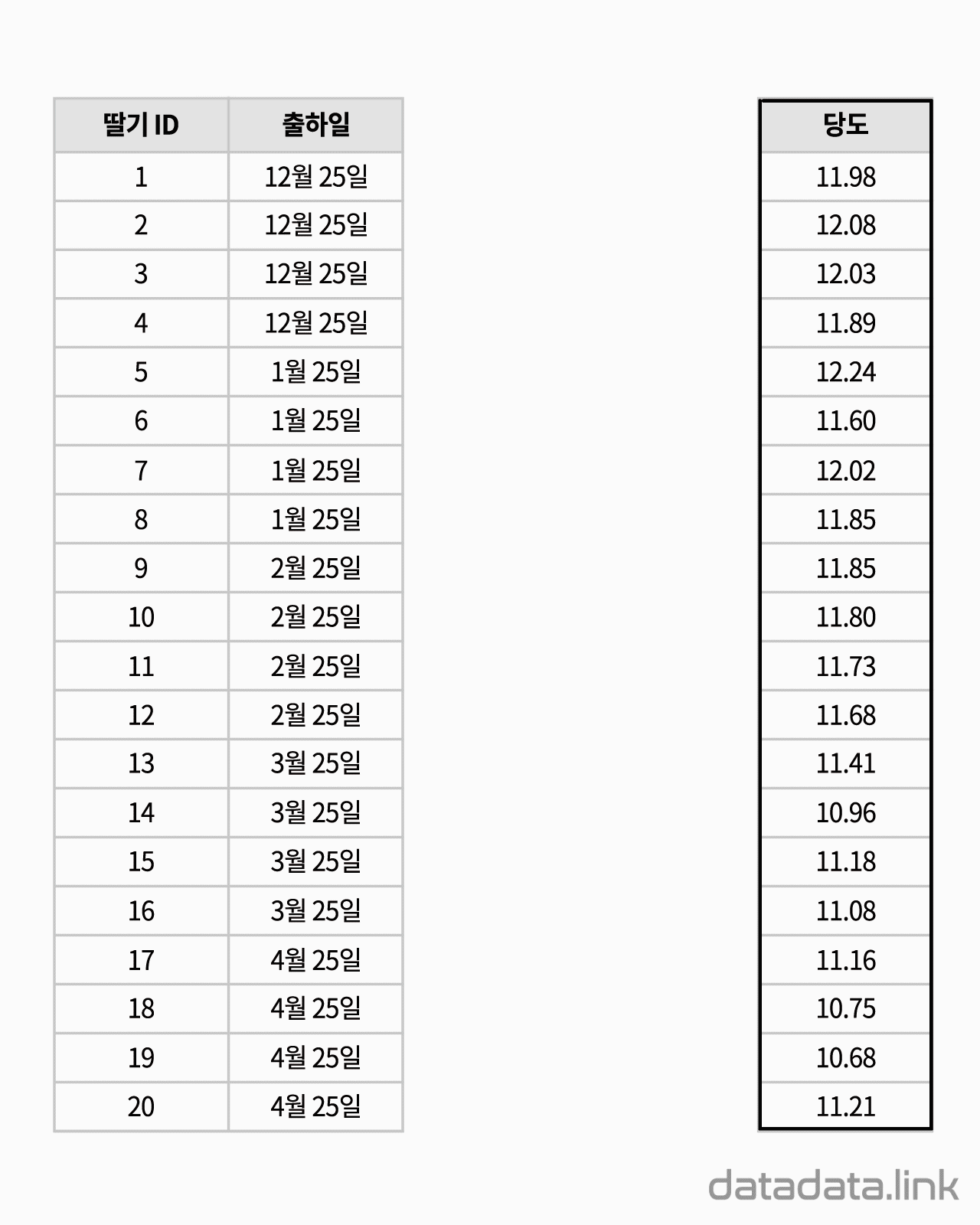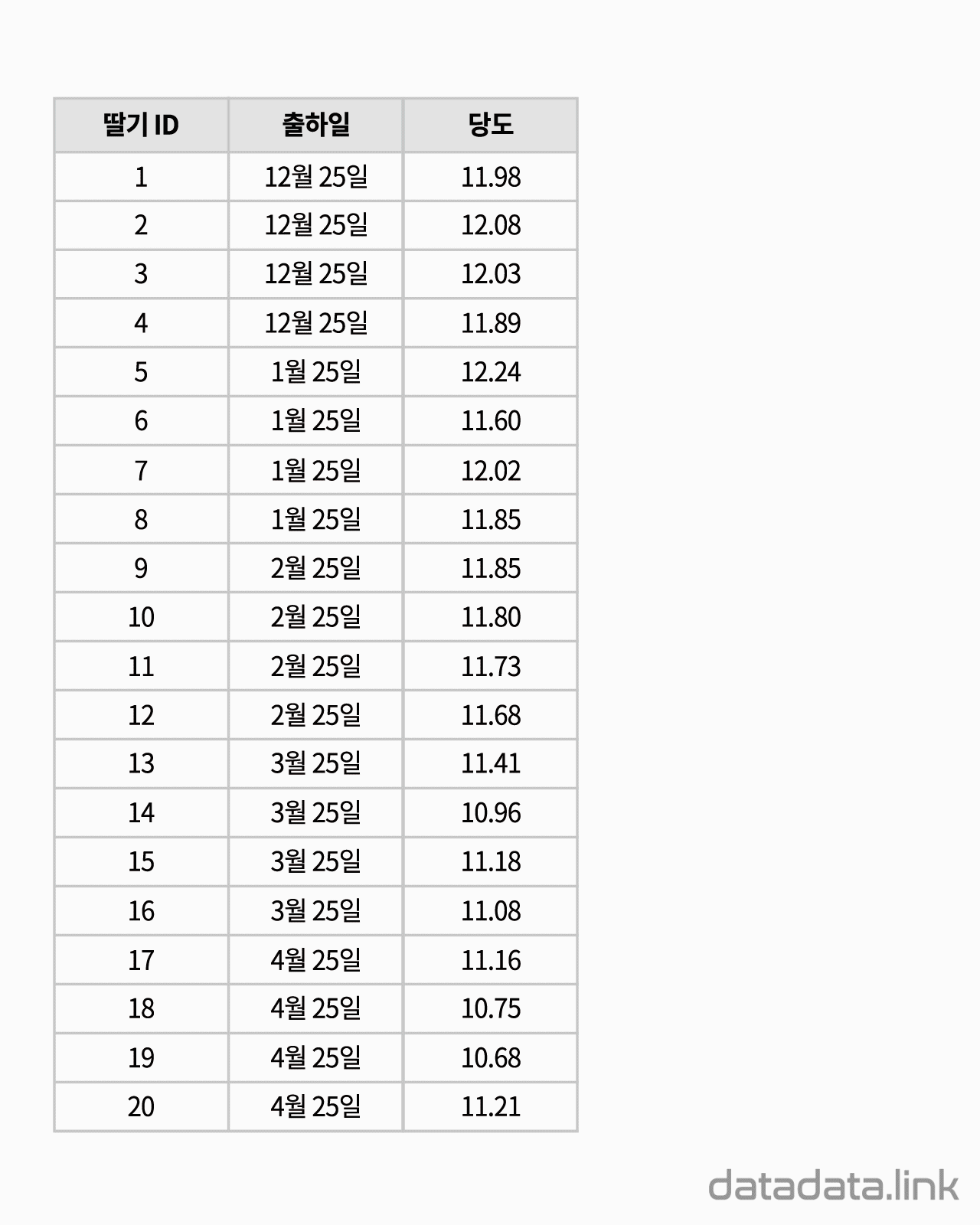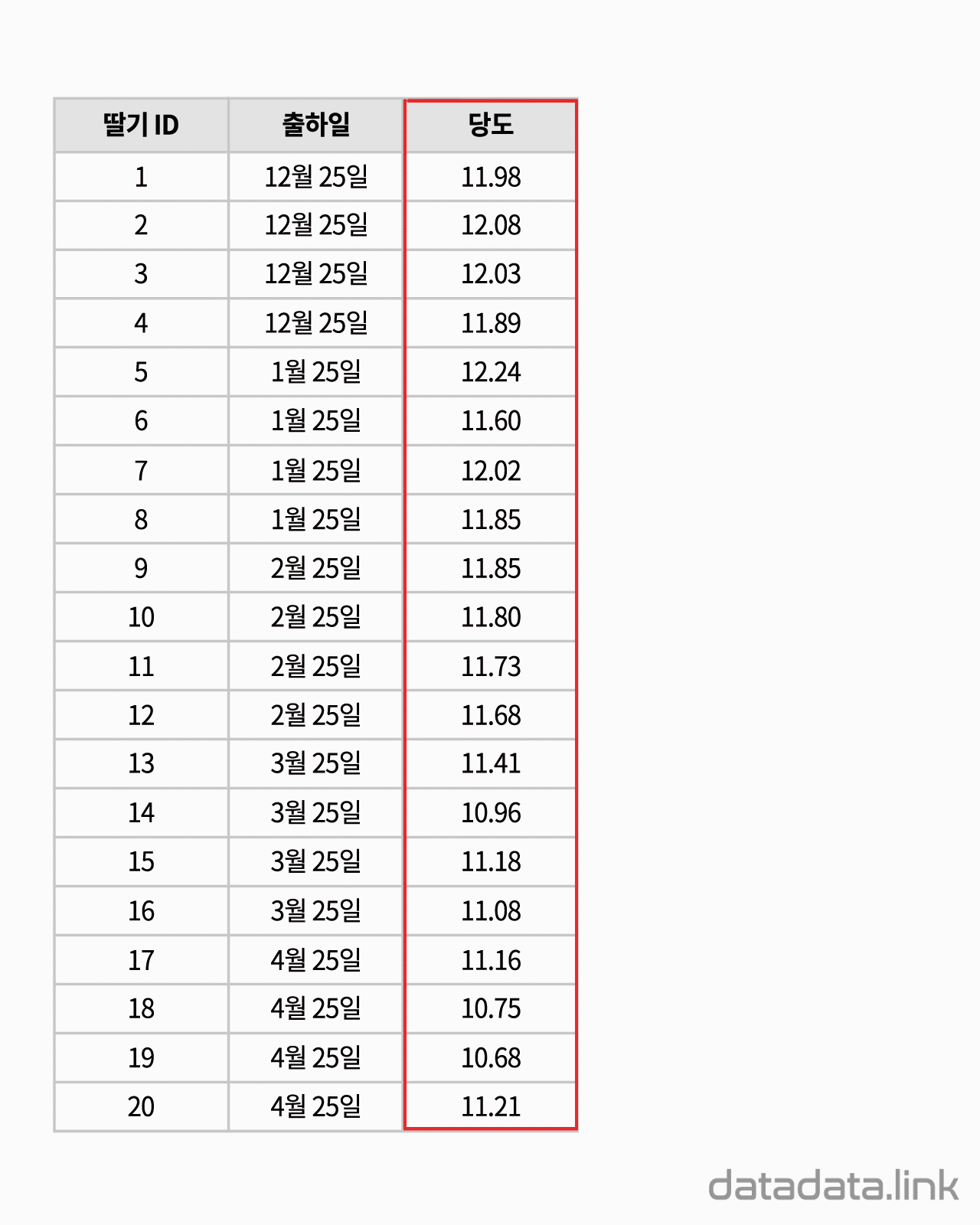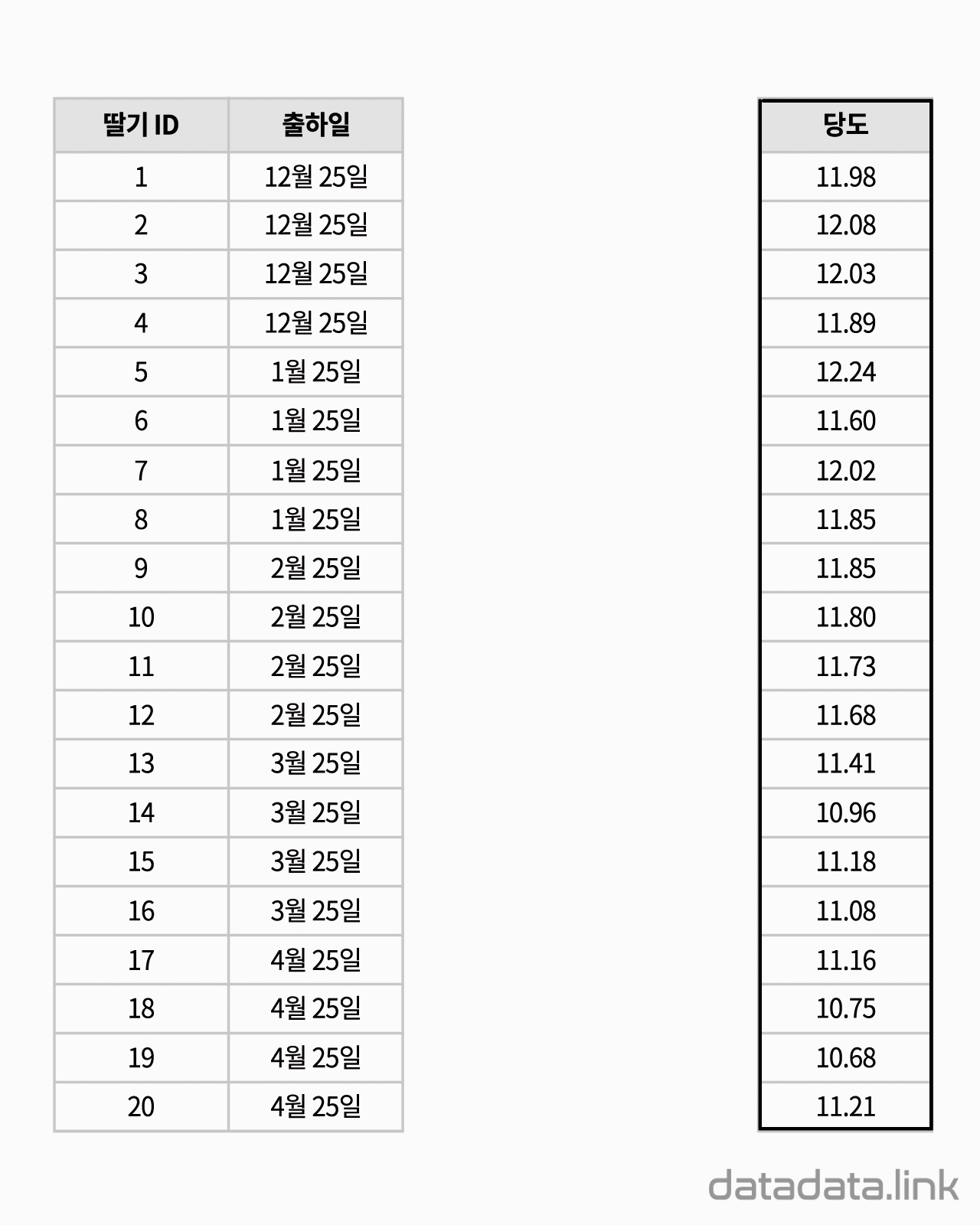
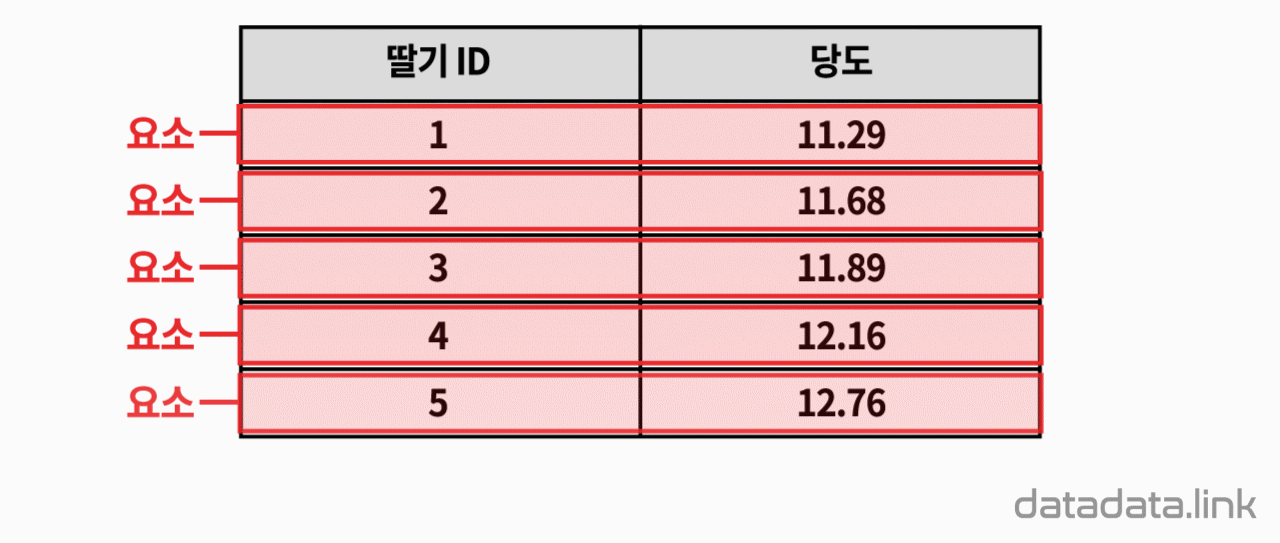
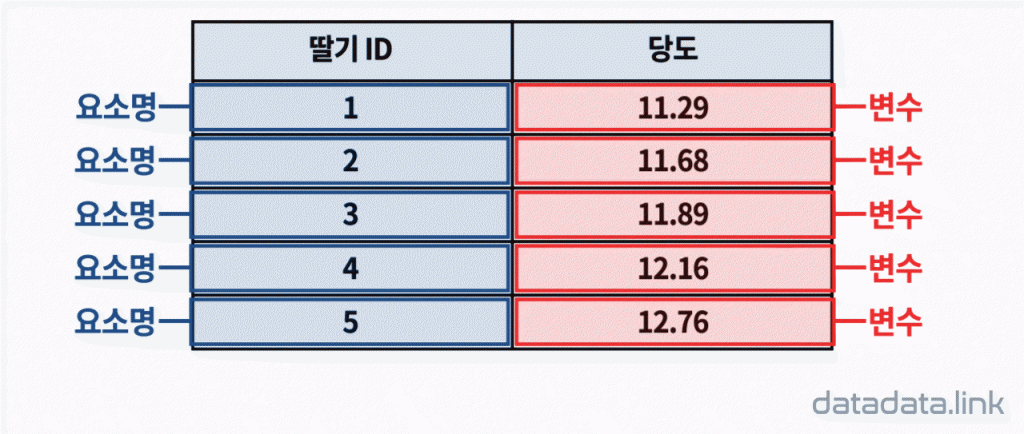
문항반응 척도
Item response scale
1.1. 문항속성(True, False)에 대한 반응(Positive & Negative)
4.1. 용어
1. 애니메이션

문항속성(True, False)에 대한 반응(Positive & Negative)
2. 설명
2.1. 문항반응에서 사용하는 척도유형
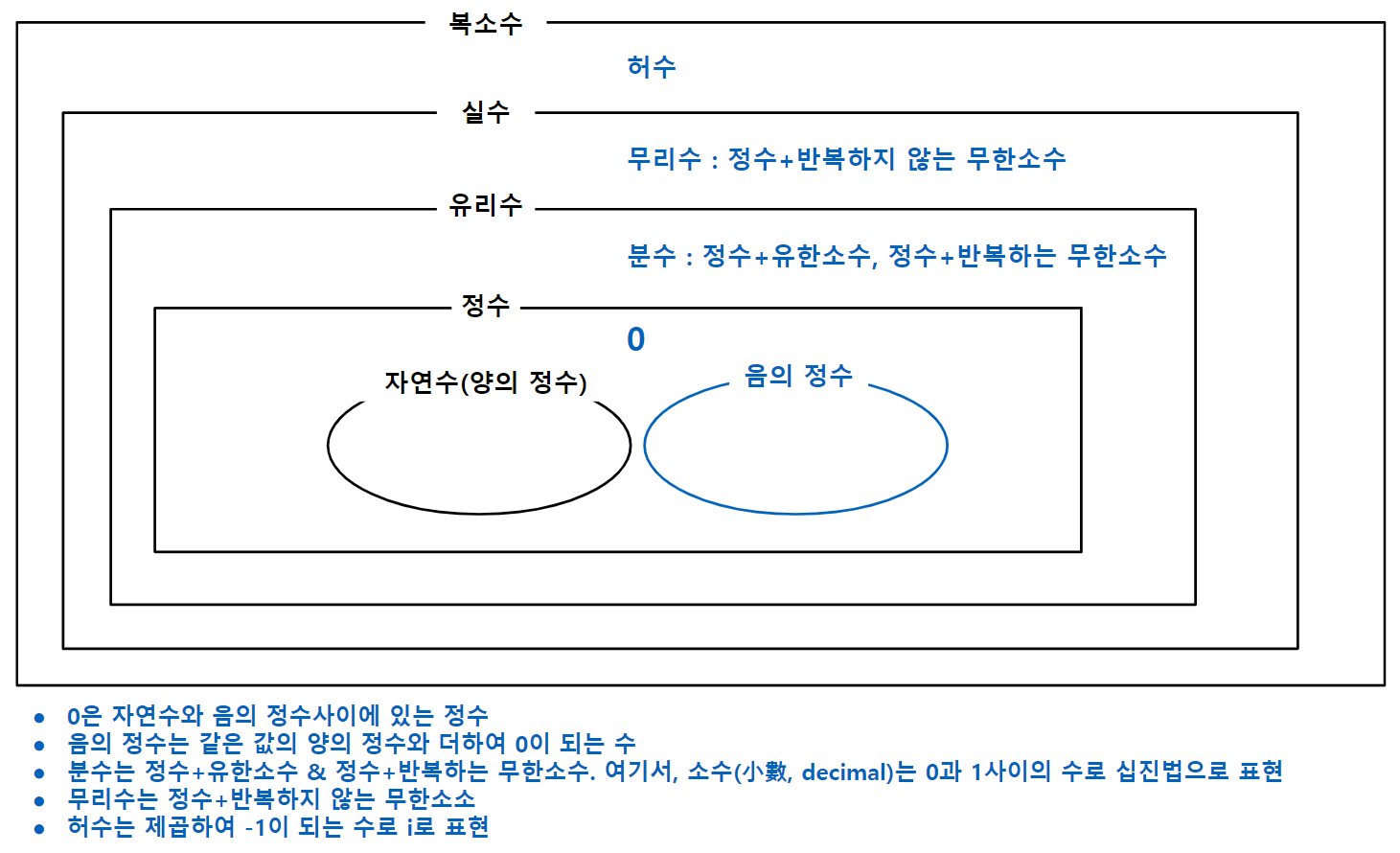
문항반응에서는 응답자가 문항에 반응한 결과가 결과변수가 되는 경우와 응답자의 능력과 문항의 난이도가 반응하여 결과가 나오는 경우가 있습니다. 전자의 원인변수는 응답자의 속성이며 후자의 원인변수는 응답자의 능력과 문항의 난이도의 차이입니다. 이 때 응답자의 능력과 문항의 난이도는 같은 속성입니다. 원인변수가 되는 응답자의 속성과 응답자의 능력과 문항난이도는 명목척도를 순서척도, 간격척도, 비례척도로 변환할수록 더 많은 분석을 할 수 있습니다. 즉, 원인변수값을 질적데이터에서 양적데이터로 얻으려는 노력을 하게 됩니다.
명목척도
명목척도(nominal scale)는 불연속적인 개념이나 속성을 측정하기 위한 척도입니다. 이러한 척도에서는 각 명명된 항목이 서로 독립적이며, 순서나 계량적인 의미를 가지지 않습니다. 예를 들어 명목척도에는 성별, 종교, 국적 등이 있습니다. 예를 들어 명목척도인 성별에는 “남”과 “여”라는 두 범주(척도점)가 있습니다.
순서척도
순서척도(ordinal scale)는 명목척도와 다르게 범주(척도점)의 비교가 가능합니다. 비교를 통해 순서(순위)를 정할 수 있는 데 순서는 내림차순이거나 오름차순처럼 방향이 있습니다. 하지만 범주들 사이에는 순서만 있을 뿐 계량화된 간격이 없습니다. 예를 들어 등급, 선호도, 학점 등이 있습니다.
간격척도
간격척도(interval scale)는 순서척도의 범주의 최대값이 정의되는 척도입니다. 각 범주의 최대값 사이에는 간격이 있고 그 간격은 계량할 수 있음을 의미합니다. 따라서 간격척도는 범주의 상대 위치를 나타냅니다. 예를 들어 섭씨온도, 지능지수, 연도 등이 있습니다.
비례척도
비례척도(ratio scale)는 간격척도에 존재의 없음을 의미하는 0이 부가되어 위치의 기준으로 사용됩니다. 0으로부터의 거리는 양이며 간격척도가 음수와 양수로 순서가 표현되는 것에 비해 비례척도에서는 양이 없음(존재하지 않음)을 의미하는 0이 있습니다. 양의 기준인 1로 관측대상의 양(quantity)을 표현합니다. 관측대상의 양이 0과 1사이에 있을 때 기준인1을 나눔으로 표현합니다. 그리고 기준보다 큰 경우에는 기준의 배수와 0과 1사이의 값의 합으로 표현합니다. 비례척도는 양의 기준인 1에 비례하는 값을 척도로 가진다고 할 수 있습니다. 비례척도는 양(quantity)을 나타내므로 양의 실수(positive real number)의 수체계로 나타냅니다. 예를 들어, 절대온도, 나이, 몸무게, 소득 등이 있습니다.
2.2. 순서척도의 분류
5점척도와 7점척도
순서정보가 있는 명목(이름)으로 표현하는 척도점의 수를 많게 하면 척도가 응답자들을 판별할 수 있는 능력은 커지지만, 응답자는 응답이 어려워지는 단점이 있습니다. 척도점의 수를 작게 하면 척도점간의 상관은 작아지는 장점이 있습니다. 척도점의 수가 소수(prime number)인 5점척도와 7점척도가 주로 사용됩니다.
짝수점척도와 홀수점척도
짝수점척도는 척도점의 수가 짝수인 척도로 중간점이 없으며 대칭을 만들기가 어렵습니다. 홀수점척도는 중간점이 있어서 대칭이지만 응답자의 응답이 심리적인 이유로 중간점으로 쏠릴 가능성이 높습니다. 일반적으로 짝수점척도보다 홀수점척도가 더 많이 쓰입니다.
균형척도와 불균형척도
균형척도는 긍정적 의미를 갖는 척도점의 수와 부정적 의미의 척도점의 수가 같은 척도입니다. 응답자가 편견이 없을 때 유용합니다. 불균형척도는 응답자가 편견이 있어 응답이 중간점을 기준으로 어느 한쪽으로 치우칠 경우, 편견을 보정해 주기 위하여 사용합니다.
단일항목척도와 다항목척도
단일항목척도는 한 항목(item)으로 구성되어 있습니다. 다항목척도는 한 질문과 다수의 항목으로 구성되어 있습니다.
단일항목척도의 예
질문(question) : A음식점의 맛은 ?
항목(item) : 좋다.
선택지(option) : 동의한다. – 동의하지 않는다.
단일항목척도의 예
항목(item) : A음식점의 맛은 좋다
선택지(option) : 동의한다. – 동의하지 않는다.
다항목척도의 예
질문(question) : 생일축하연 장소로 A음식점은 ?
항목(item) 1 : 음식이 맛있다.
선택지(option) : 매우 그렇다. – 그렇다. – 보통이다. – 그렇지 않다. – 매우 그렇지 않다.
항목(item) 2 : 경제적이다.
선택지(option) : 매우 그렇지 않다. – 그렇지 않다. – 보통이다. – 그렇다. – 매우 그렇다.
항목(item) 3 : 교통이 좋다.
선택지(option) : 매우 그렇지 않다. – 그렇지 않다. – 보통이다. – 그렇다. – 매우 그렇다.
다항목척도에서의 단방향척도와 혼합형척도
다항목척도에서 항목의 긍정과 부정의 방향이 일치하면 단방향척도이고 혼재되어있으면 혼합형 척도입니다.
척도점의 강도표현
척도점이 “좋다”, “나쁘다”, “보통이다”인 경우 강도표현은 매우, 약간 등등이 있을 수 있습니다. 이 때 강도는 중간점을 기준으로 양쪽으로 대칭적으로 부여하는 것이 좋으나 척도점의 표현이 길어져서 정확하고 효율적인 실험을 어렵게 합니다. 부가되는 의미가 강할수록 응답자는 극단 값을 피하기 위해 가운데로 몰리는 경향이 있습니다.
2.3. 문항반응을 관측하는 척도의 종류
질문(question)과 항목(item)을 합해서 문항(question & item)이라고 합니다. 선택지는 문항에 대한 응답의 범주를 반응의 정도에 따라 순서대로 나열한 것입니다. 그리고 문항반응은 선택지에서 문항에 대한 응답 범주를 선택하는 것을 의미합니다. 따라서 문항과 선택지를 합한 것을 순서척도라고 할 수 있습니다.
리커트척도 (Likert scale)
어떤 항목(진술)에 대해 응답자가 동의하거나 동의하지 않는 정도를 표시하도록 하는 척도입니다. 척도점은 응답을 나타내는 범주인 응답범주의 이름입니다. 따라서 척도점의 수는 응답범주의 수와 같습니다. 순서척도를 간격척도로 바꾸면 순서척도의 척도점은 범주의 최대값을 의미하며 양적데이터입니다. 정리하면 리커트척도를 순서척도에서 간격척도화 했을 때, 간격척도의 구간은 순서척도에서의 척도점의 최대값으로 구분됩니다.
리커드척도 예
질문 : A서비스센터 직원들의 업무태도는 ?
항목 : A서비스센터 직원들은 친절하다.
척도점 : 전혀 동의하지 않는다. $\cdots$ 전적으로 동의한다.
의미차별화척도 (semantic differential scale)
서로 반대되는 의미의 말을 양쪽 끝의 척도점(응답범주)에 표현한 척도입니다. 예를 들면 불공정과 공정, 불친절과 친절, 비상식과 상식 등이 있습니다.
의미차별화척도 예
질문 : A서비스센터 직원들은 ?
척도점 : 불친절하다. $\cdots$ 친절하다.
등급척도 (rating scale)
등급을 척도점(응답범주)으로 가지는 척도로써 “중요성 등급척도”, “평가 등급척도”, “Stapel 등급척도” , “서열 등급척도”, “비교 등급척도” 등 여러가지 방식이 있습니다.
Stapel 등급척도 예
질문 : A서비스센터 직원들은 ?
척도점 : -3 -2 -1 친절하다 +1 +2 +3
2.4. 척도평가
관측값모델
관측값은 다음과 같이 모델링됩니다.
$$X_O=X_T + X_S + X_R$$
여기서, $X_O$는 관측값(measured value or observed value)
$X_T$는 실제값(true value)
$X_S$는 체계적 오류(systematic error)이며 척도의 오류
$X_R$은 비체계적 오류(nonsystematic error or random error)이며 관측자와 관환경에 따른 오류
타당성
척도의 타당성(validity)은 측정하고자 하는 대상인 개체의 속성이나 구성개념 등을 척도가 실제로 측정하는 정도입니다. 예를 들어, 지능을 측정하는 척도가 실제로 지능의 다양한 측면을 적절하게 나타낸다면, 그 척도는 그 지능에 대해 높은 타당성을 가진다고 할 수 있습니다. 척도의 타당성이 높을수록 체계적 오류가 작아집니다.
정확성
척도의 정확성(accuracy)은 측정값이 실제 값에 얼마나 가까운지를 나타냅니다. 예를 들어, 체온계가 실제 체온을 정확하게 측정한다면, 그 체온계는 높은 정확성을 가진다고 할 수 있습니다.
정밀성
척도의 정밀성(precision)은 측정값들의 차이를 얼마나 작은 값까지 나타낼 수 있는지의 정도입니다. 예를 들어, 관측값은 비체계적 오류(무작위 오류)의 영향을 받는 데 척도의 정밀도가 높으면 더 작은 비체계적 오류도 알 수 있게 됩니다.
신뢰성
척도의 신뢰성(reliability)은 한 대상을 반복 측정했을 때 동일한 결과를 얻는 정도를 말합니다. 비체계적 오류는 관측하는 사람이나 상황으로부터 발생하는 오류입니다. 비체계적 오류가 작을수록 그 척도의 신뢰성은 높습니다. 척도의 신뢰성에는 다음과 같은 것들이 있습니다.
– 반복측정 신뢰성(test-retest reliability)
반복측정 신뢰성은 같은 척도로 관측을 2회 실시하여 2회의 관측값들을 구하고 관측값들 간의 상관관계로 구한 척도의 신뢰성입니다. 상관계수가 크면 척도의 반복측정 신뢰성이 높다고 할 수 있습니다.
– 대안항목 신뢰성(alternative-form reliability)
한 척도로 측정하여 측정값들을 구하고 유사하지만 대안이 될수 있는 항목을 가진 척도로 다시 측정하여 관측값들 구합니다. 두 관측값집합의 상관계수로 척도의 대안항목 신뢰성을 평가합니다. 반복측정 신뢰성은 주시험효과가 작용할 수 있습니다. 주시험효과를 방지하기 위하여 두 번째 측정할 때 첫 번째 사용한 척도와 유사하지만 다른 척도를 사용합니다.
다항목척도의 내적 일관성
지능, 동기부여, 학습 태도 등을 구성개념(construct)라고 하는 데 심리학이나 교육학에서 관측하고자 하는 이론적인 개념입니다. 여기서, 한 구성개념을 측정하는 다항목척도는 항목들이 일관성을 가져야 합니다. 이 일관성을 “다항목척도의 내적 일관성(internal consistency)”이라고 합니다.
크론바흐계수 $\alpha$ (Cronbach’s coefficient $\alpha$)”는 다항목척도의 내적 일관성”을 표현하는 방법 중에서 가장 널리 쓰이는 방법입니다. 크론바흐계수는 다음식으로 구합니다.
$$\alpha=\dfrac{k}{(k-1)} \left( 1-\dfrac{\sum_\limits {i=1}^{k}\sigma_i^2}{\sigma_T^2}\right)$$
여기서, $k$는 항목 수
$\sigma_i^2$은 $i$번째 항목의 분산
$\sigma_T^2$은 전체 항목의 분산
다르게 표현하면
$$\alpha=\dfrac{k \bar r}{1+{\bar r}(k-1)}$$
여기서, $\bar r$은 항목간 상관계수의 평균
크론바흐계수 $\alpha$는 0 에서 1 사이의 값을 가지며, 높을수록 바람직합니다. 흔히 0.8에서 0.9 이상이면 만족할 수 있고 0.6에서 0.7이면 수용할 수 있습니다. $\alpha$계수가 매우 작으면 그 데이터는 내적 일관성을 결여한 것으로, 본 분석에서 사용할 수 없습니다. $\alpha$계수의 크기를 저해하는 항목들을 제거함으로써 계수값을 크게 할 수 있습니다.
항목의 수와 $\alpha$계수의 크기는 양의 상관입니다. 척도점의 수와 $\alpha$계수의 크기도 양의 상관입니다. 그러나 표본의 크기와 $\alpha$계수의 크기는 음의 상관입니다.
2.5. 척도개발
1) 개념정의 및 목표설정
척도를 개발하기 전에 먼저 관측하고자 하는 개념을 정의하고, 척도개발의 목표를 설정합니다. 이를 위해 선행연구조사와 인터뷰 등을 수행합니다.
2) 관측대상 분석
정의한 개념을 가진 관측대상을 분석합니다.
관측대상인 개체의 속성(특징, 특성)이나 범주의 속성(특징, 특성) 등을 분석하여 항목을 생성합니다.
3) 척도유형 결정
척도유형에 따라 개발 방법이 다르므로, 척도유형을 먼저 결정합니다.
4) 문항 생성
여러 개의 항목을 생성합니다.
항목생성 시 관측대상인 개체나 범주의 속성(특성)이나 관측목적, 관측방식 등을 고려해야 합니다.
도메인 내의 구성요소나 구성요소와 연결된 특성을 고려하고, 데이터수집을 위한 관측도구의 목적과 측정방식 등을 고려합니다.
5) 문항 검토 및 문항 수정
생성된 문항들에 대해 검토를 수행합니다. 이 과정에서 문항들의 유형, 내용, 언어 등을 확인하고, 중복된 문항, 혼란스러운 문항, 문맥에 부적합한 문항 등을 제거하거나 수정합니다.
6) 척도개발 및 척도검증
선정된 문항들을 기반으로 척도를 개발합니다. 척도 유형에 따라 척도 개발 방법이 다르며, 각 문항들의 가중치, 점수 범위, 객관적 테스트 등을 고려합니다. 이후, 개발된 척도를 검증하기 위해 신뢰성, 타당성, 일관성 등에 대한 검증을 수행합니다. 이를 위해 적절한 통계분석 방법을 사용합니다.
7) 보고서 작성
마지막으로, 개발된 척도와 검증결과에 대한 보고서를 작성합니다. 보고서는 척도의 개념, 목표, 유형, 개발과정 및 검증과정, 검증결과 등을 설명하며, 척도의 사용자들이 척도를 올바르게 사용할 수 있도록 지침서 등을 포함하여 작성합니다.
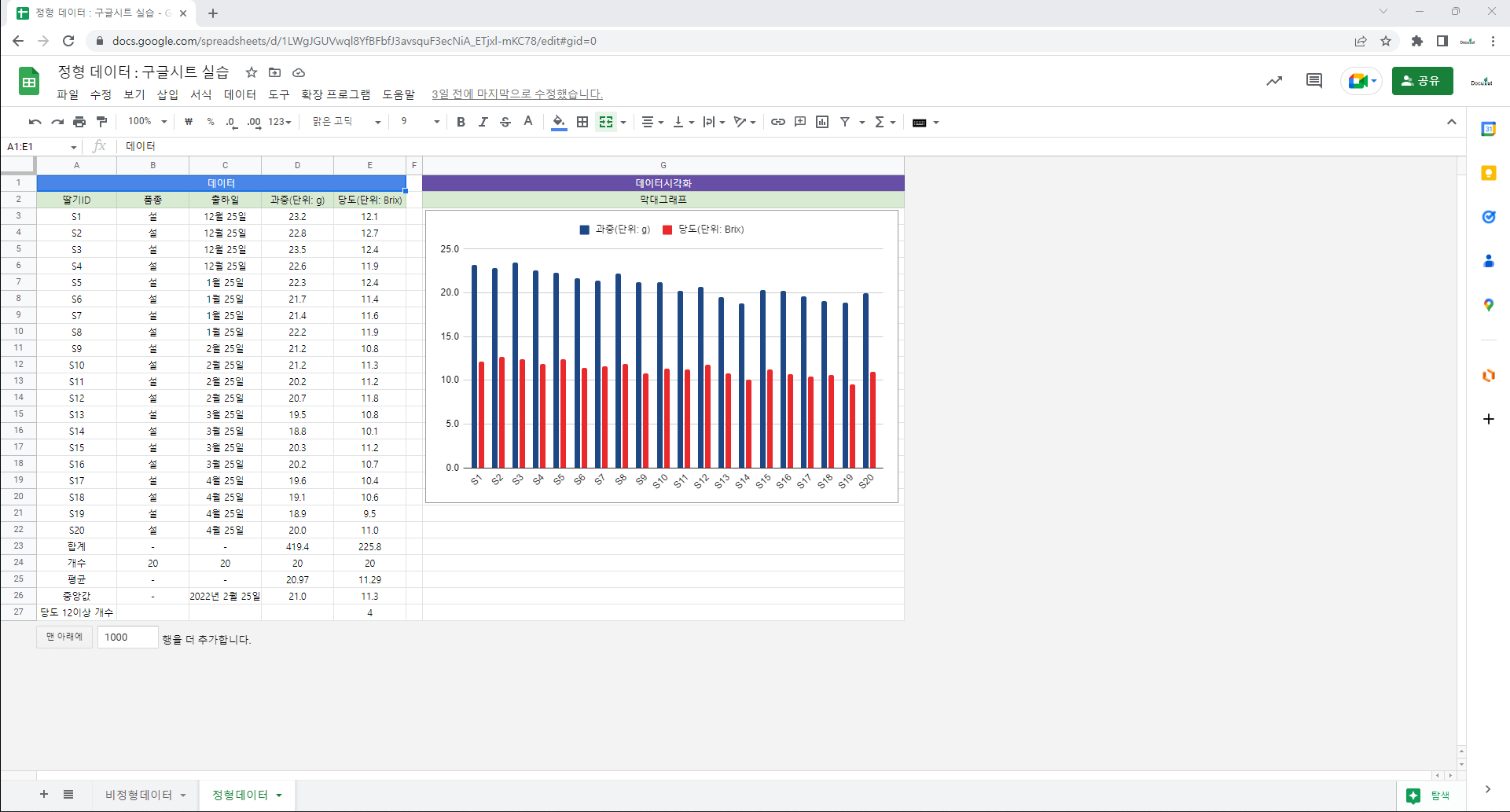
3. 실습

3.2. 함수
=ROWS(F2:F2) : 지정된 배열 또는 범위에 있는 행의 개수.
3.3. 실습강의
– 실습강의 목차

4. 참조
4.1 용어
데이터
데이터는 질적 또는 양적 변수값의 집합입니다. 데이터와 정보 또는 지식은 종종 같은 의미로 사용하지만 데이터를 분석하면 정보가 된다고 볼 수 있습니다. 데이터는 일반적으로 연구의 결과물로 얻어집니다. 한편, 데이터는 경제(매출, 수익, 주가 등), 정부(예 : 범죄율, 실업률, 문맹율)와 비정부기구(예 : 노숙자 인구 조사)등 다양한 분야에서도 나타납니다. 그리고 데이터를 수집 및 분석하고 시각화할 수 있습니다.
일반적인 개념의 데이터는 응용이나 처리에 적합한 형태로 표현되거나 코딩됩니다. 원시 데이터 (“정리되지 않은 데이터”)는 “정리”되기 전의 숫자 또는 문자의 모음입니다. 따라서 데이터의 오류를 제거하려면 원시 데이터에서 데이터를 수정해야 합니다. 데이터 정리는 일반적으로 단계별로 이루어지며 한 단계의 “정리 된 데이터”는 다음 단계의 “원시 데이터”가 됩니다. 현장 데이터는 자연적인 “현장”에서 수집되는 원시 데이터입니다. 실험 데이터는 관찰 및 기록을 통한 과학적 조사에서 생성되는 데이터입니다. 데이터는 디지털 경제의 새로운 자원입니다.