1차원 도수분포도
1D Frequency distribution graph
1. 애니메이션
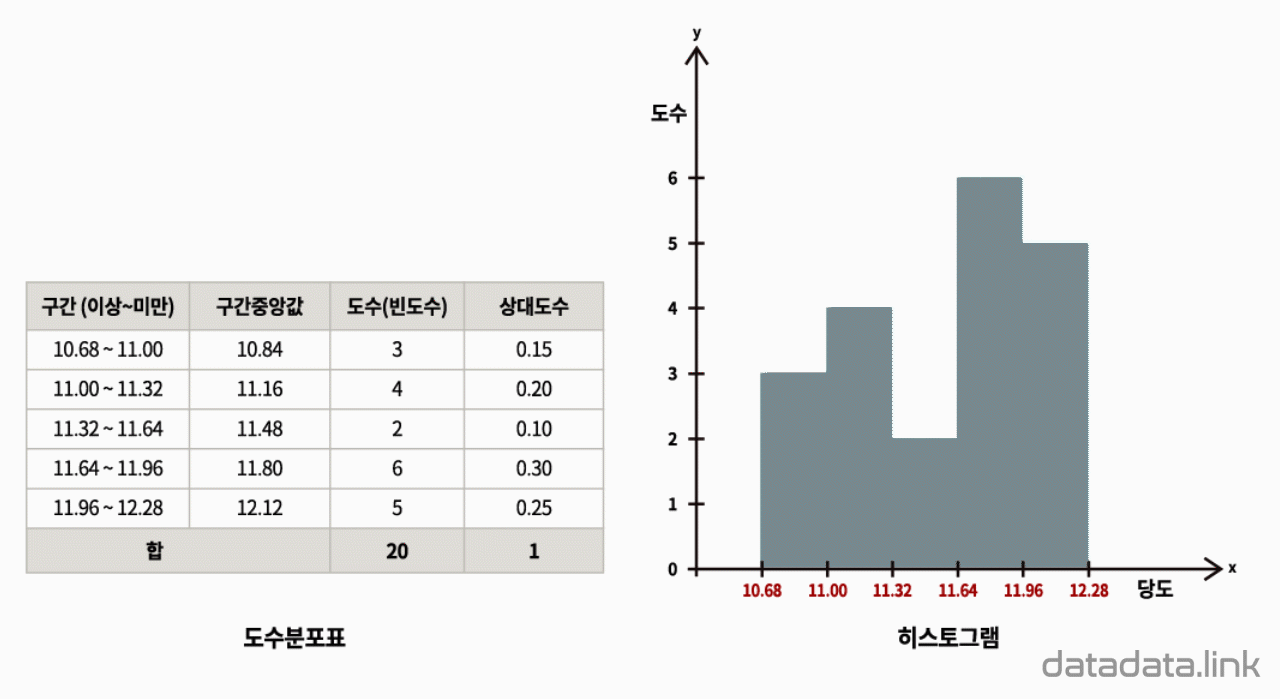
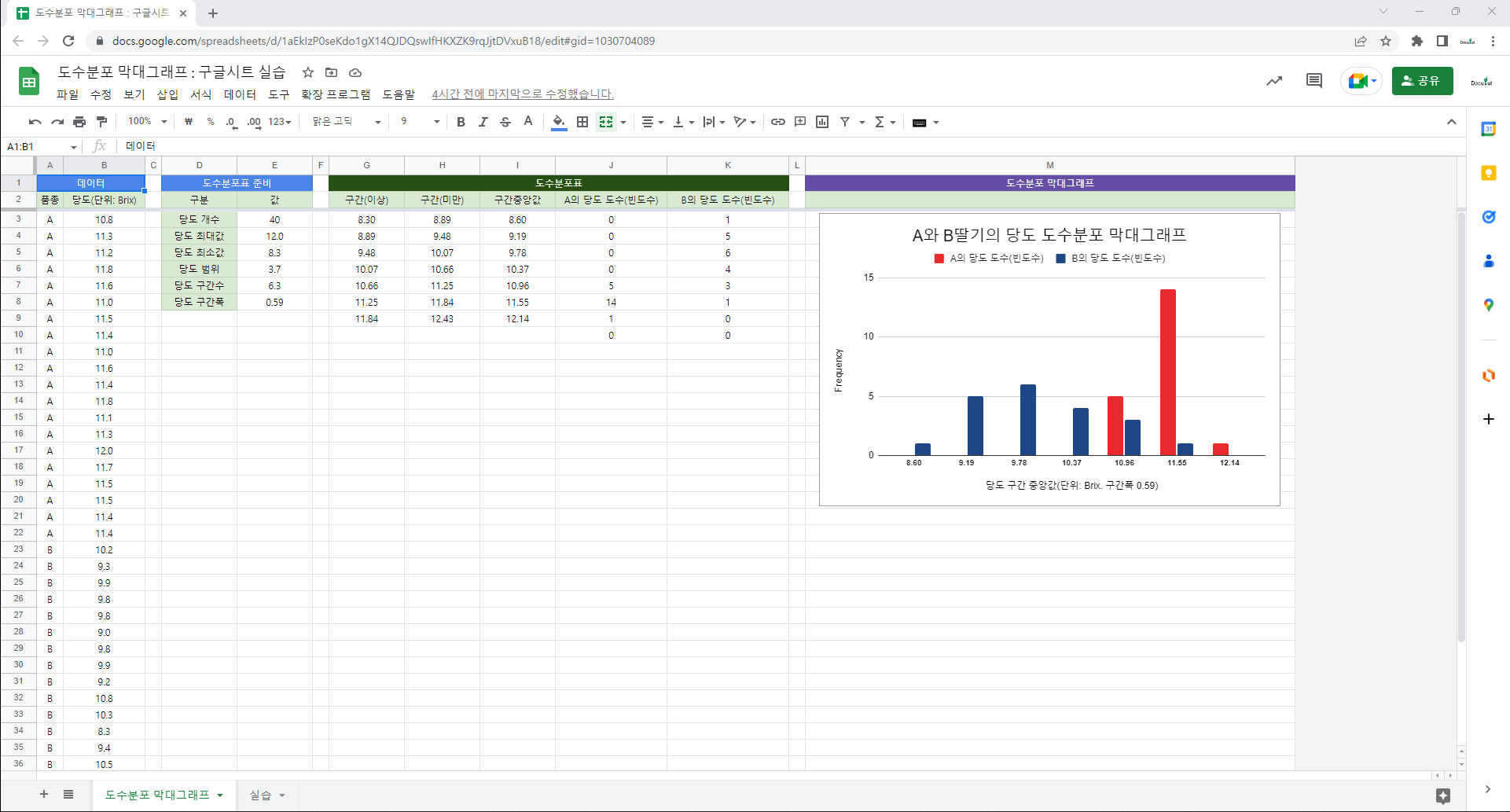
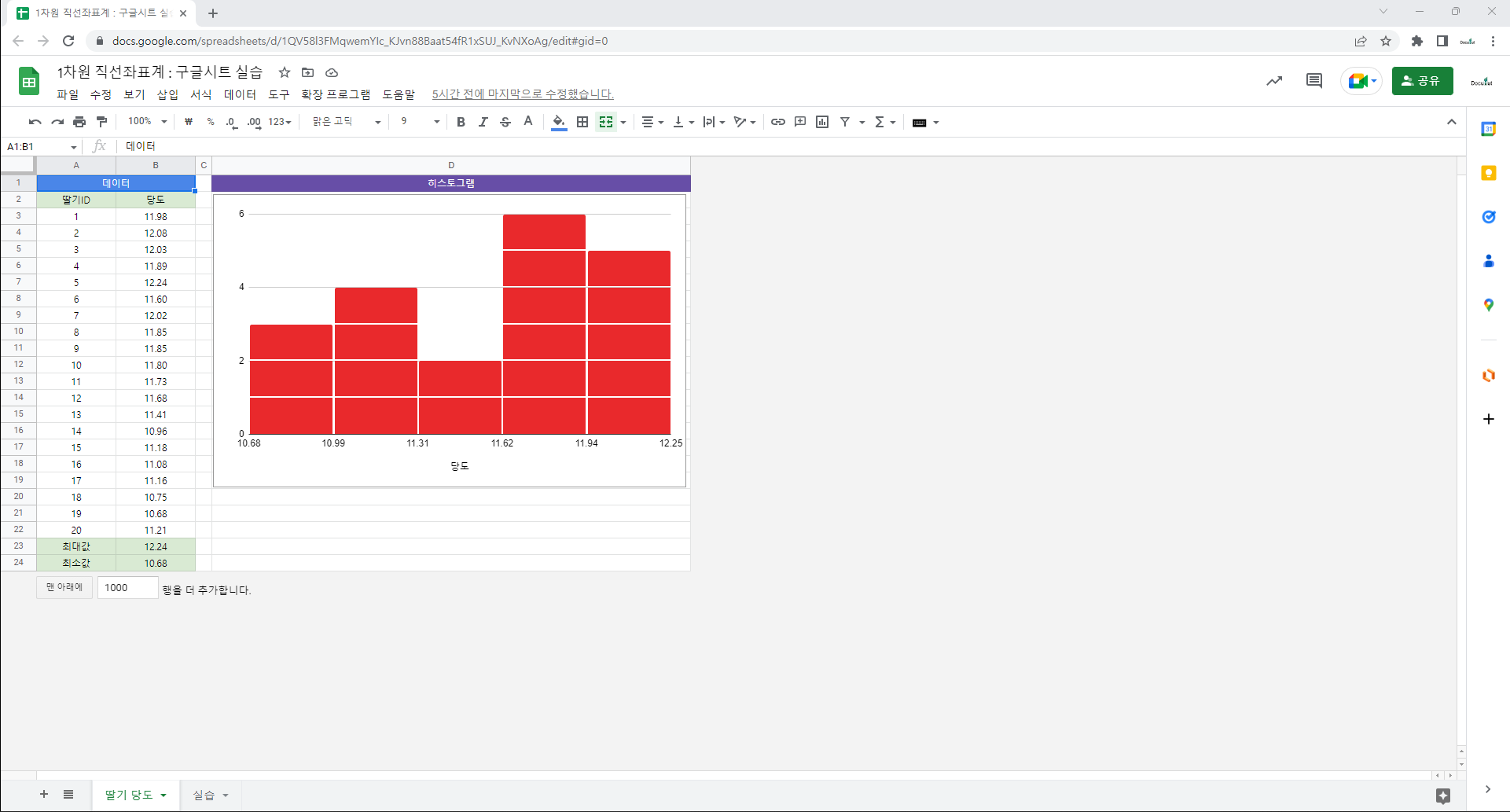
도수분포표로 히스토그램 그리기
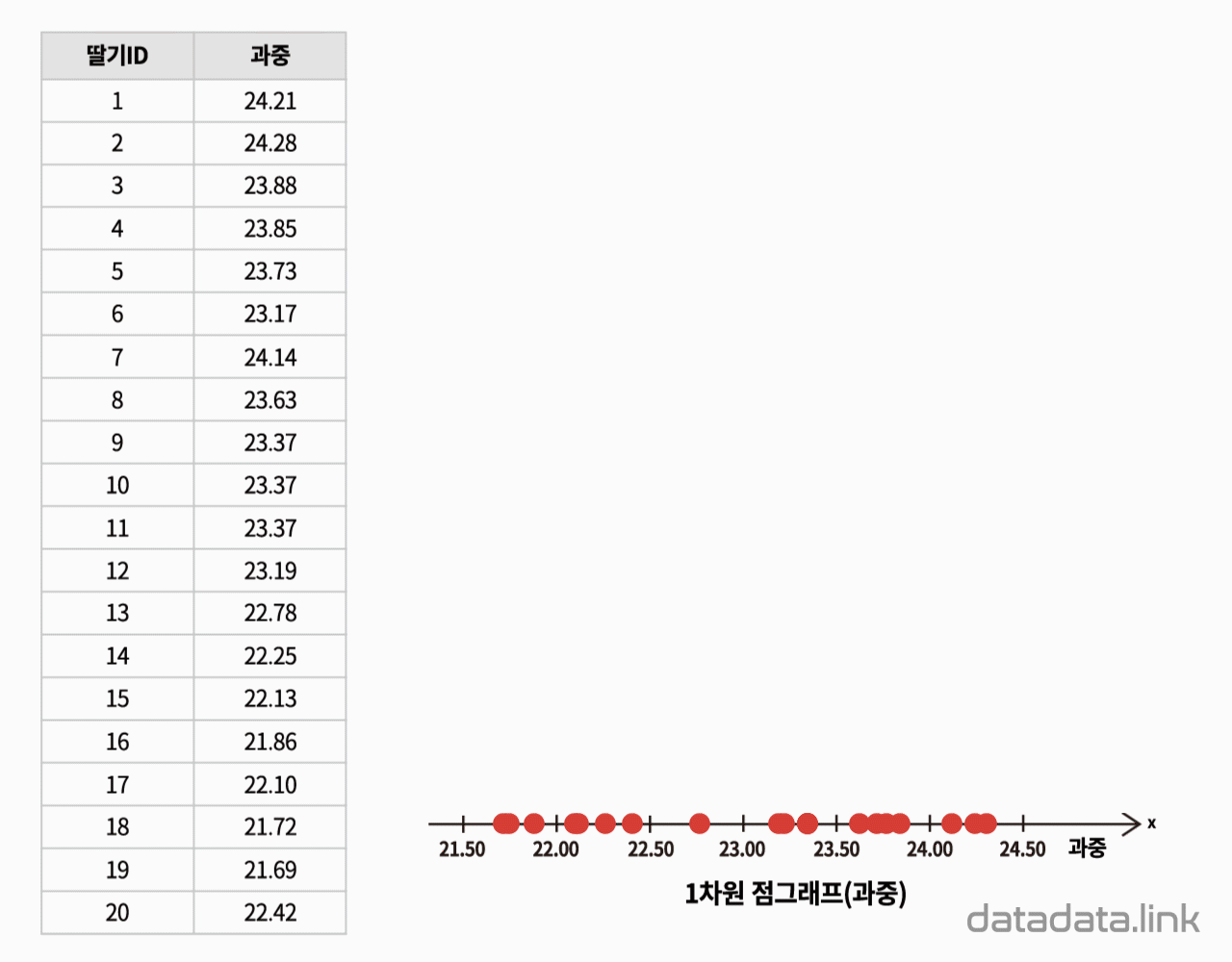
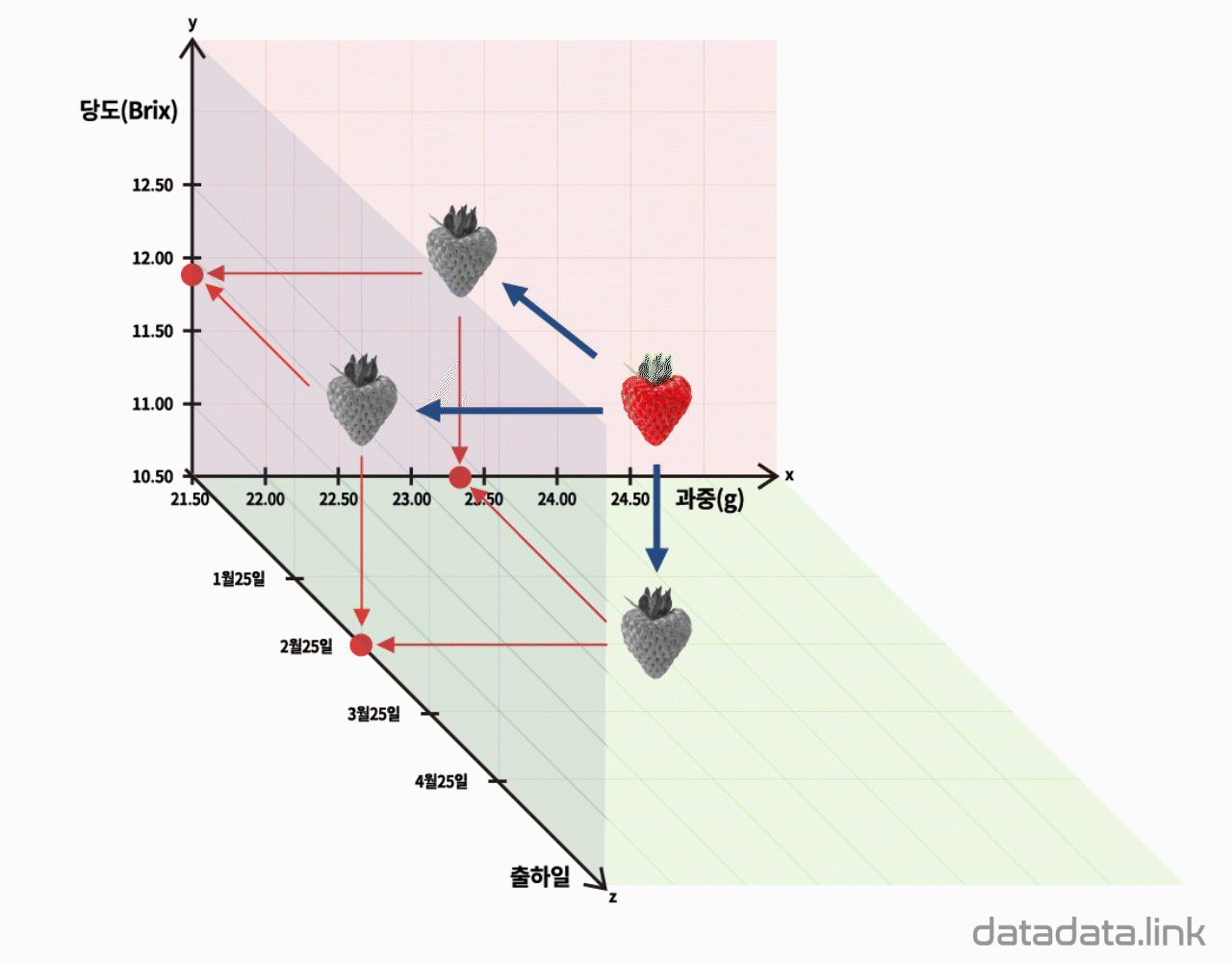
1차원 산점도
2. 설명
2.1.히스토그램(histogram)
히스토그램
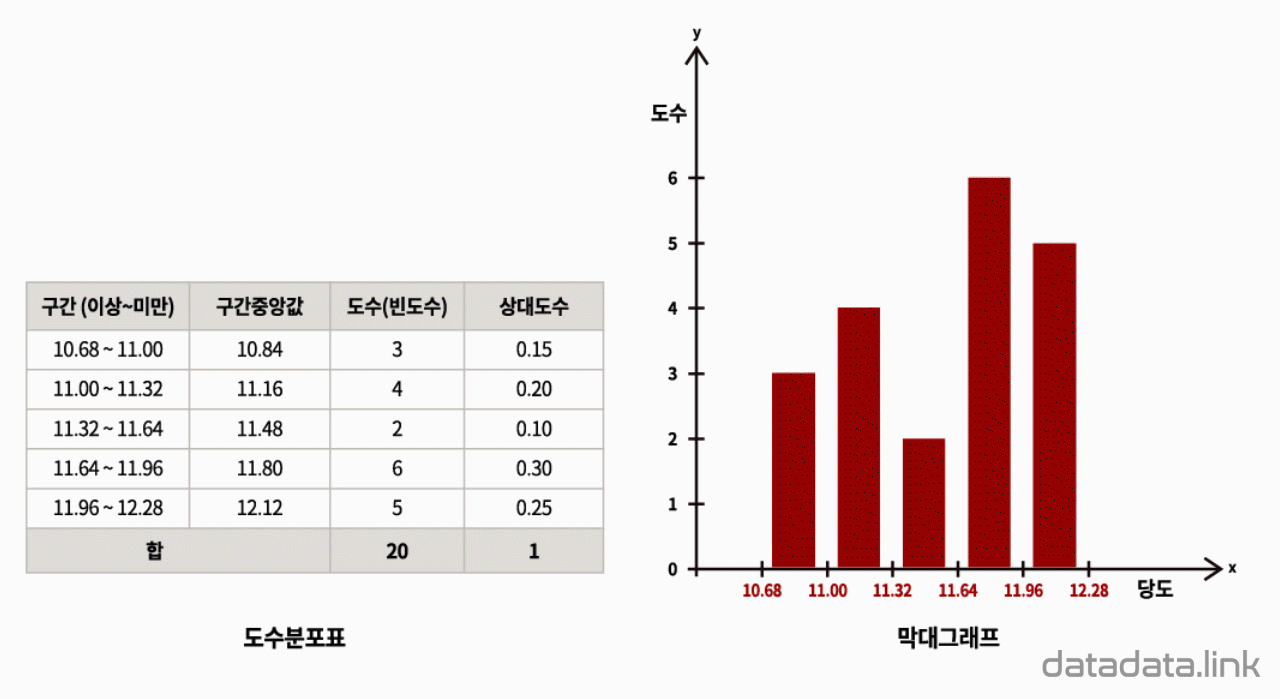
히스토그램은 구간(범주)에 속한 개체의 도수(빈도수)를 직사각형의 높이로 표현한 것입니다. 이 때 직사각형의 밑변의 길이는 등간격을 가지는 구간이 됩니다. 그리고 히스토그램을 이루는 각 구간의 직사각형은 서로 붙여서 그립니다. 따라서 히스토그램은 구간에 따른 개체의 도수분포를 나타낸다고 볼 수 있습니다.
한편, 순서가 없는 범주로 구분된 개체의 도수는 막대그래프로 표현합니다. 막대그래프에서는 범주의 위치를 표현할 수 없지만 히스토그램에서는 범주의 위치를 구간의 길이와 순서로 나타낼 수 있습니다. 히스토그램에서는 구간이 만드는 직사각형을 붙여서 그리므로 범주의 위치가 있음을 시각화합니다. 정리하면, 범주에 속하는 개체의 도수는 막대그래프로 표현할 수 있습니다. 이 때, 범주의 위치를 실수로 표현하고자 하는 경우 히스토그램을 사용합니다.
히스토그램 작성
히스토그램을 그리기 위해서는 데이터(변수값)의 범위(range)가 정해져야 합니다. 데이터의 범위는 데이터의 최대값과 최소값의 차로 구합니다. 그리고 동일한 간격을 가지는 구간(계급, bin, bucket)을 정합니다. 각 구간에 속하는 개체(object)의 개수를 그 구간의 도수(빈도수, frequency)라고 합니다. 도수는 자연수이며 각 구간을 밑변으로 하는 직사각형의 높이로 표현됩니다. 각 구간의 간격이 같기 때문에 히스토그램의 면적은 각 구간의 도수와 비례합니다. 즉, 히스토그램을 이루는 각 직사각형의 면적과 그 직사각형이 의미하는 범주에 속하는 개체의 도수는 선형관계입니다.
‘범위를 몇 개의 등간격인 구간으로 나눌 것인가?’는 히스토그램을 그리기 위한 중요한 결정사항입니다. 구간의 개수를 정하는 방법은 데이터 개수의 제곱근에 근사한 정수로 하는 방법 등 여러가지가 제시되고 있습니다. 구간의 개수가 정해지면 연속형 변수의 범위(최대값-최소값)를 구간의 개수로 나누어 구간을 구합니다. 각 구간의 시작점과 끝점은 보통 ‘~ 이상($≥$)에서 ~ 미만($<$)’으로 정합니다.
2.2. 히스토그램의 활용
히스토그램은 관심있는 확률변수가 나타내는 확률분포를 유추하는 방법으로 활용됩니다. 히스토그램은 확률변수가 실현된 개체의 분포를 시각화하여 확률분포를 유추합니다. 히스토그램은 관심있는 확률변수의 확률분포를 닮은 모양을 보여줌으로 확률변수에 적합한 확률분포함수를 찾기 위한 탐색에 사용됩니다. 확률변수를 수식으로 모델링할 때 확률변수를 관측한 데이터로 히스토그램을 작성하여 모양을 살펴봅니다. 히스토그램의 도수를 상대도수로 변환하고 간격을 범위와 간격의 비로 변환하면 불연속적인 확률밀도함수를 그려볼 수 있습니다. 변환한 히스토그램의 직각사각형들의 면적의 합은 1이 됩니다.
히스토그램의 중요한 점은 면적의 크기로 도수를 표현한다는 것입니다. 이는 면적으로 데이터의 빈도를 표현한다는 점에서 면적으로 확률을 표현하는 확률밀도함수와 같습니다. 관측한 범주(구간)에서의 개체의 도수(빈도수)는 확률로 모델링됩니다. 연속형 확률변수를 모델링하는 확률밀도함수를 정하기 위해 관측 데이터를 탐색하는 매우 유용한 데이터시각화 방법입니다.
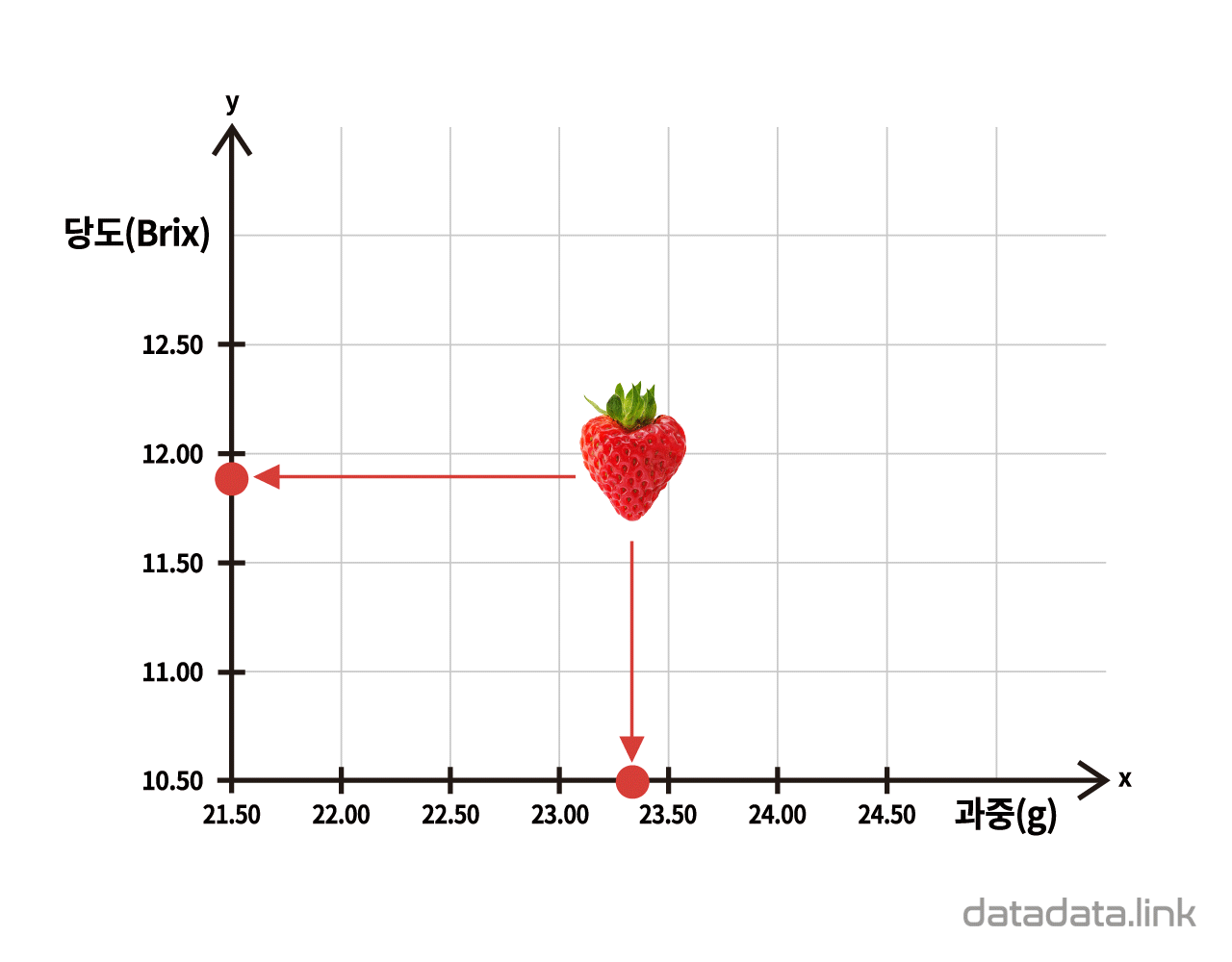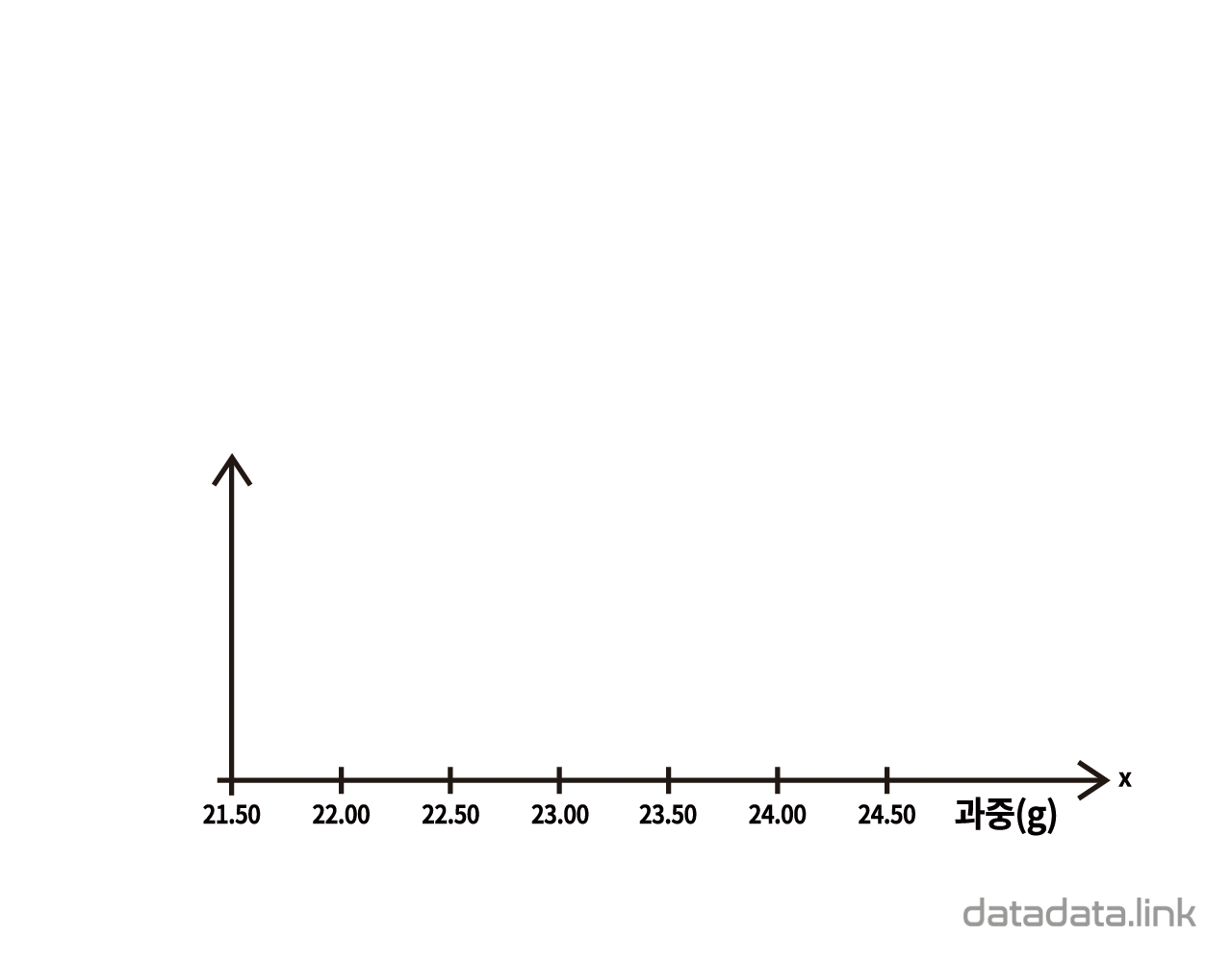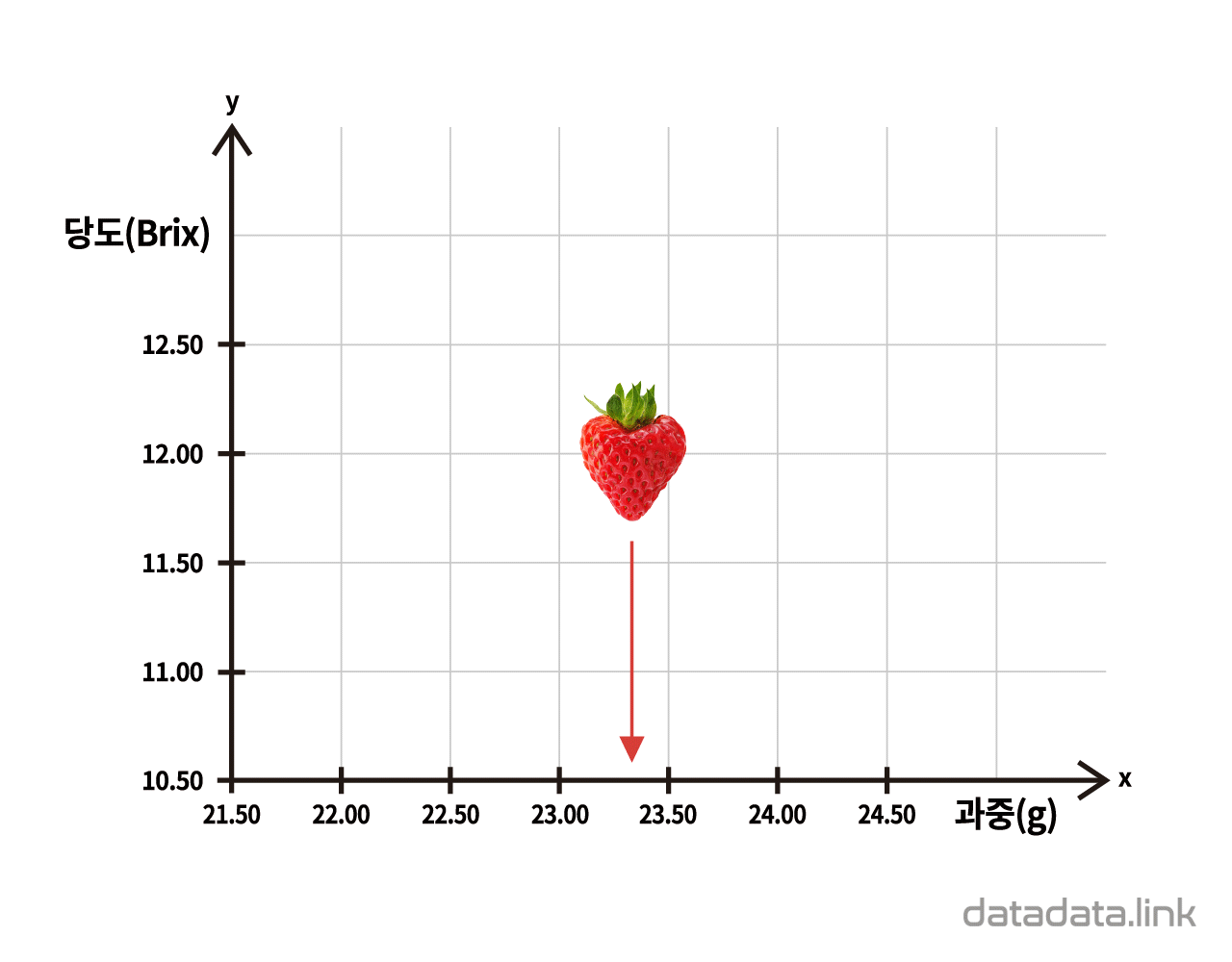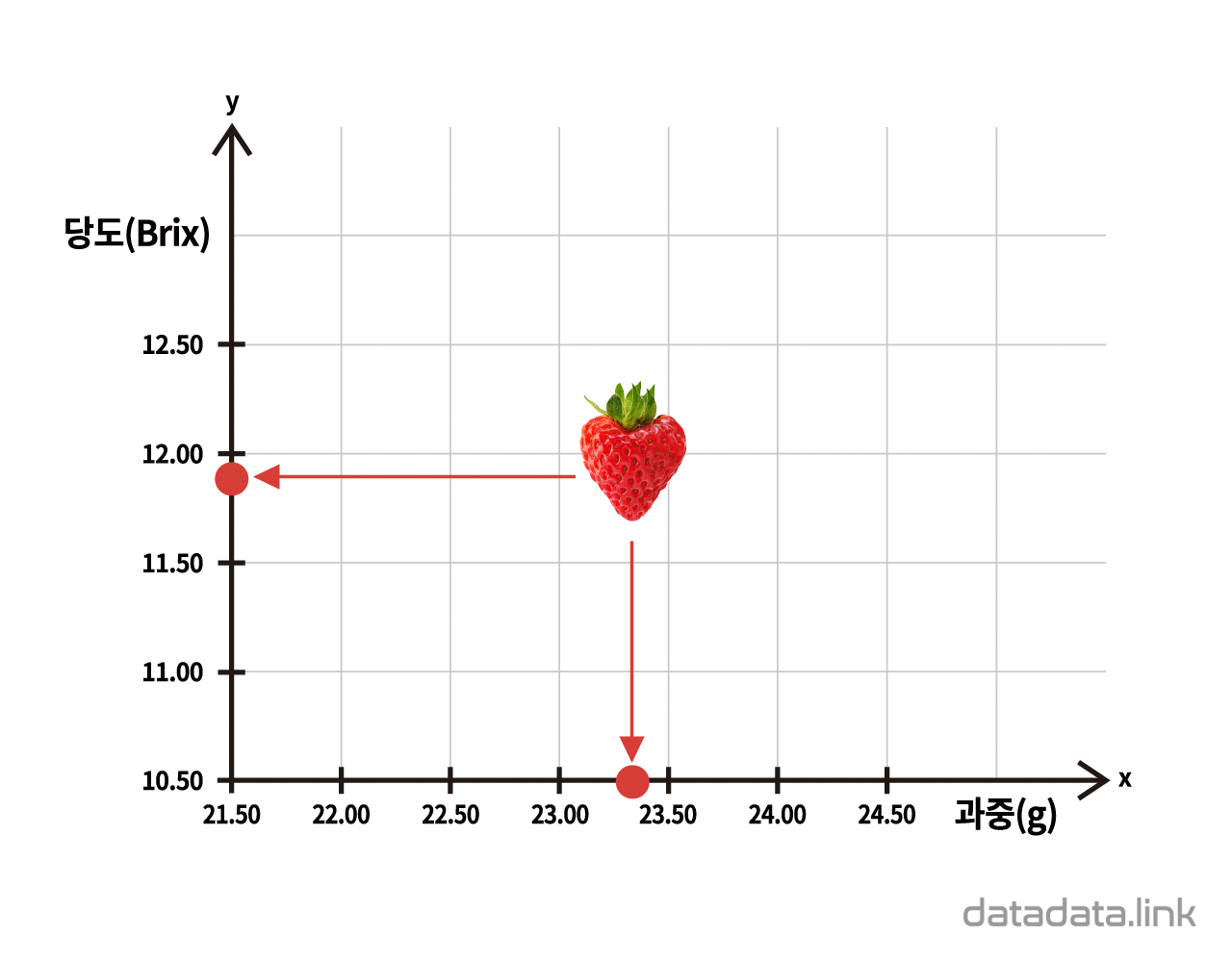
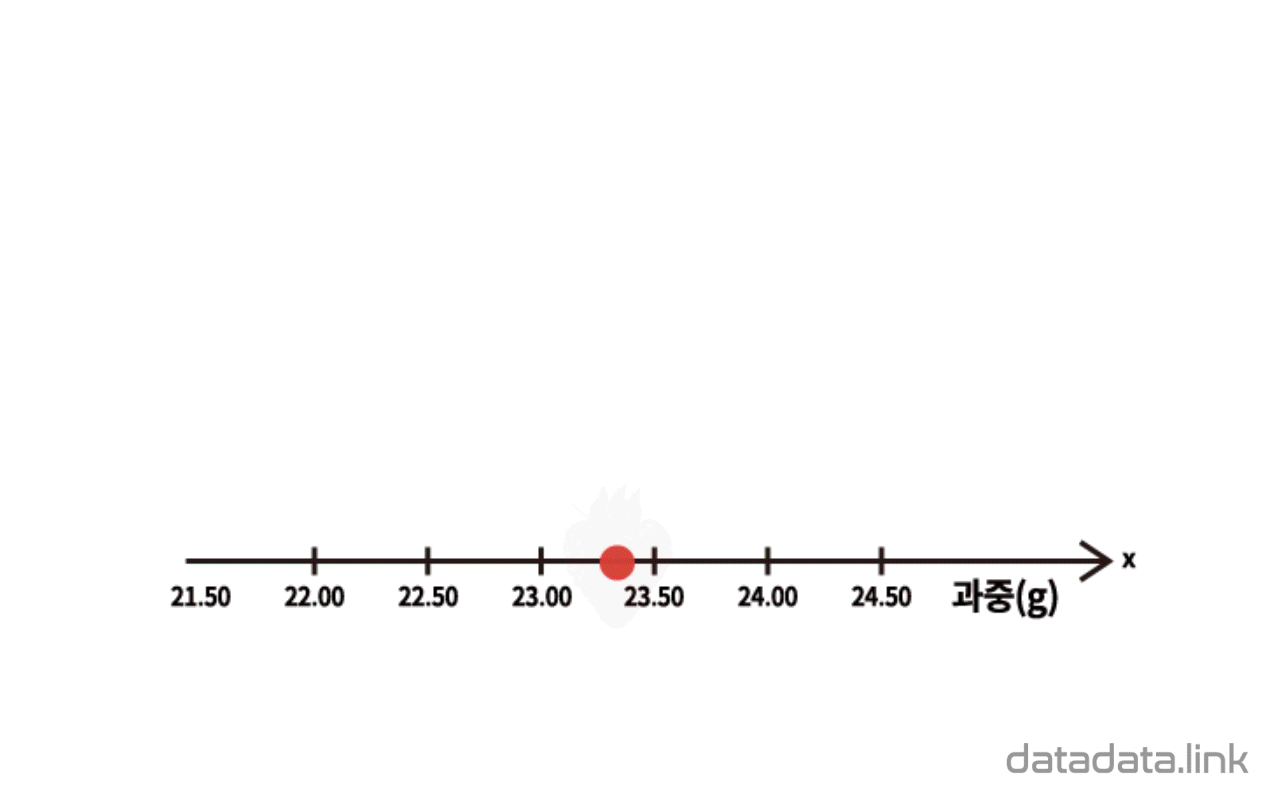
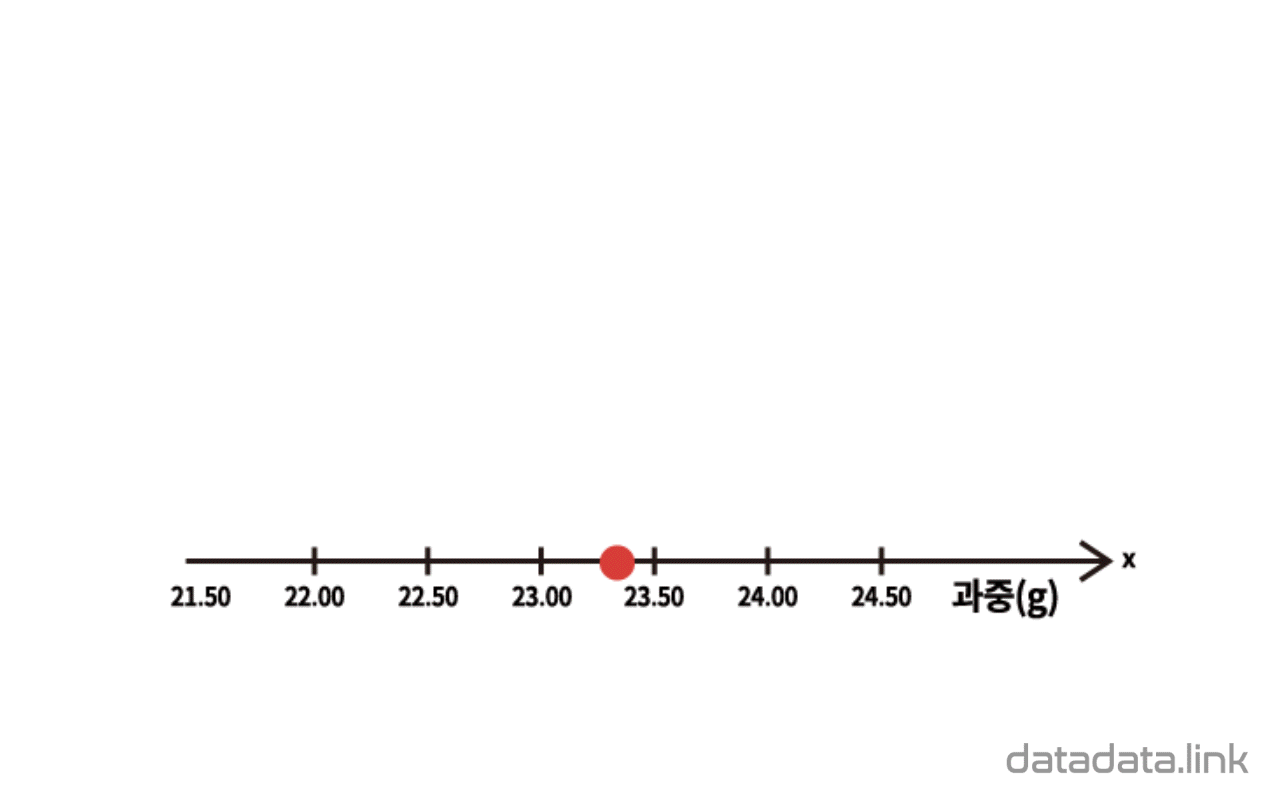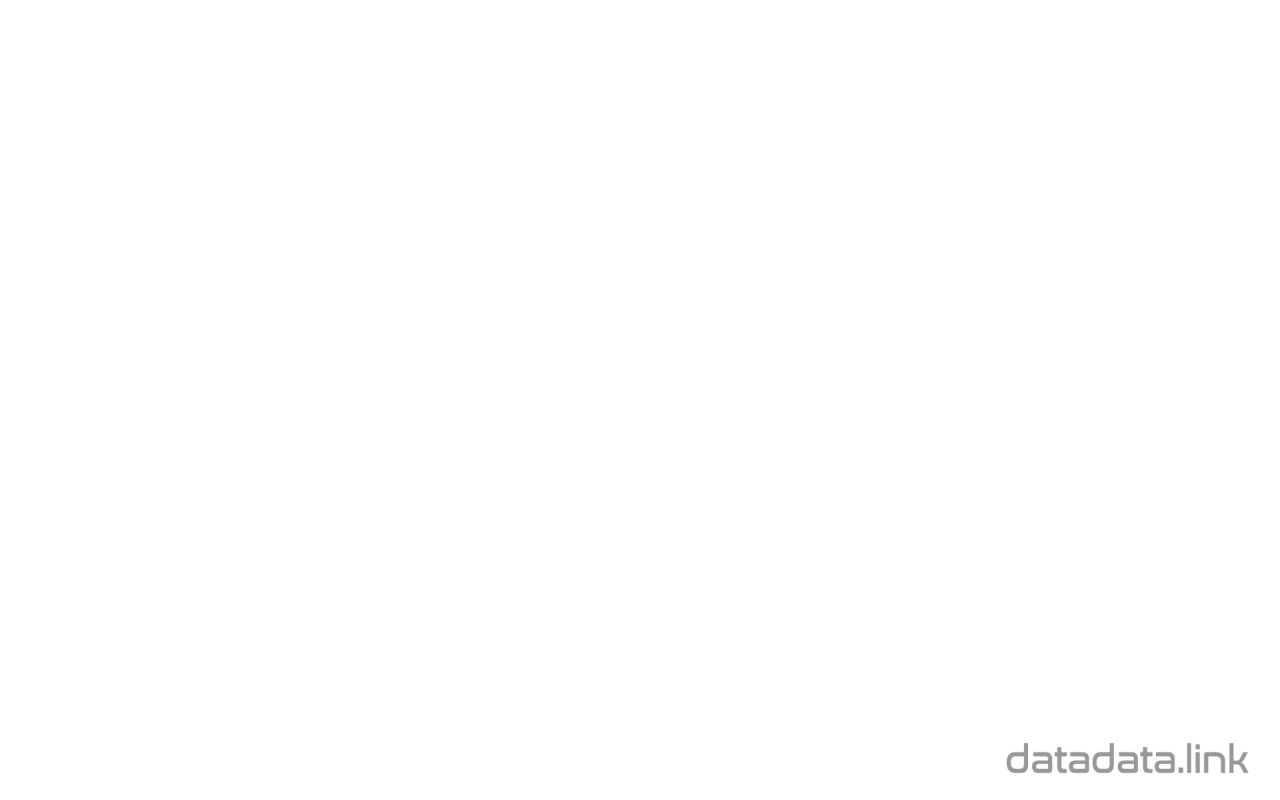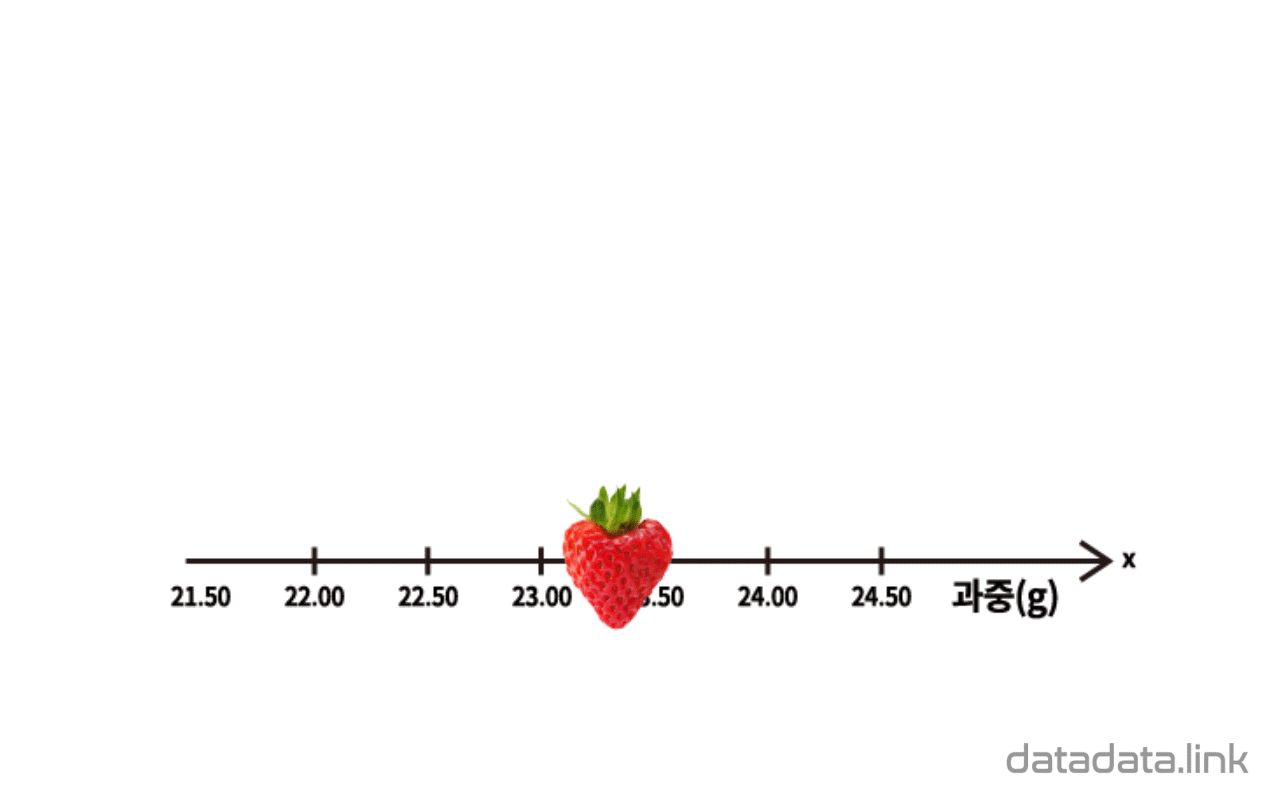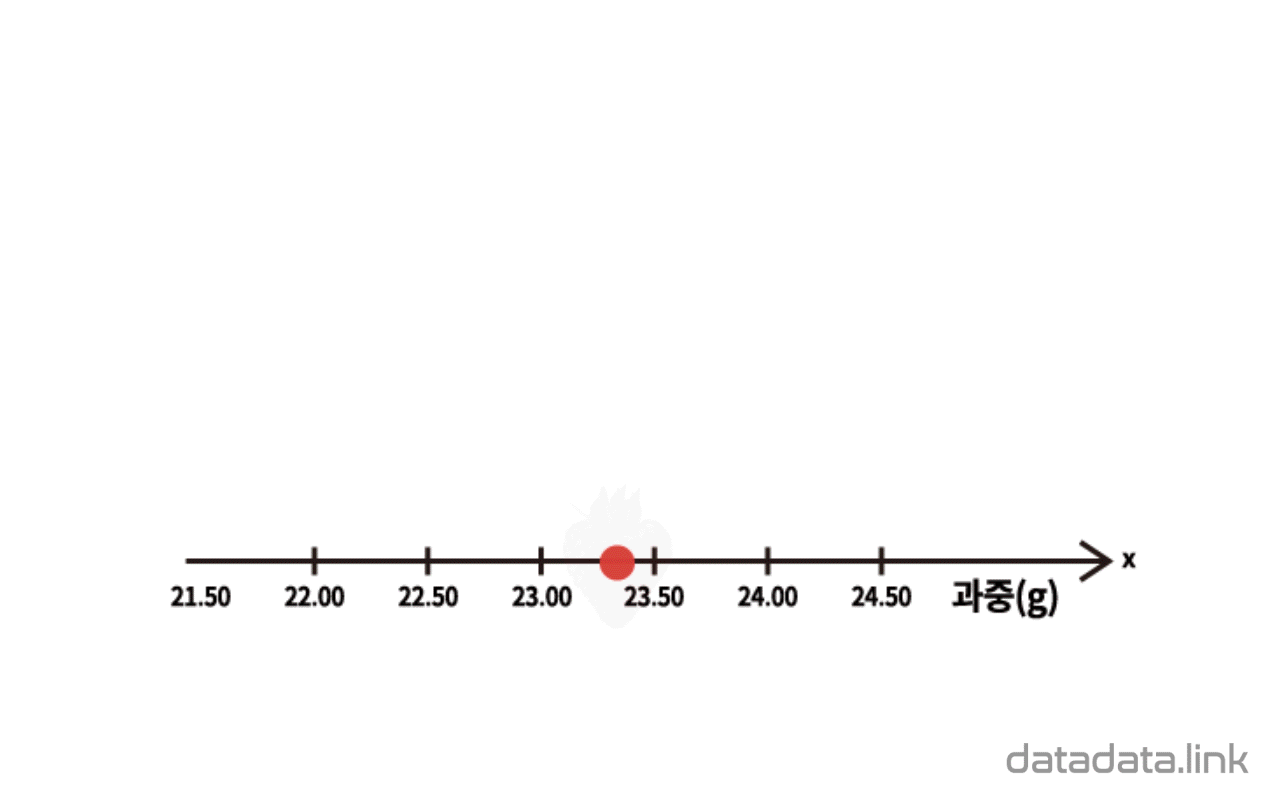
한편, 개체가 가지는 연속형 변수의 관측값(데이터)을 1차원 산점도로 시각화하면 점이 중첩되어 개체의 분포를 표현하기 어려운 경우가 많이 발생합니다. 이 때는 구간을 나누어야 하는 과정이 필요하지만 히스토그램이나 점그래프를 사용하여 개체의 분포를 표현합니다.
3. 실습
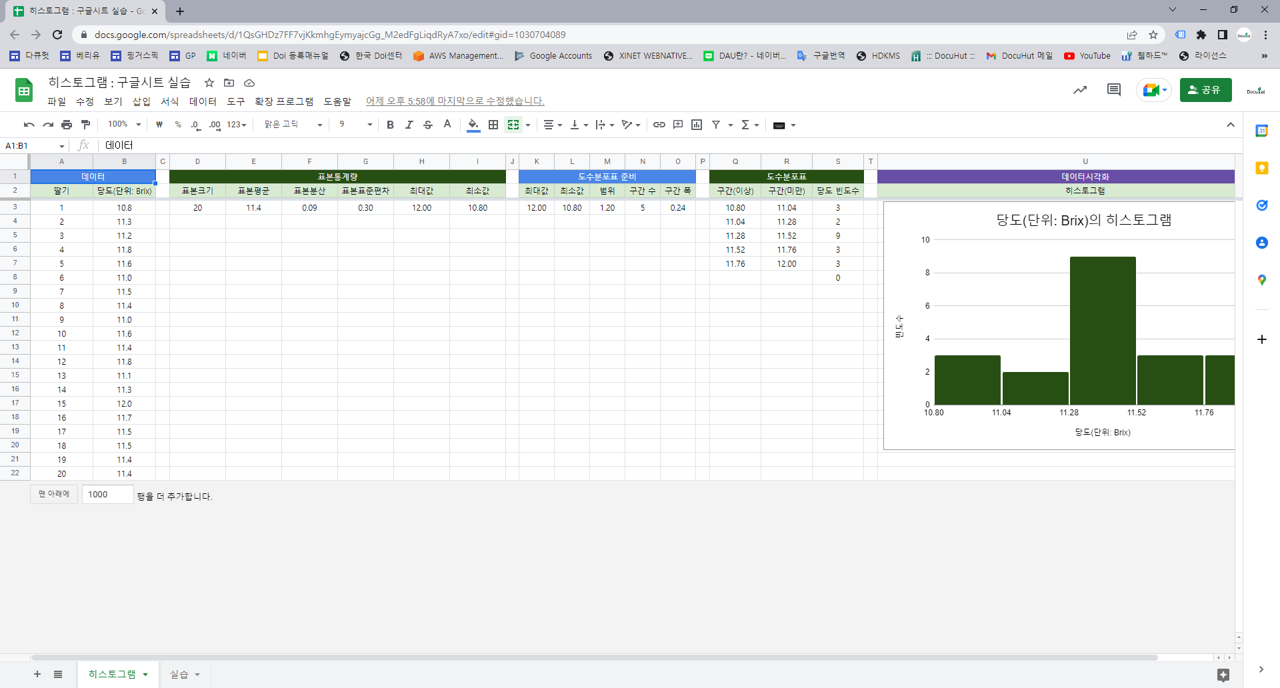
3.2. 구글시트 함수
=COUNT(B3:B22) : 데이터 개수. B3에서 B22에 있는 숫자로 표시된 데이터의 개수.
=AVERAGE(B3:B22) : 평균. B3에서 B22에 있는 데이터의 평균.
=VAR.S(B3:B22) : 표본분산. B3에서 B22에 있는 데이터의 표본분산. 편차제곱합을 데이터 개수 -1로 나눔.
=STDEV.S(B3:B22) : 표본표준편차. B3에서 B22에 있는 데이터의 표본표준편차. 표본분산의 제곱근.
=MIN(B3:B22) : 최소값. B3에서 B22에 있는 데이터 중에서 최소값을 표시함.
=MAX(B3:B22) : 최대값. B3에서 B22에 있는 데이터 중에서 최대값을 표시함.
=SQRT(D3) : 제곱근. D3값의 제곱근.
=ROUNDUP(SQRT(D3)) : 올림. D3값의 제곱근의 올림값.
=ROUND(M3/N3,2) : 반올림. M3값을 N3값으로 나눈 값을 반올림해서 소수점 2번째자리까지 표시.
=FREQUENCY(B3:B22,R3:R7) : 빈도수. B3에서 B22에 있는 데이터를 R3에서 R7까지의 구간에 맞춰 빈도수를 구함.
3.3. 실습강의
– 데이터
– 표본통계량
– 도수분포표
– 히스토그램
– 실습 안내
4. 참조
4.1 용어
히스토그램
데이터값의 분포를 표현하는 방식중의 하나입니다. 연속확률변수의 확률값을 막대그래프 모양으로 표현한 것입니다. Karl Pearson에 의해 처음 소개되었습니다.
히스토그램을 작성하려면 먼저 변수 범위를 구간(“bin”또는 “bucket”)으로 나눕니다. 그리고 각 구간에 몇 개의 데이터 값이 속하는 지를 정리합니다. 구간은 연속적이고 겹치지 않고 인접해야 하며 같은 간격이면 분석에 용이합니다.(구간 간격이 꼭 같아야 하는 것은 아닙니다.)
직사각형(막대)의 높이에 비례하는 빈도수는 상대빈도수로 정규화될 수 있습니다. 구간들이 동일한 간격이고 간격이 1인 경우, 빈도수를 정규화하게 되면 각 직사각형의 높이는 상대빈도수를 표현하는 확률이 되어 각 직사각형의 높이의 합은 1이 됩니다. 그러나 구간은 동일한 폭(구간크기)일 필요는 없습니다. 이 경우 직사각형(막대)은 구간의 빈도수에 비례하는 면적을 갖도록 정의됩니다 . 수직축은 빈도수가 아니라 빈도수밀도(수평축상의 변수의 단위당 경우의 수)입니다. 모양은 막대 그래프의 막대가 서로 인접한 모양으로 변수가 연속적으로 표현되었다는 것이 중요합니다.
히스토그램은 데이터의 기본 확률분포밀도를 대략적으로 나타내며, 확률밀도 추정시 자주 사용됩니다 . 즉, 기본 확률변수의 확률밀도함수를 나타냅니다 . 확률 밀도에 사용되는 히스토그램의 총 면적은 항상 1로 정규화됩니다. $X$ 축의 간격이 모두 1이면 히스토그램은 상대빈도 막대그래프와 동일합니다 . 히스토그램은 통계적 속성을 모델링해야 할 때 통계 패키지 프로그램에서 자주 쓰입니다. 예를 들면, 커널 밀도 추정치의 상관 관계 변이는 수학적으로 설명하기가 매우 어렵지만 각 구간이 독립적으로 변하는 히스토그램에서는 이해하기가 쉽습니다. 커널 밀도 추정의 대안은 평균 이동된 히스토그램입니다 계산 속도는 빠르며 커널을 사용하지 않고 밀도를 부드럽게 계산할 수 있습니다.
히스토그램은 때때로 막대그래프와 혼동됩니다.히스토그램은 연속 데이터에 사용되기 때문에 막대는 붙어 있게 됩니다. 그래서 구별을 분명히 하기 위해 막대그래프는 막대 사이에 간격을 줍니다.
Reference
막대그래프
막대그래프는 데이터값에 비례하는 길이를 가지는 직사각형 막대로 데이터값을 표현합니다. 막대그래프는 세로 또는 가로로 그릴 수 있습니다. 세로 막대그래프는 때로는 선 그래프와 같이 표현됩니다. 막대그래프는 각 범주간 데이터값을 잘 비교합니다. 그래프의 한 축은 비교할 특정 범주를 표시하고 다른 축은 측정된 데이터값을 길이로 나타냅니다. 막대 그래프를 응용하면 두 개 이상의 그룹으로 묶어서 막대를 나타낼 수 있으며 둘 이상의 측정 변수의 값을 비교하여 보여 줄 수 있습니다.
Reference
4.2. 참고문헌