열이 생길 수 있지만 이러한 가능성은 고려 대상에서 제외됩니다.
확률변수의 존재 지역은 표본공간이며 임의의 현상의 가능한 결과의 집합으로 해석됩니다. 예를 들어, 동전 던지기의 경우 두 가지 가능한 결과, 즉 앞면 또는 뒷면이 그러합니다.
확률변수는 확률분포를 가지며, 확률분포는 확률변수의 확률값을 지정합니다. 무작위 변수는 이산형일 수 있습니다. 즉, 임의의 변수의 확률분포의 확률 질량함수 특성이 부여된 유한한 값 또는 계산 가능한 값에서 하나를 취합니다. 또는 임의의 변수의 확률분포의 특징 인 확률밀도함수를 통해 간격 또는 연속된간격에서 임의의 수치 값을 취하는 연속 또는 두 유형의 혼합물 일 수 있습니다.
동일한 확률분포를 갖는 두 개의 확률 변수는 다른 확률 변수와의 관련성 또는 독립성 측면에서 다를 수 있습니다. 무작위 변수의 실현, 즉 변수의 확률분포 함수에 따라 무작위로 값을 선택한 결과를 무작위 변수라고 합니다.
Reference
4.2. 참조