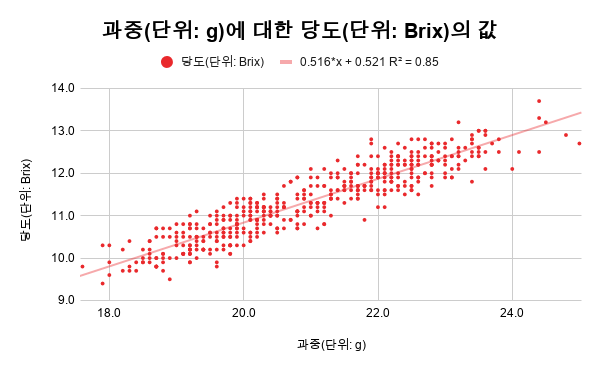
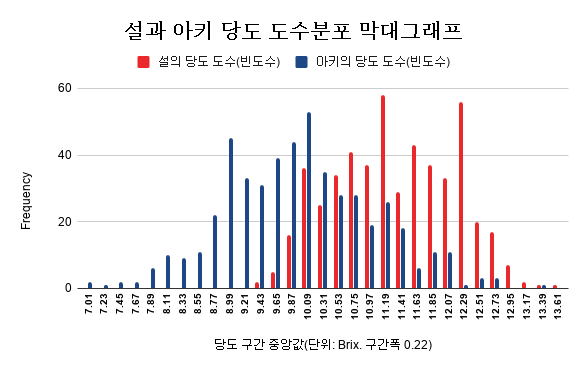
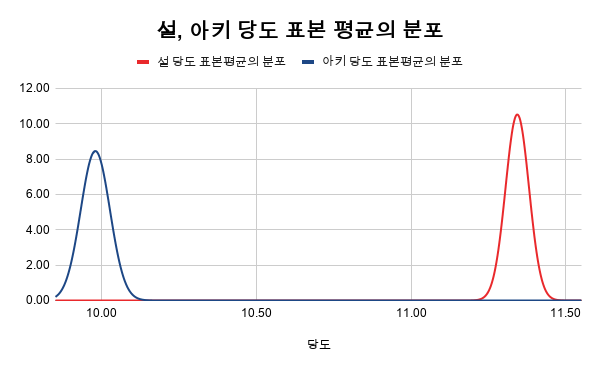
엑셀로 딸기의 당도와 과중 상관관계를 분석할 수 있을까요?

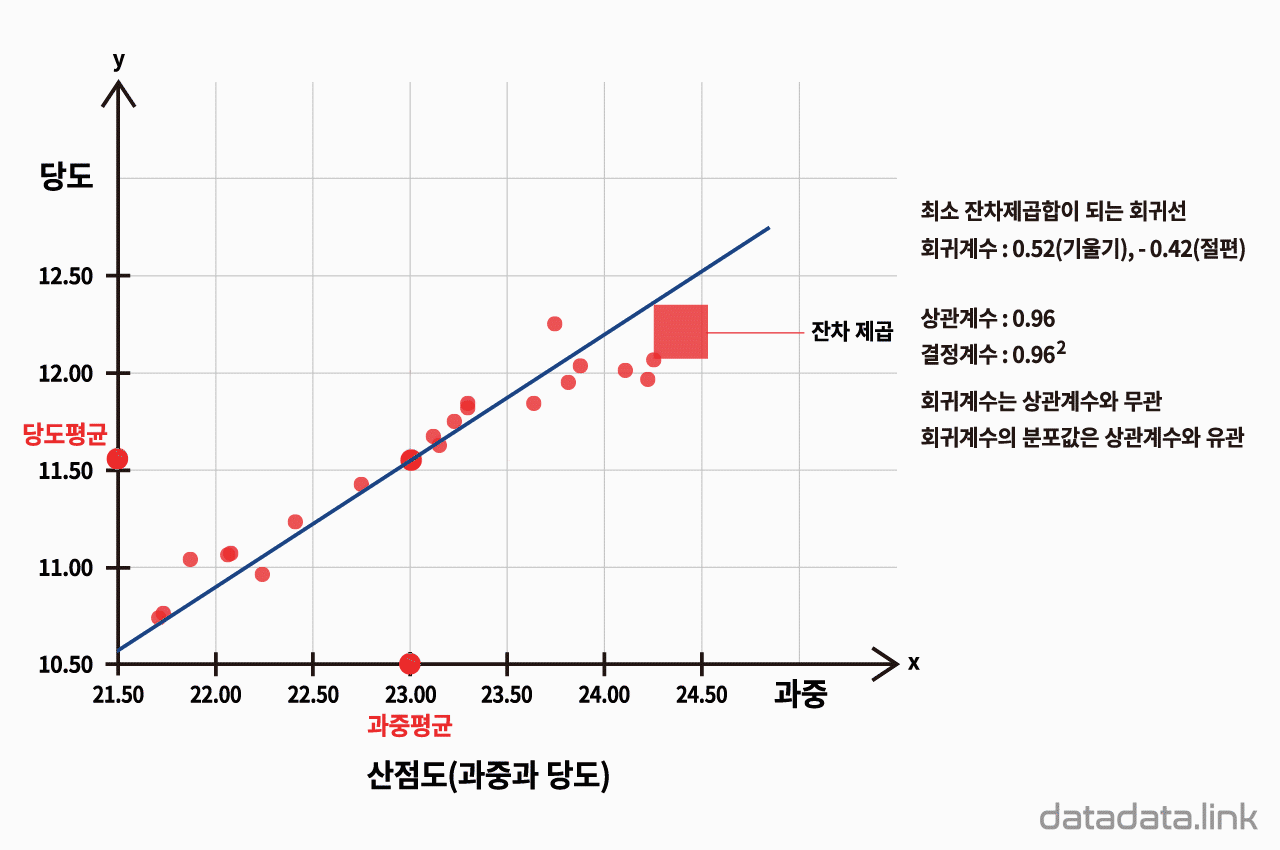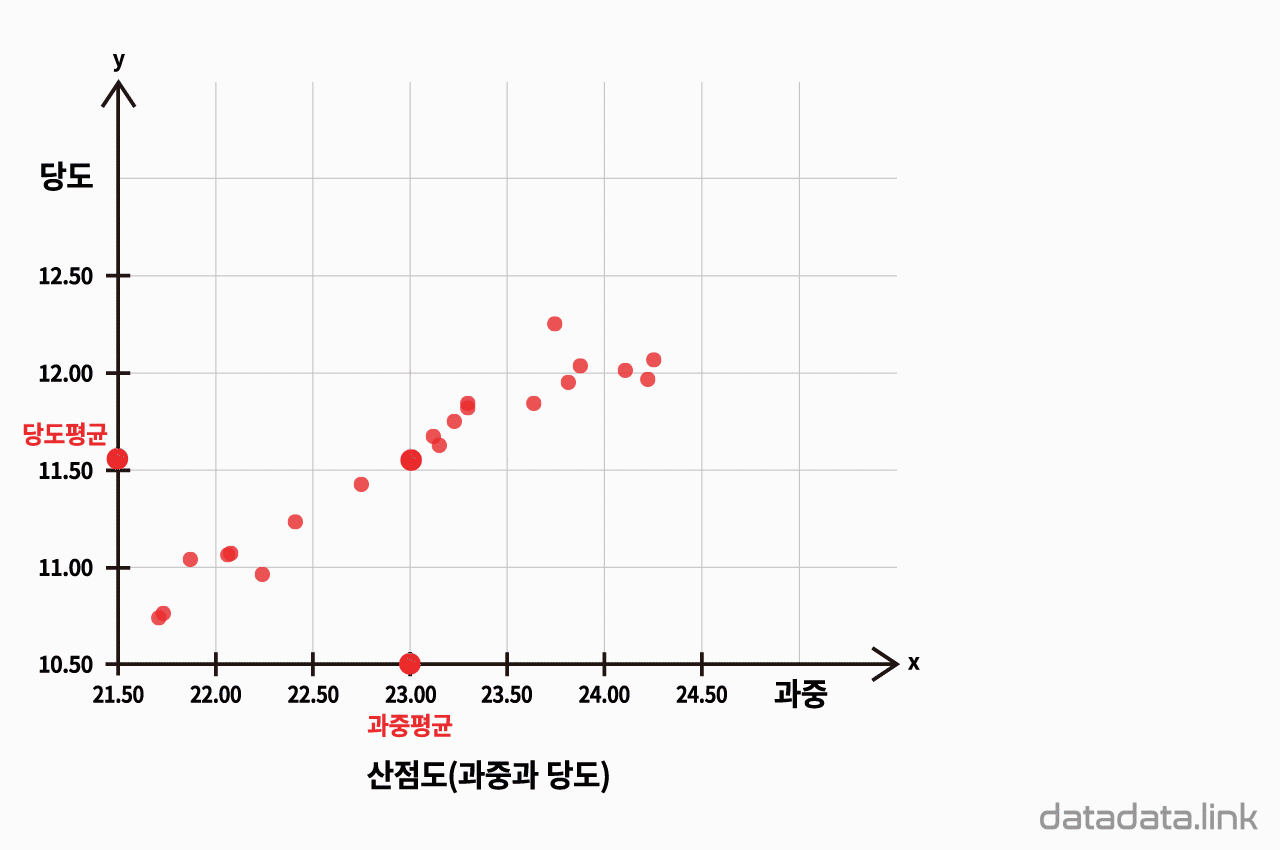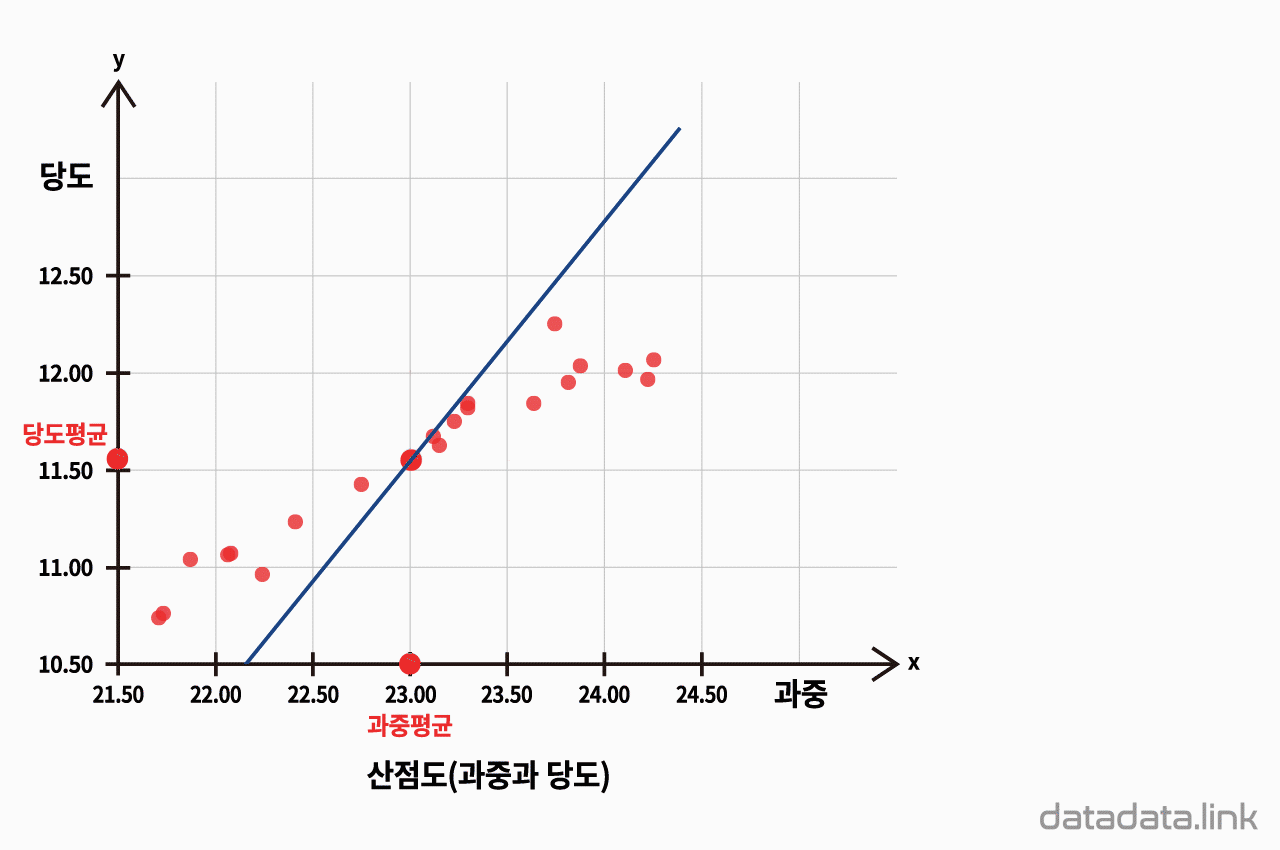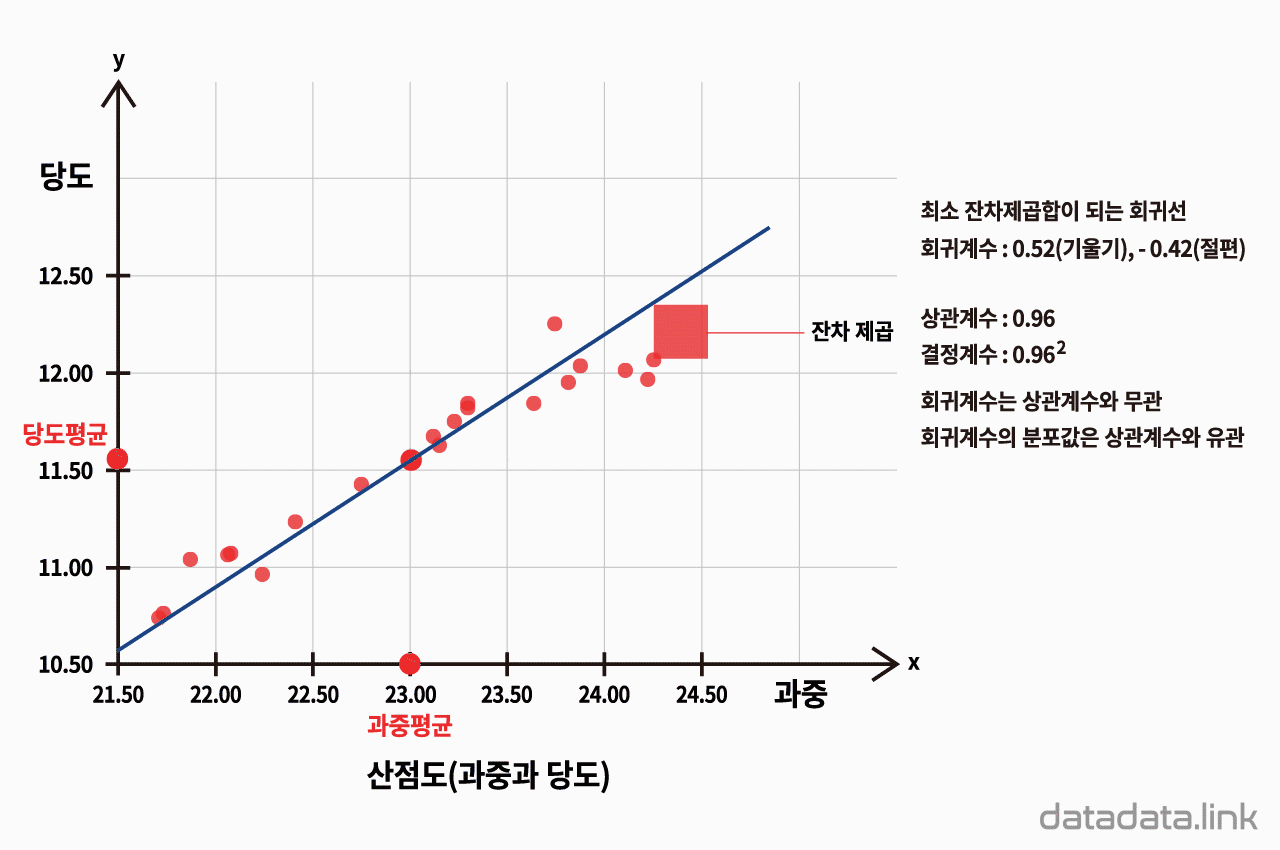
산점도(과중과 당도)
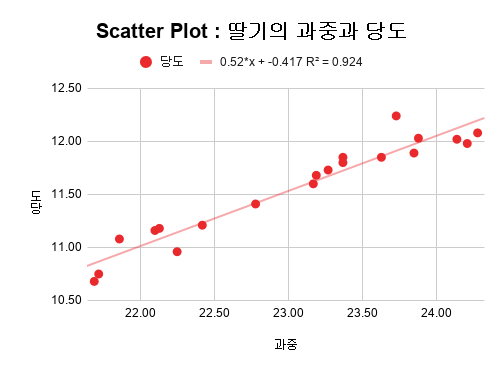
산점도와 회귀선
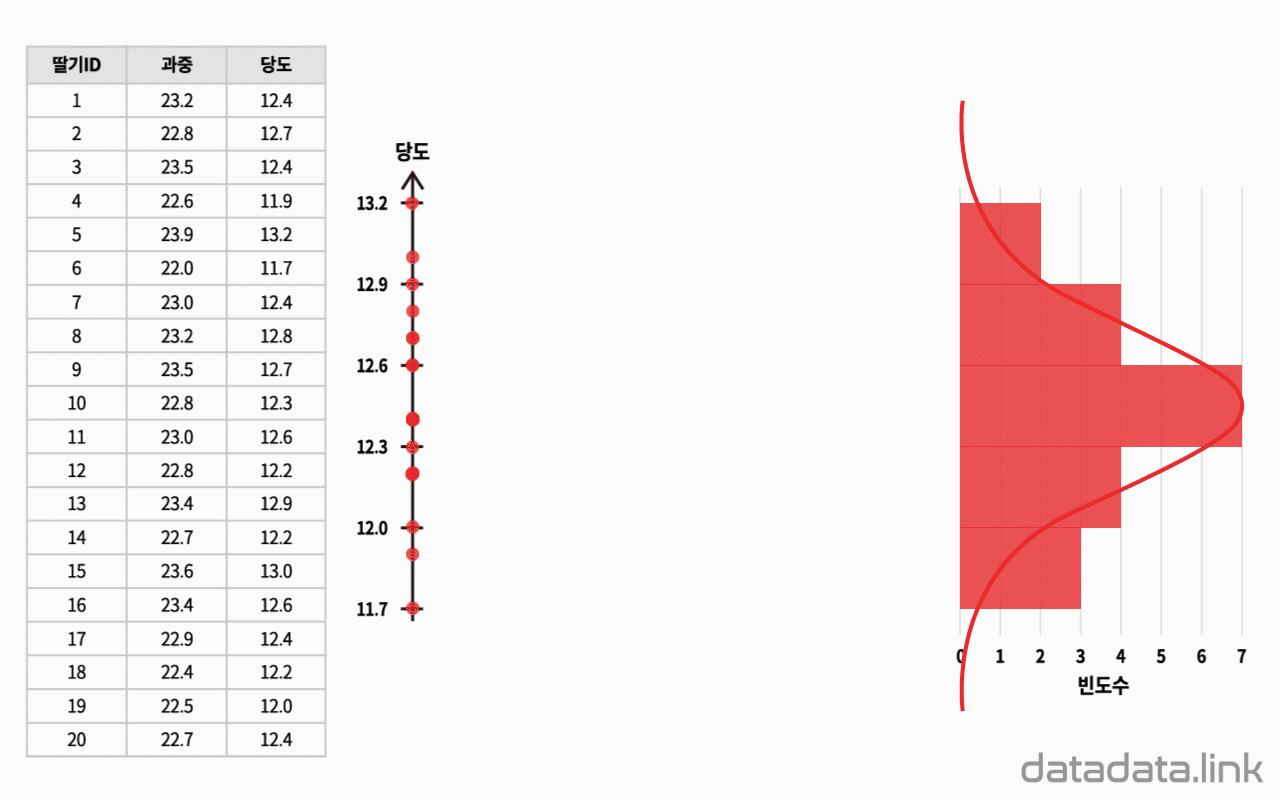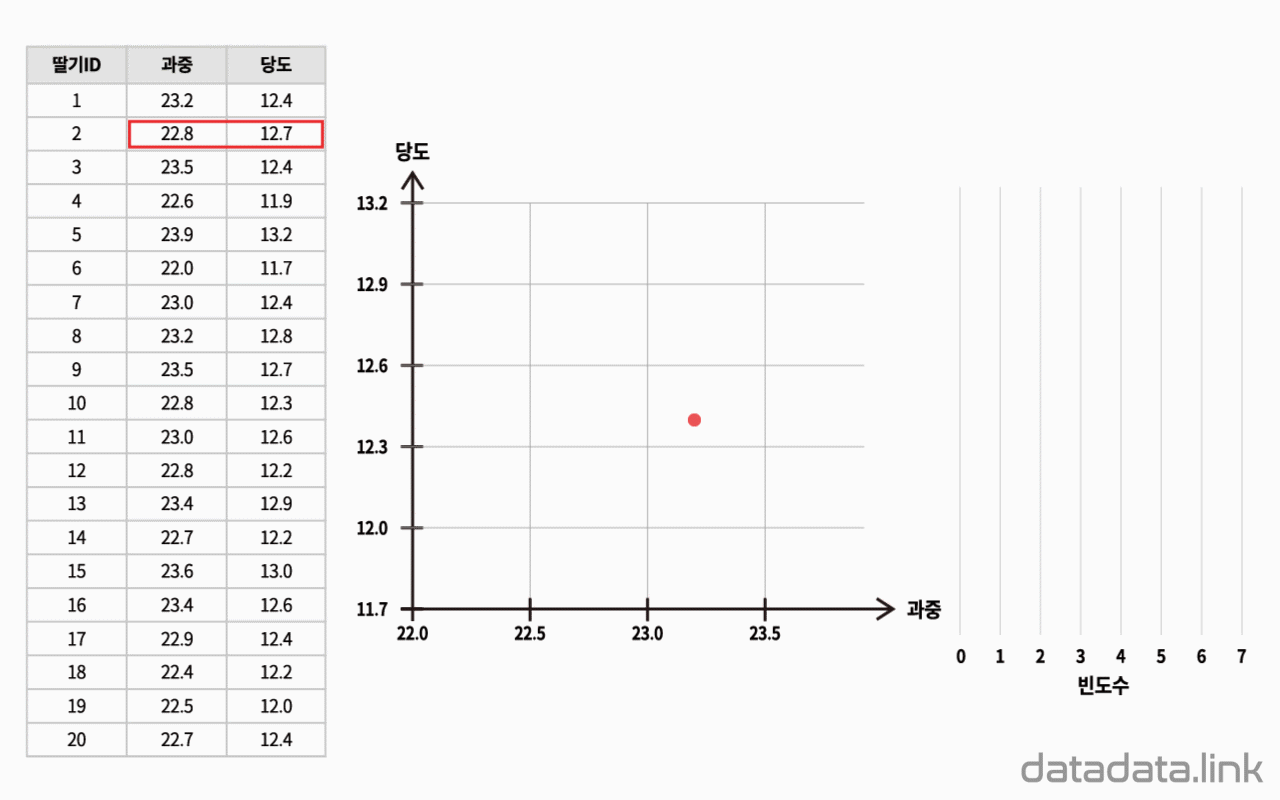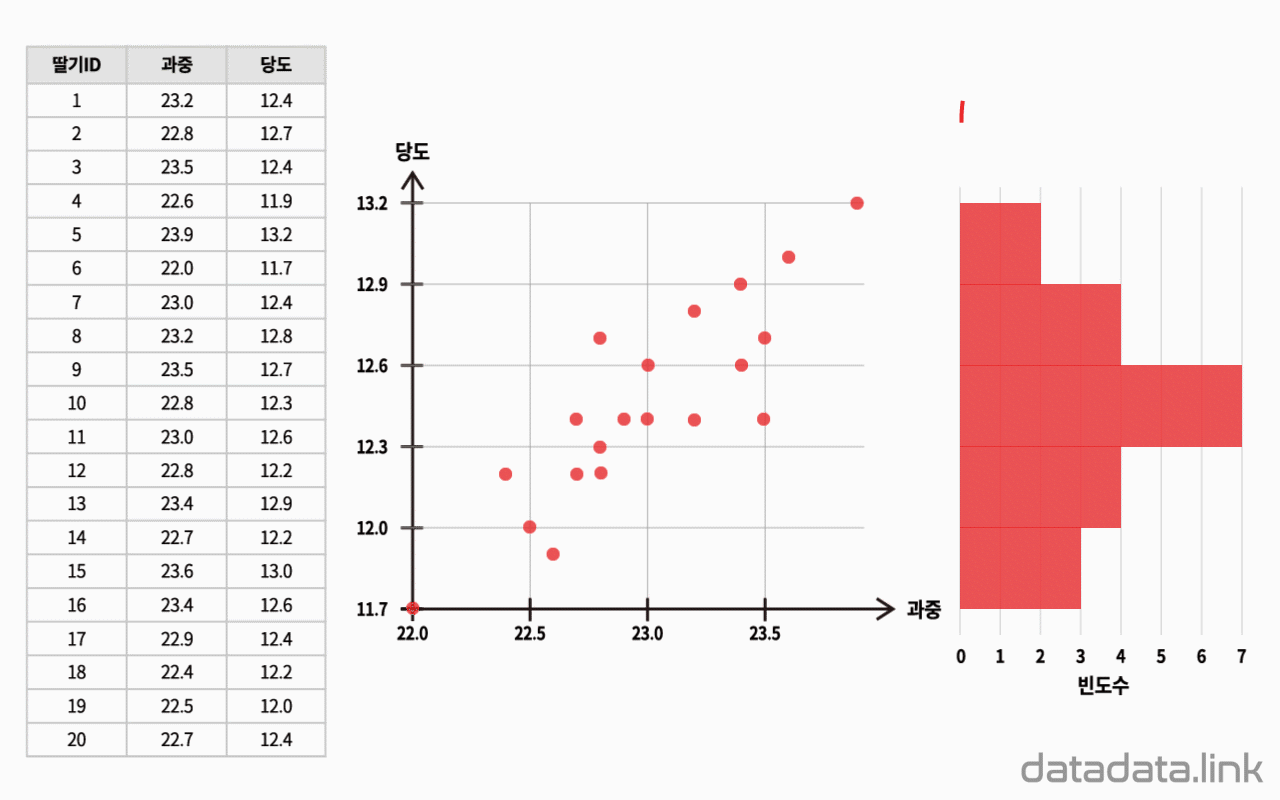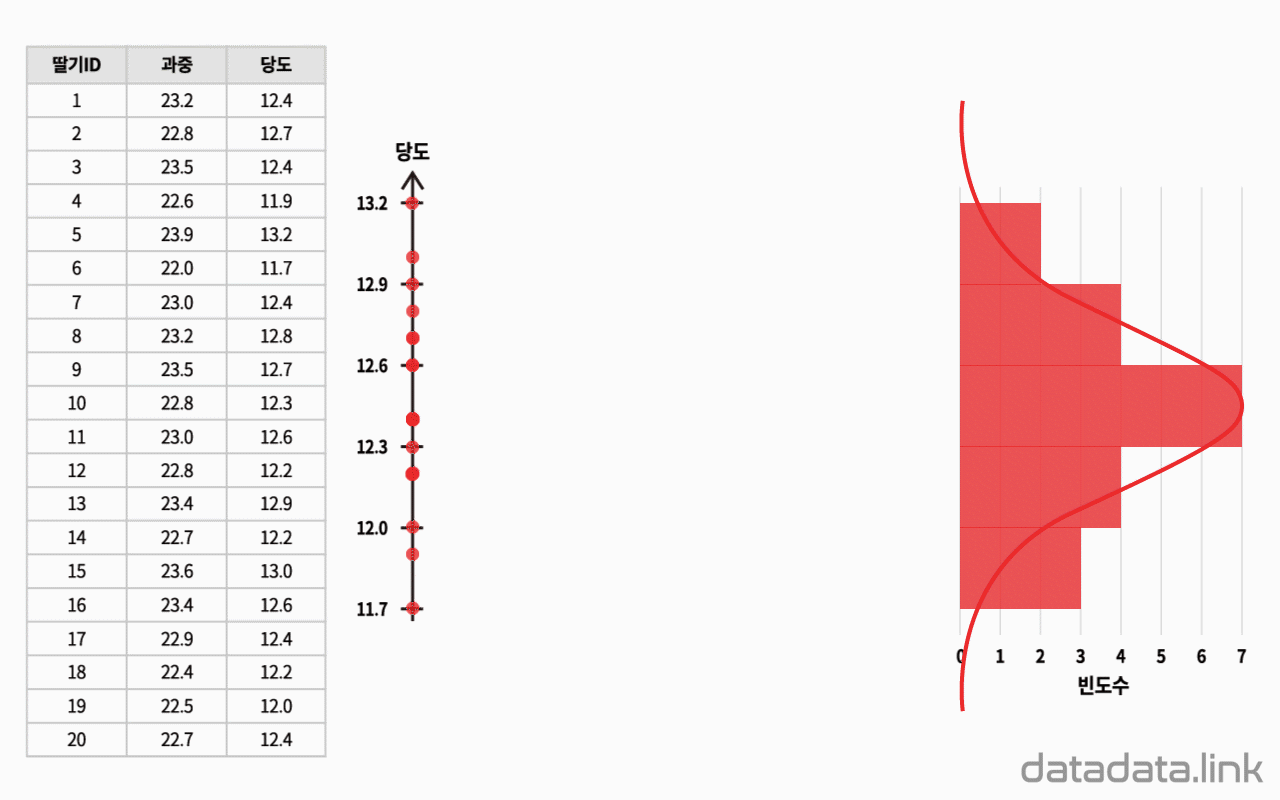
딸기의 과중과 당도를 측정하고, 엑셀을 이용하여 평균과의 편차를 구한 후 상관계수를 계산합니다.
엑셀은 별도의 프로그램 설치가 필요합니다. 여기에서는 엑셀과 사용방법이 동일한 구글시트로 딸기의 당도와 과중의 상관관계를 분석해보겠습니다. Chrome에서 아래의 구글시트 가져가기를 하시면, 직접 실습을 해보실 수 있습니다.

딸기의 과중과 당도의 대표값을 구하고, 각 딸기의 과중과 당도가 평균으로부터 얼마나 차이가 나는지를 구합니다.
average 함수를 이용해서, 과중과 당도의 대표값 중 산술평균을 구합니다. 각 딸기의 당도와 당도 평균, 과중과 과중 평균의 편차를 각각 구합니다.
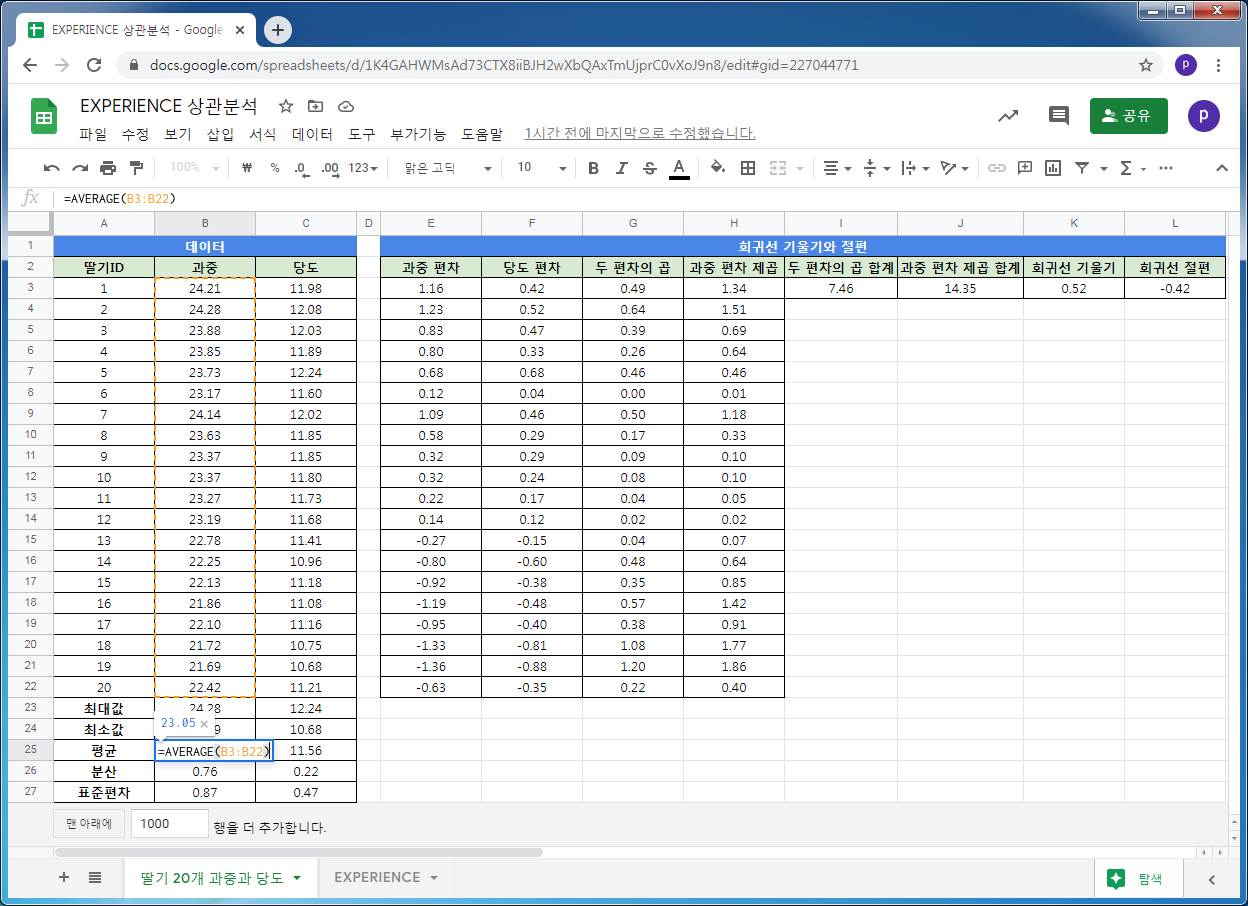
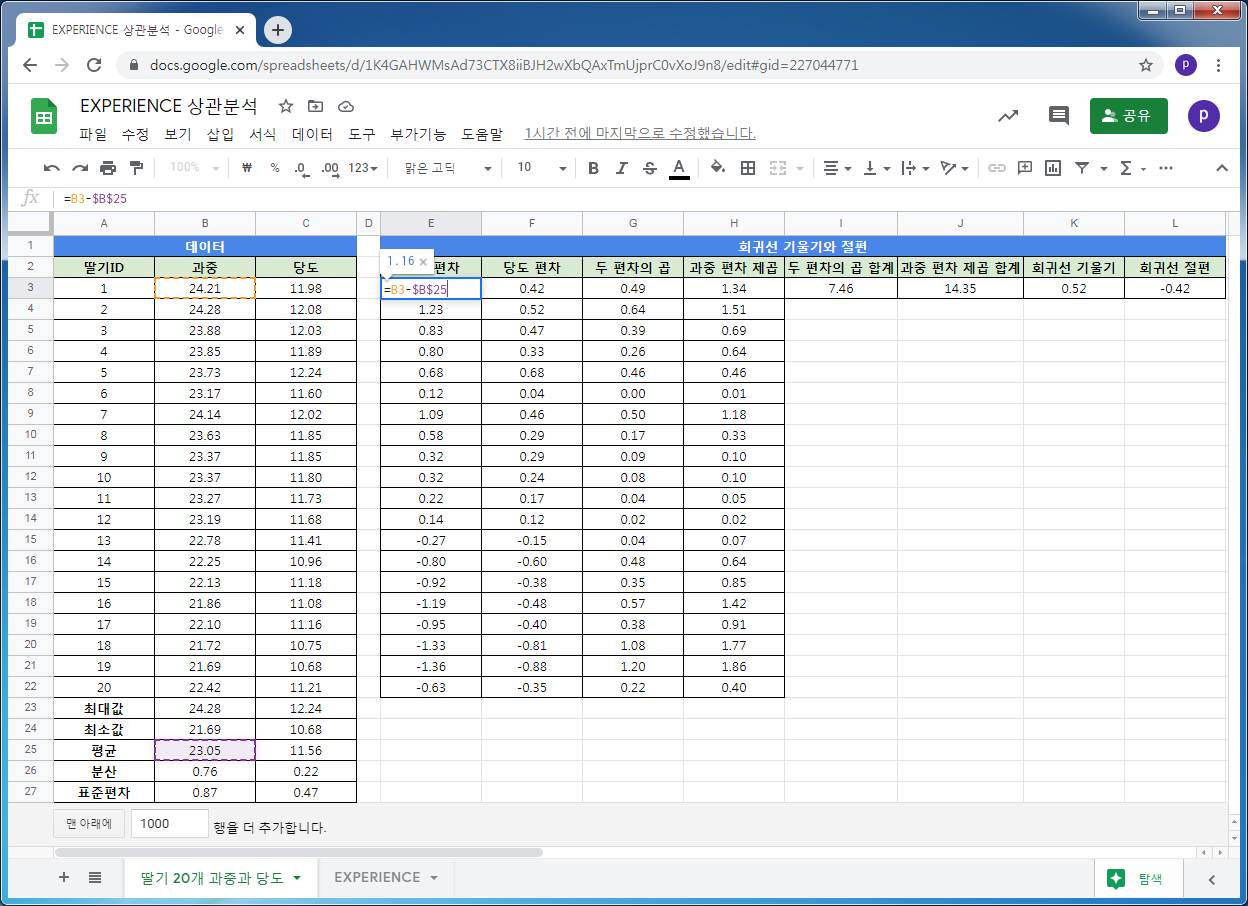
과중과 당도의 편차의 곱 합계와 과중 편차제곱 합계의 비율이 회귀선의 기울기가 됩니다.
과중을 X축으로 하고, 당도를 Y축으로 하는 산점도 상에 회귀선을 그리게 되면, 그 기울기는 과중이 변화할 때 당도가 얼마나 변화하는지를 나타냅니다. 이는 과중과 당도의 편차의 곱 합계를 과중 편차제곱 합계로 나눈 값이 됩니다.

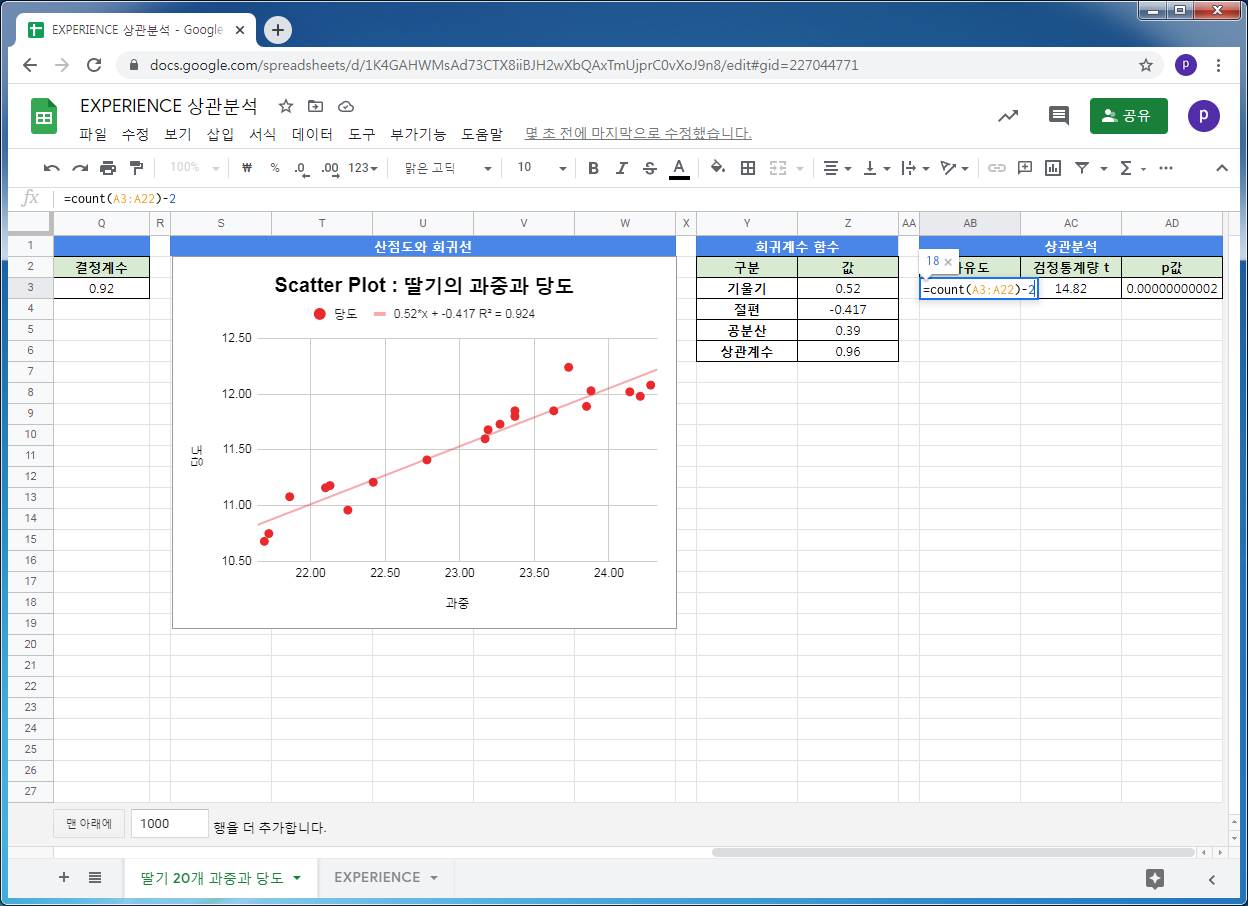
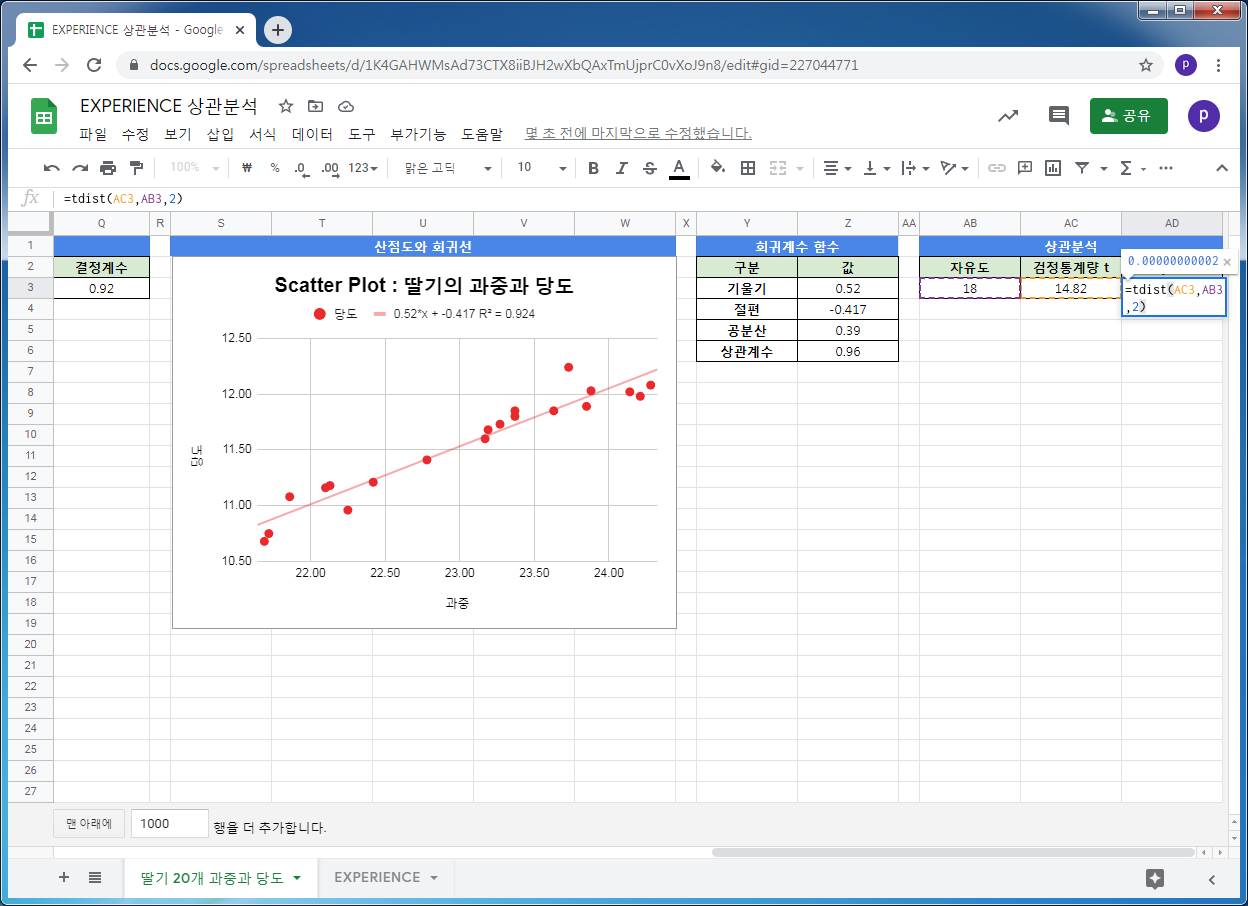
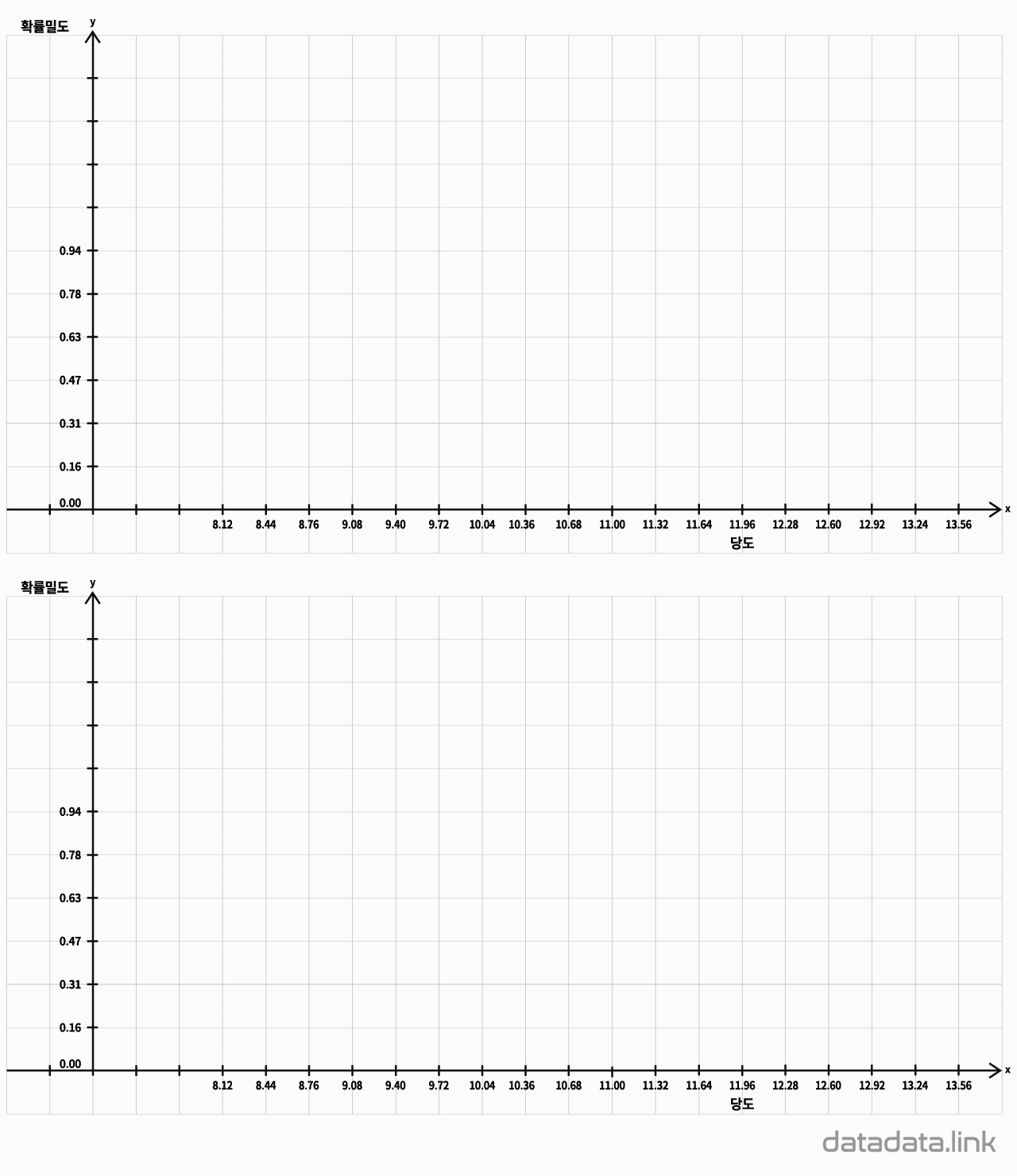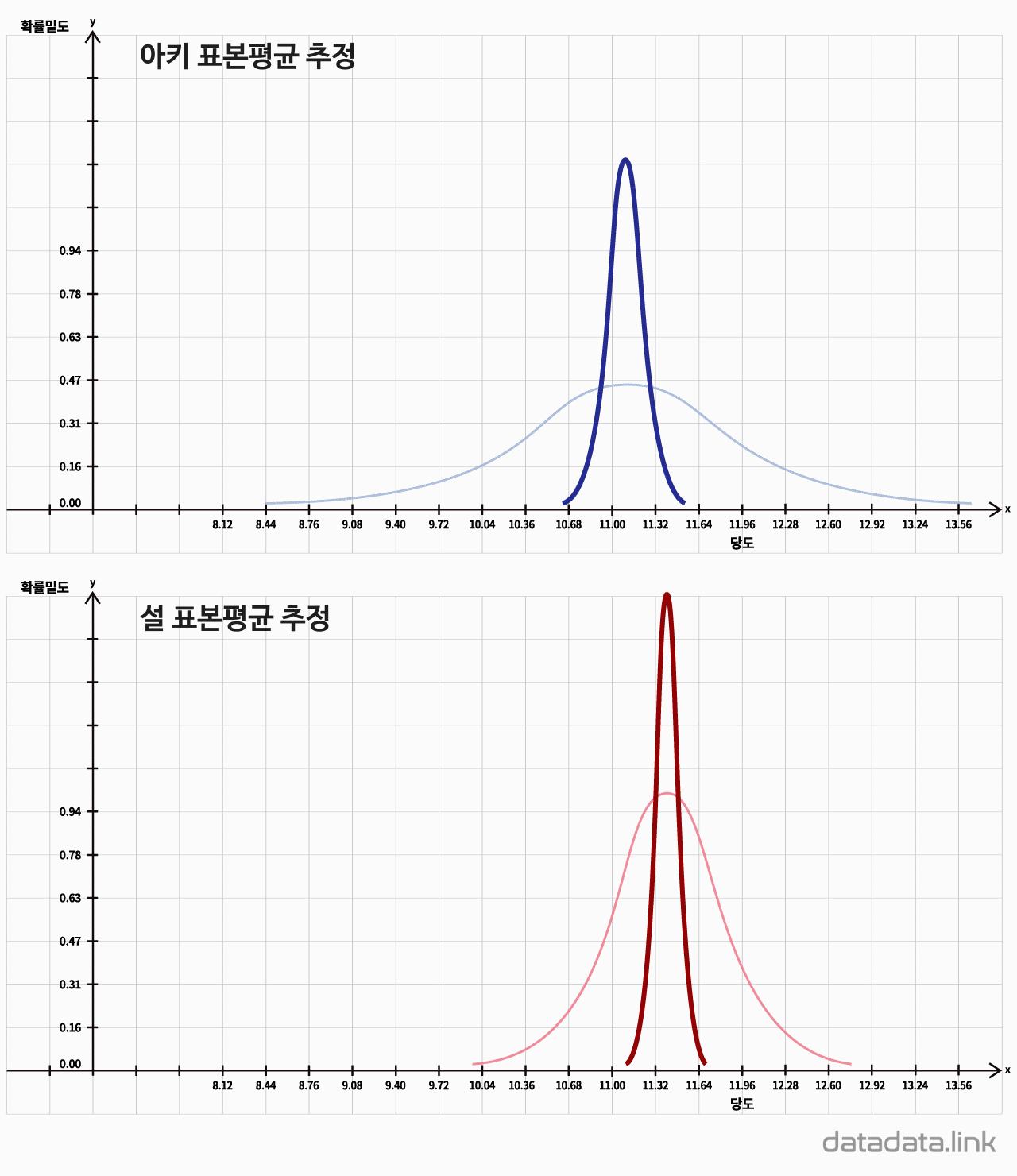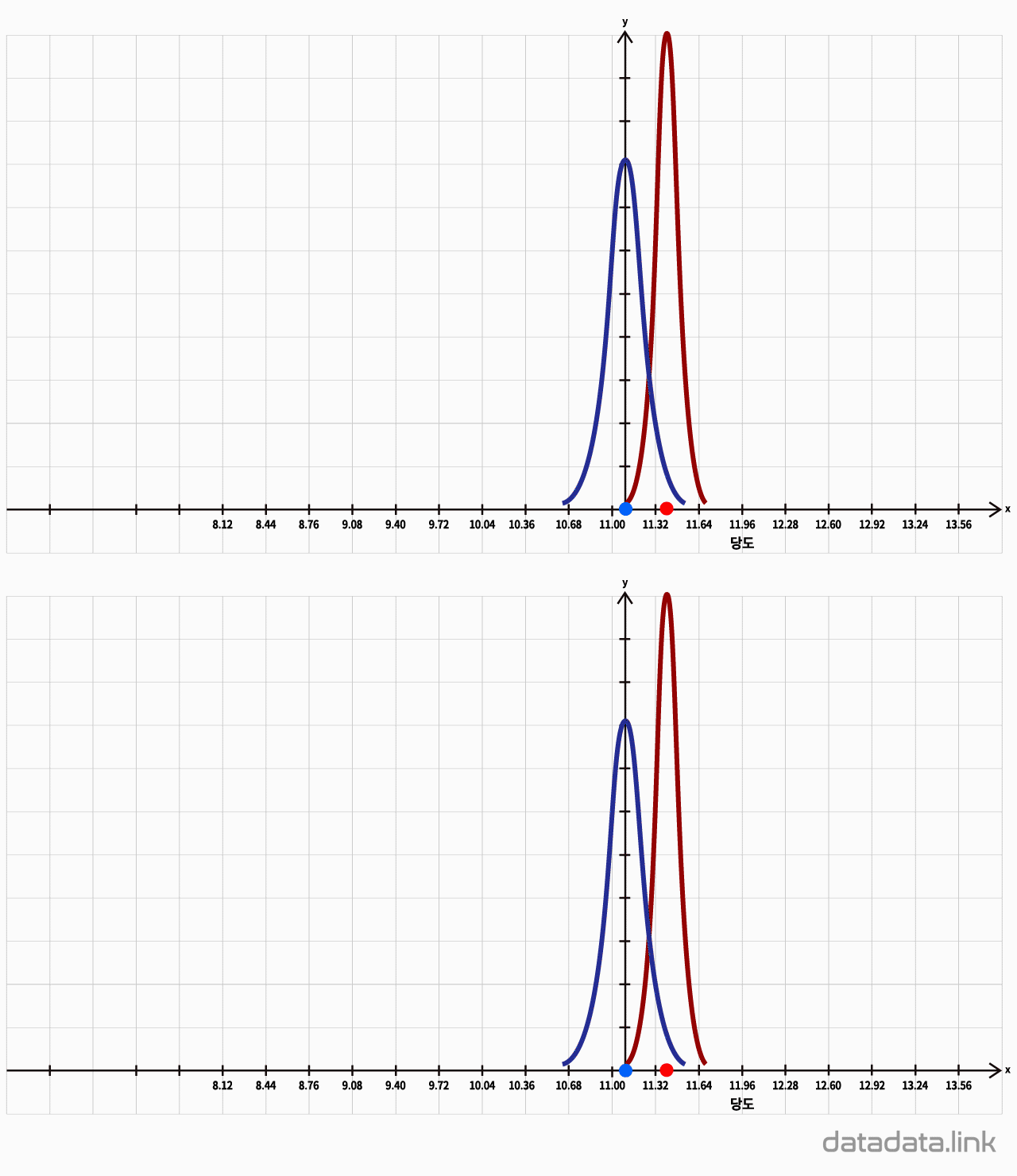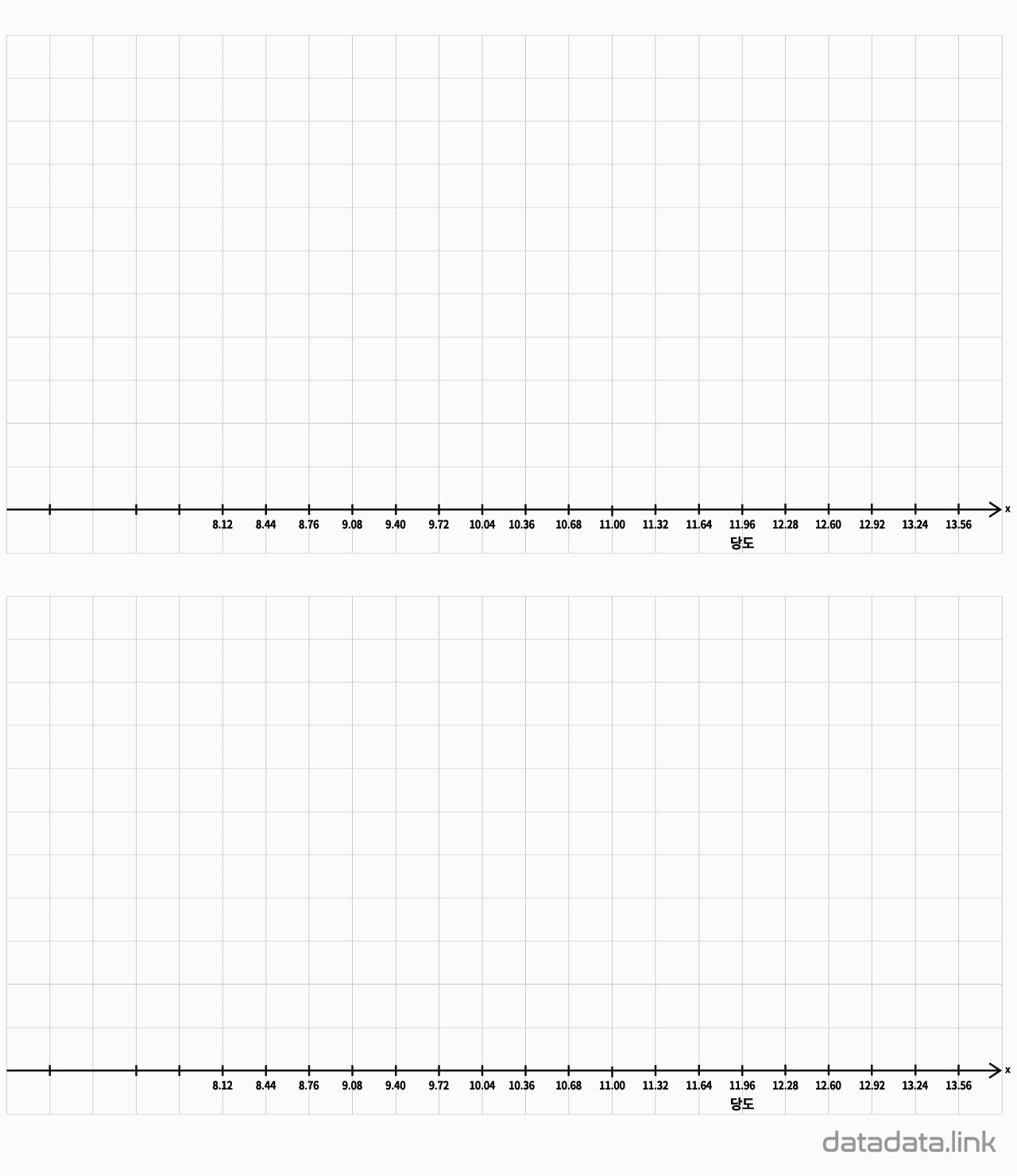
과중과 당도의 상관계수가 유의한지는 표본의 크기, 상관계수에 의해 좌우됩니다.
딸기 20알의 과중과 당도의 상관계수가 유의미한지를 검정하기 위해, 검정통계량 t를 구합니다. t분포 상에서 검정통계량의 확률밀도를 구하고, 그것이 유의수준보다 작으면, 과중과 당도의 상관관계가 유의하다고 할 수 있습니다.