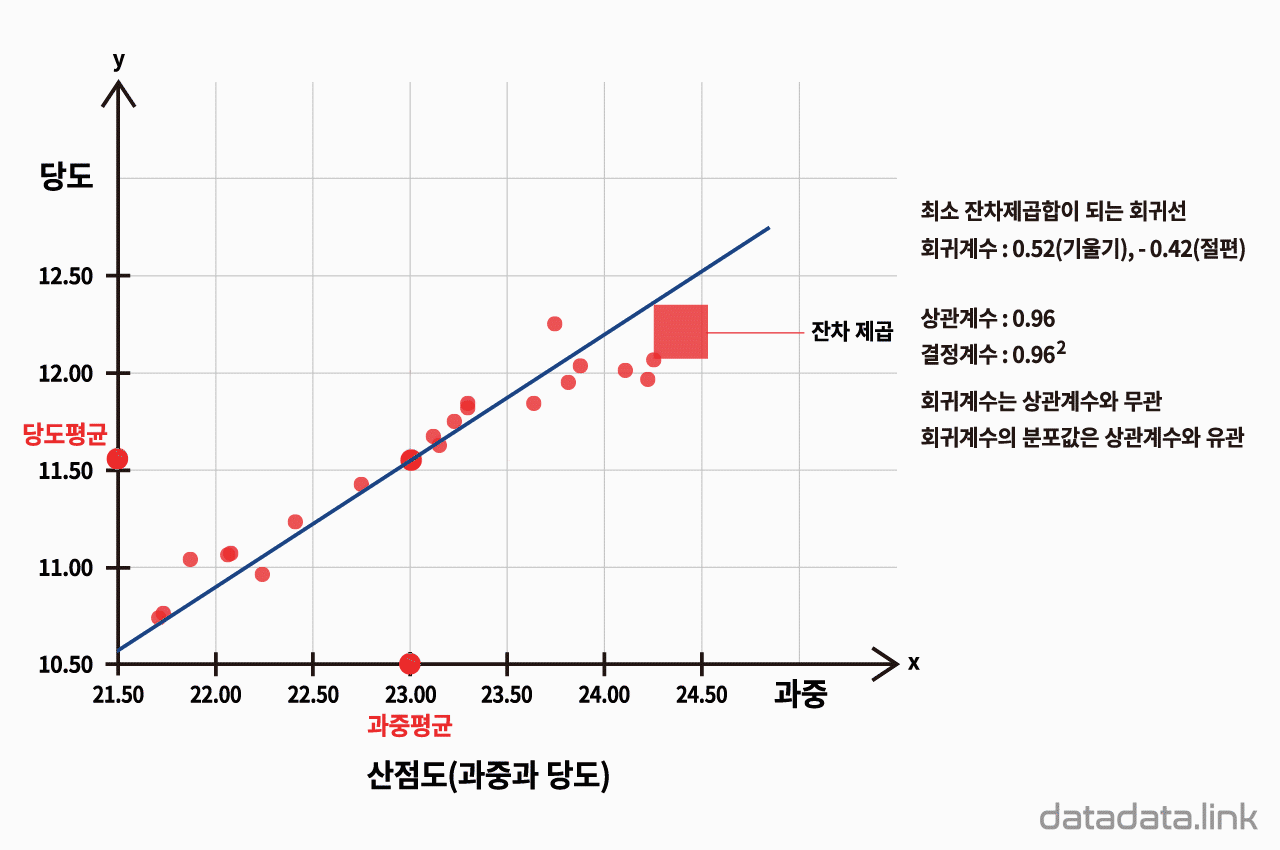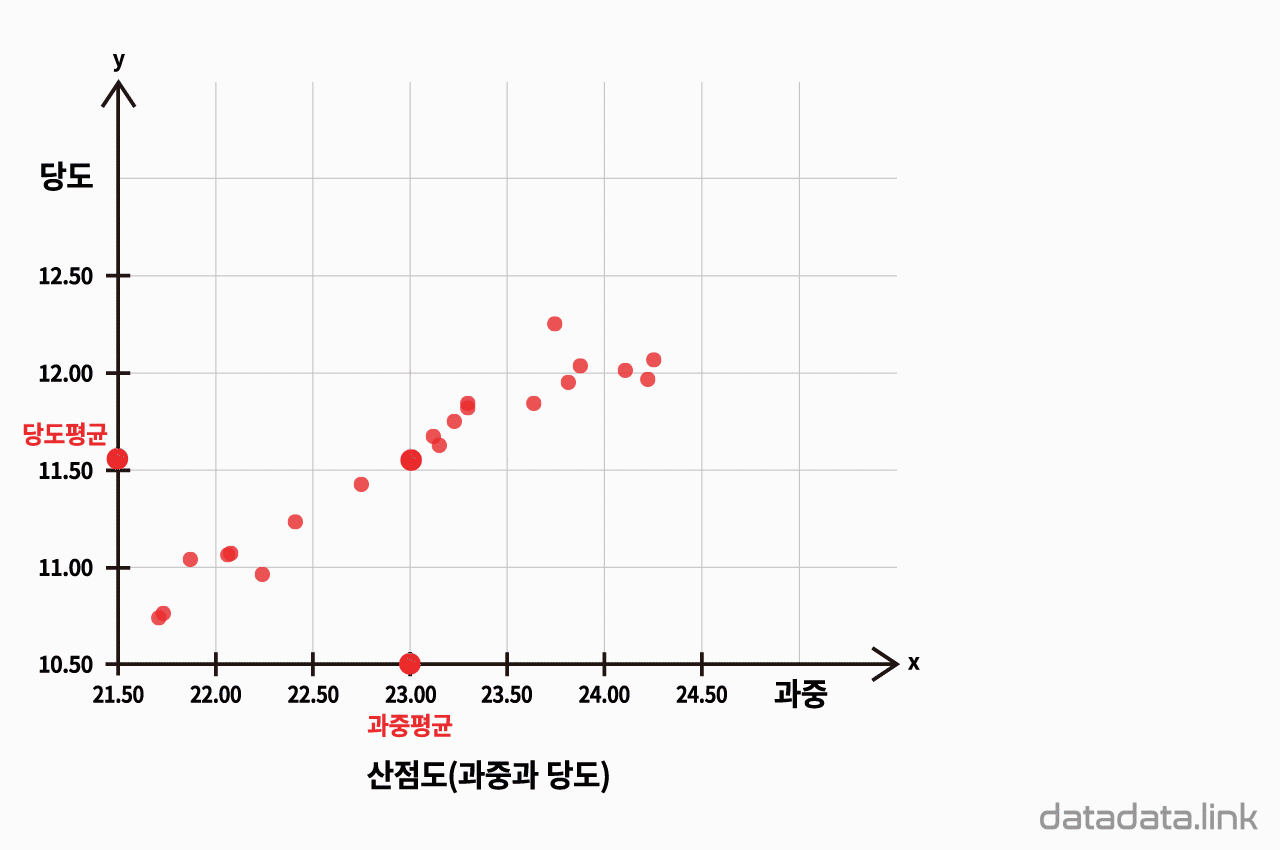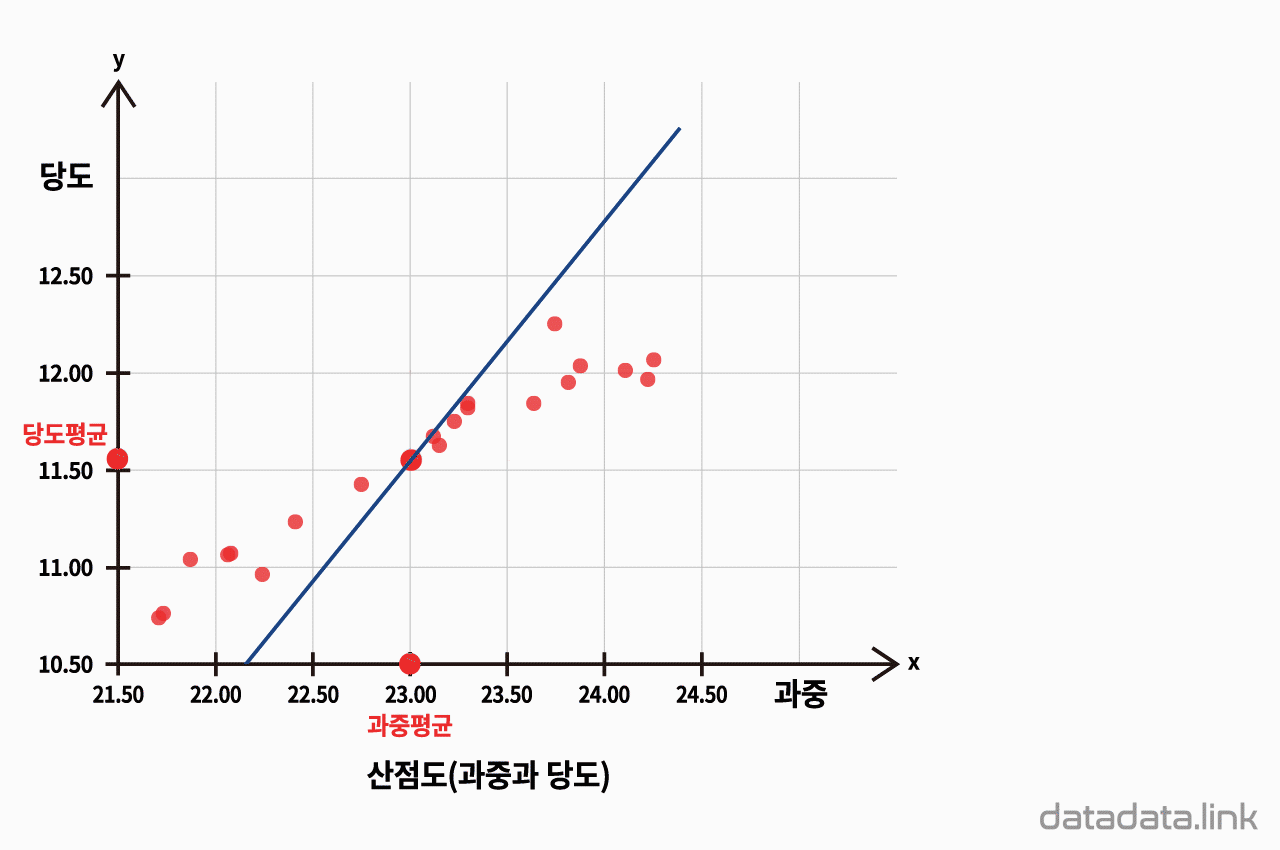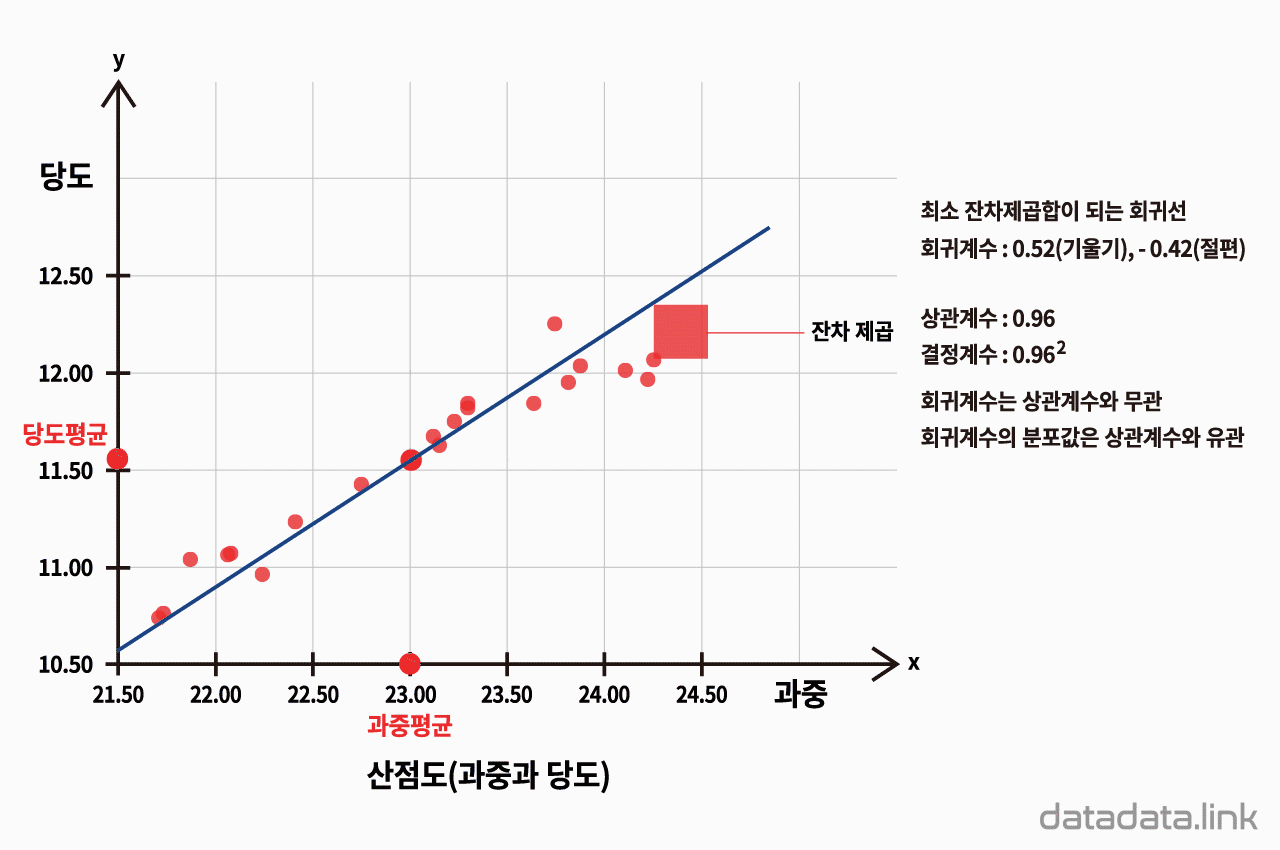
A/B 테스트
1. 애니메이션
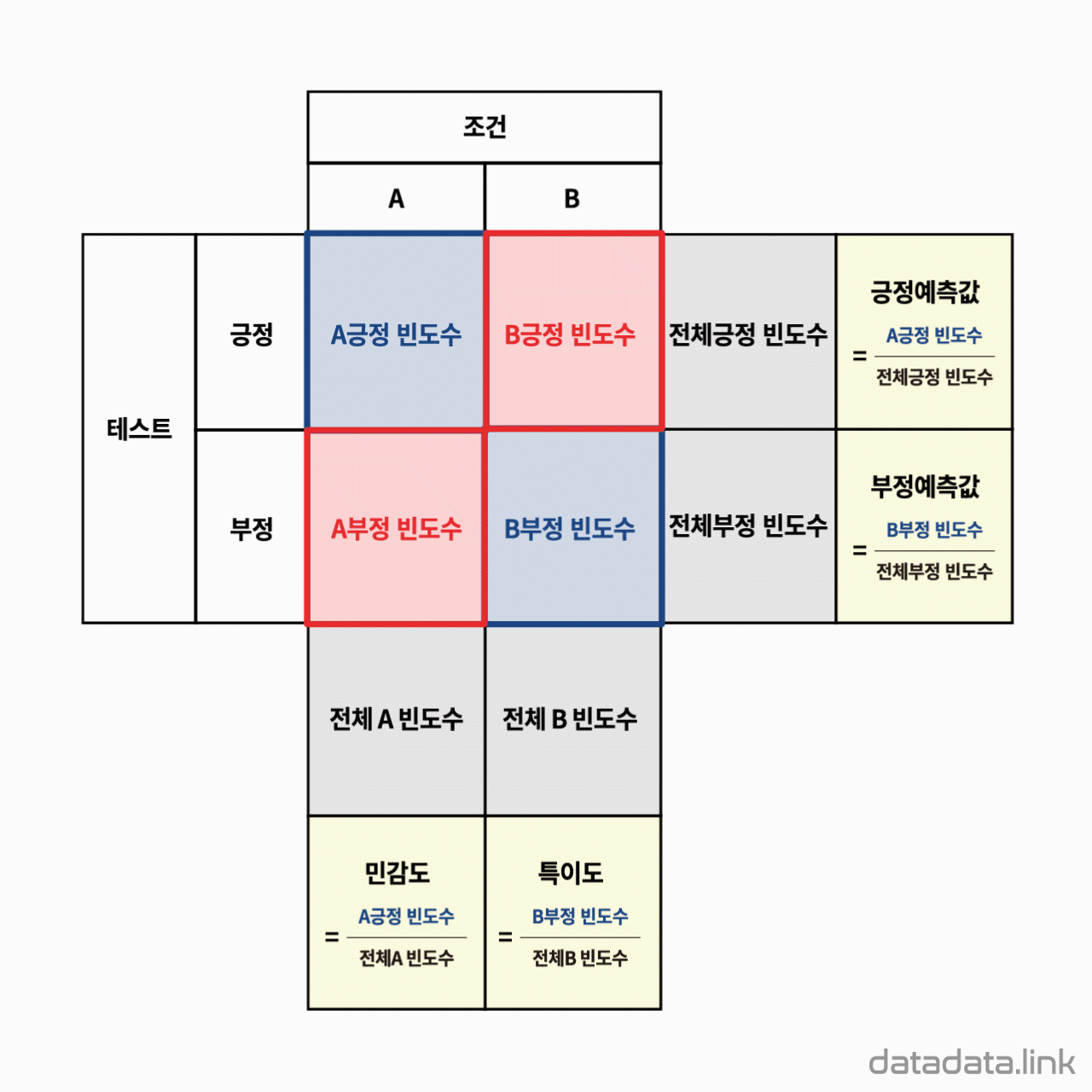

2. 설명
2.1 A/B 테스트
AB테스트는 두 개의 조건, A와 B에 따른 테스트의 결과를 대조하는 실험입니다. 테스트 결과를 긍정과 부정으로 하면 두 조건 중 하나를 선택할 때 사용할 수 있습니다.
웹 페이지 디자인 A, B중에서 사용자가 더 선호하는지를 알고자 할 때 사용합니다. 선호하는 결과는 그 웹페이지를 선택한 사람 중 구매한 사람의 빈도수를 사용할 수 있습니다.
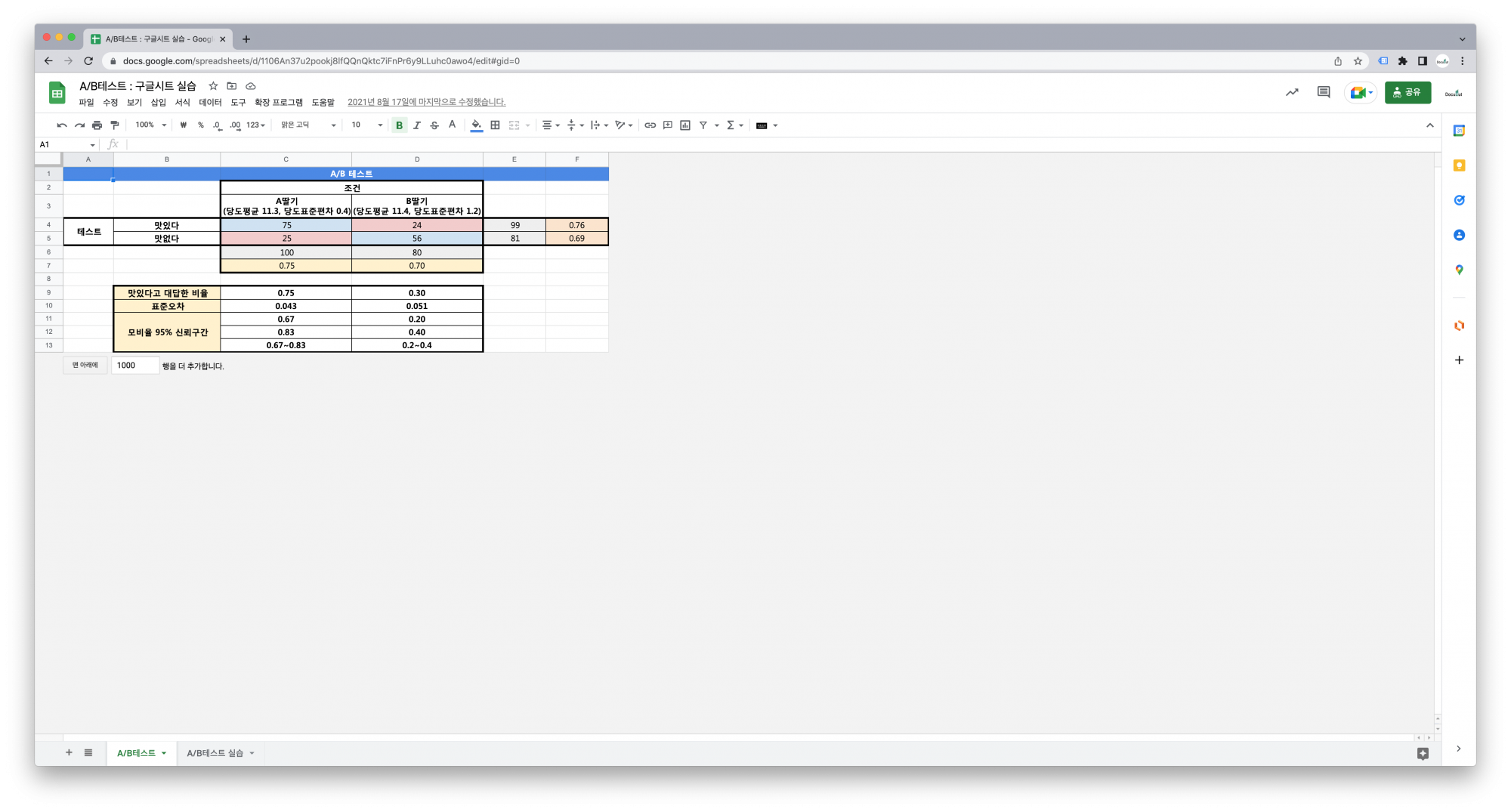
A딸기와 B딸기가 어느 것이 더 맛있다고 소비자가 생각하는 지를 보기 위하여 AB 테스트를 다음과 같이 시행하였습니다.
180명이 참가했는데 A딸기를 100명이 B딸기를 80명이 시식하였습니다. 테스트는 맛있는가 맛이 없는가 두가지에서 선택하도록 하였습니다. A딸기를 먹은 사람 중 75명과 B딸기를 먹은 사람 중 24명이 맛있다는 평가를 했습니다. 그럼, A딸기가 더 맛있다고 할 수 있을까요?
우선 A딸기를 선택하거나 B딸기를 선택할 때 무작위(random)여야 합니다.
그리고 결과가 A딸기는 모두가 긍정으로 반응을 하고 B딸기는 모두가 부정으로 반응을 하면 A딸기는 맛있고 B딸기는 맛이 없다고 분명하게 결정할 수 있습니다.
이번 테스트의 결과는 A딸기에서 맛있다는 비율은 75/100이고 B딸기는 24/80입니다.
3. 실습
3.3. 실습강의
데이터
교차표 작성
결과 분석
4. 용어와 수식
4.1 용어