교차표 ?
Cross table ?
1. 애니메이션
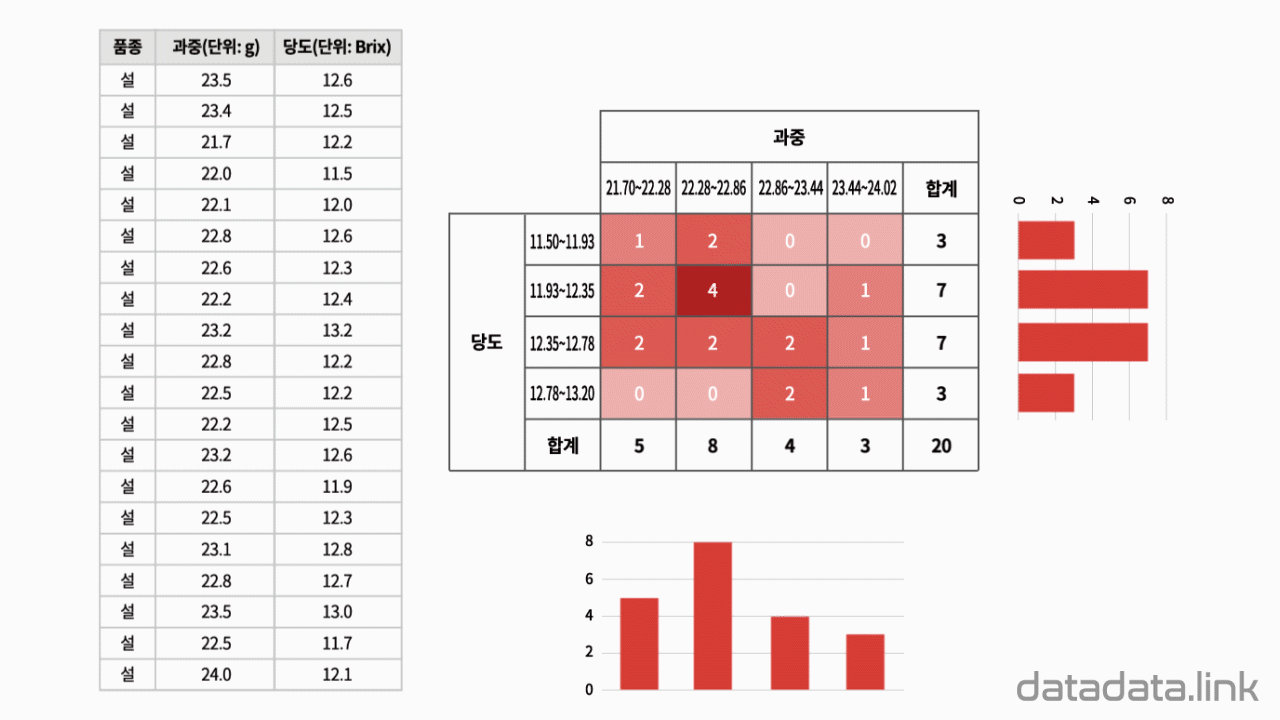
4 × 4 교차표 : 이산확률분포
2 × 2 교차표 : 이항검정
2. 설명
2.1. 교차표의 적용 예
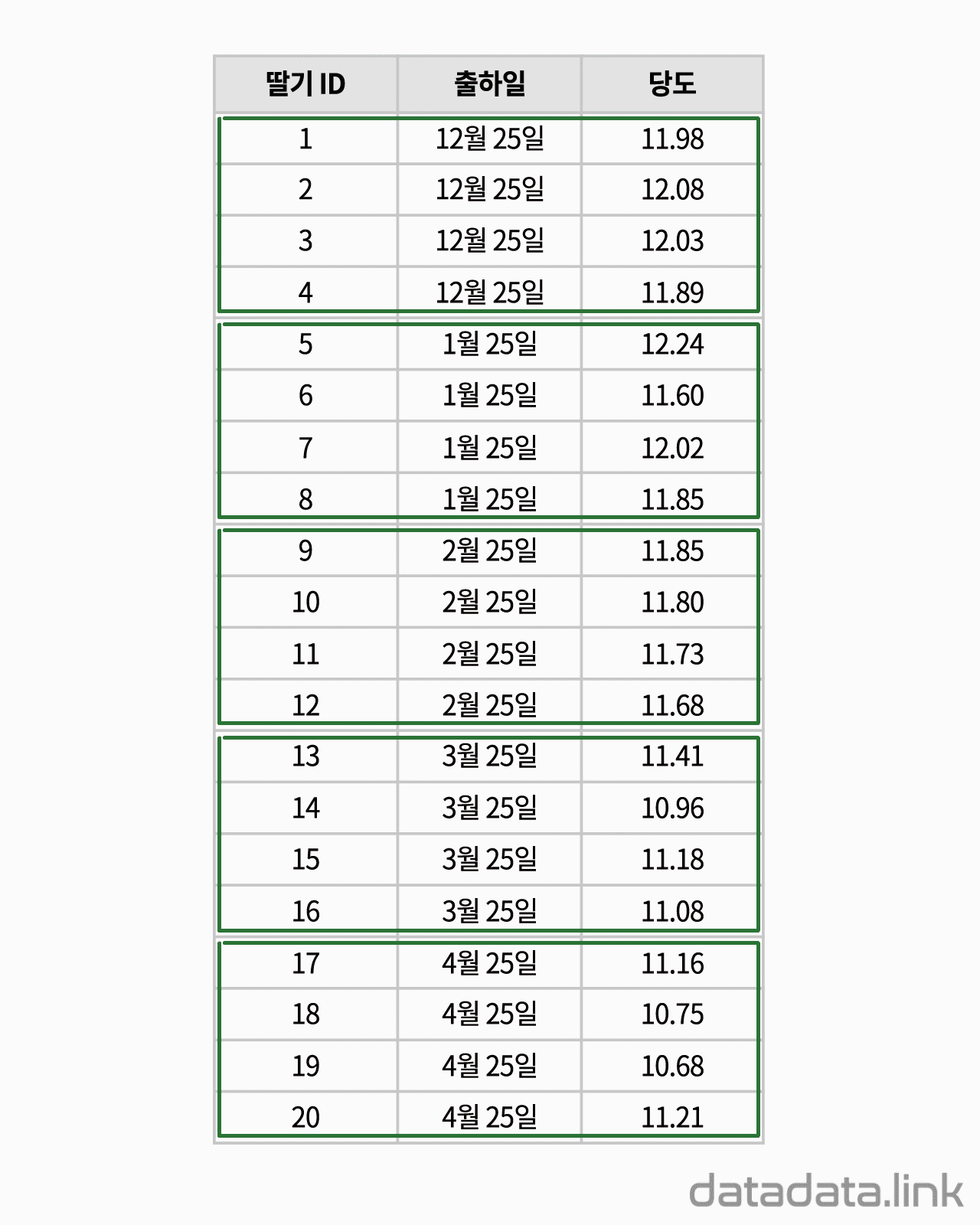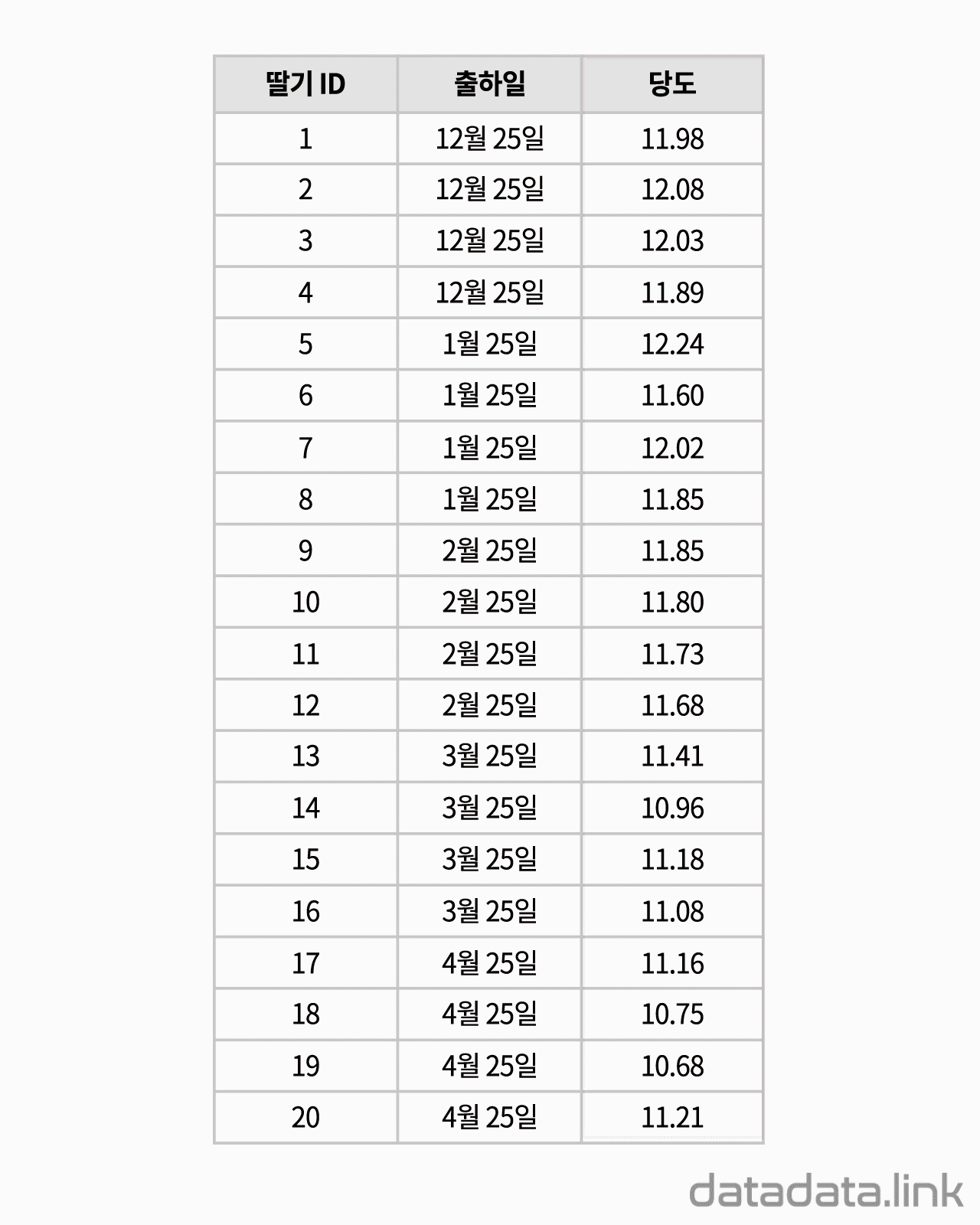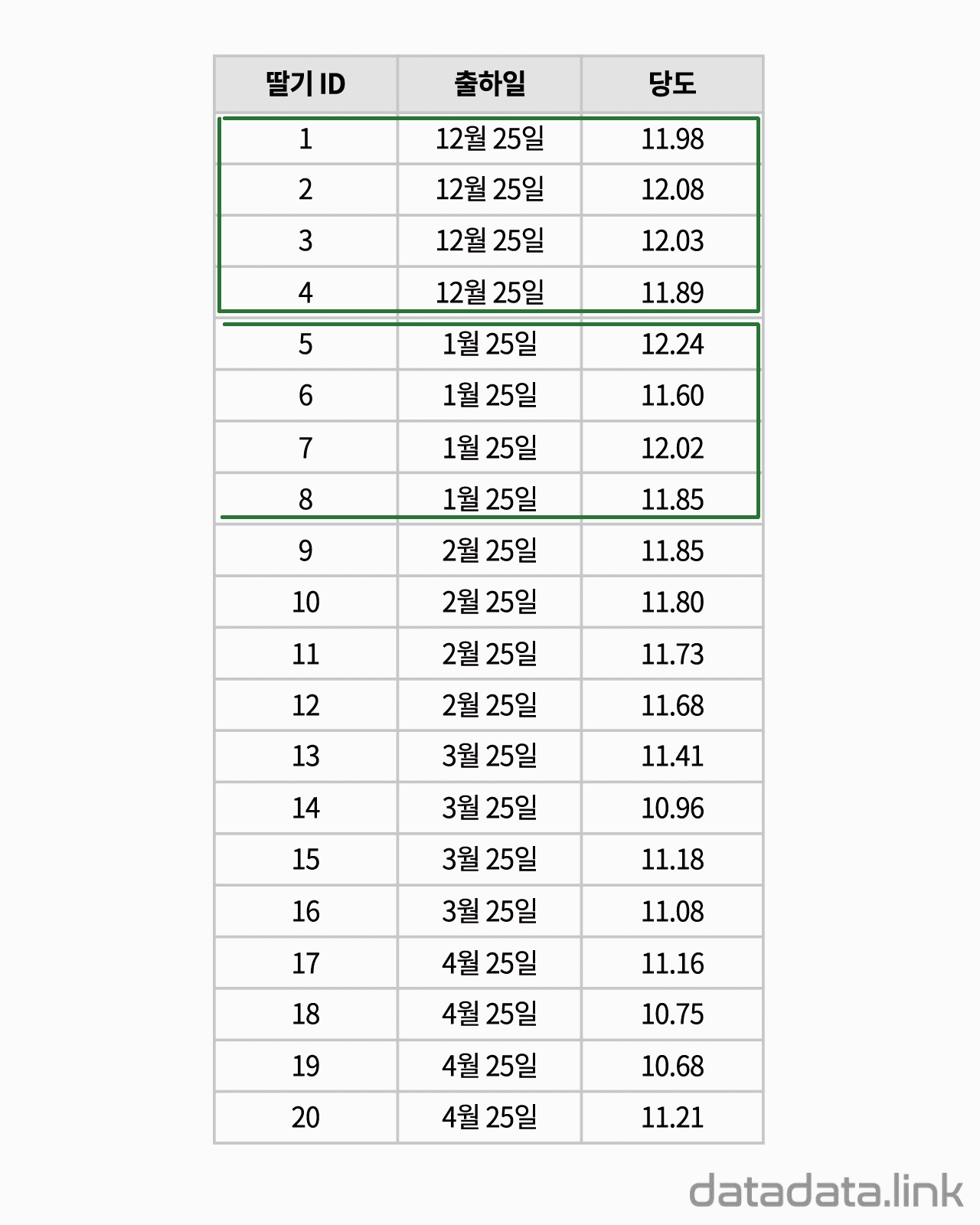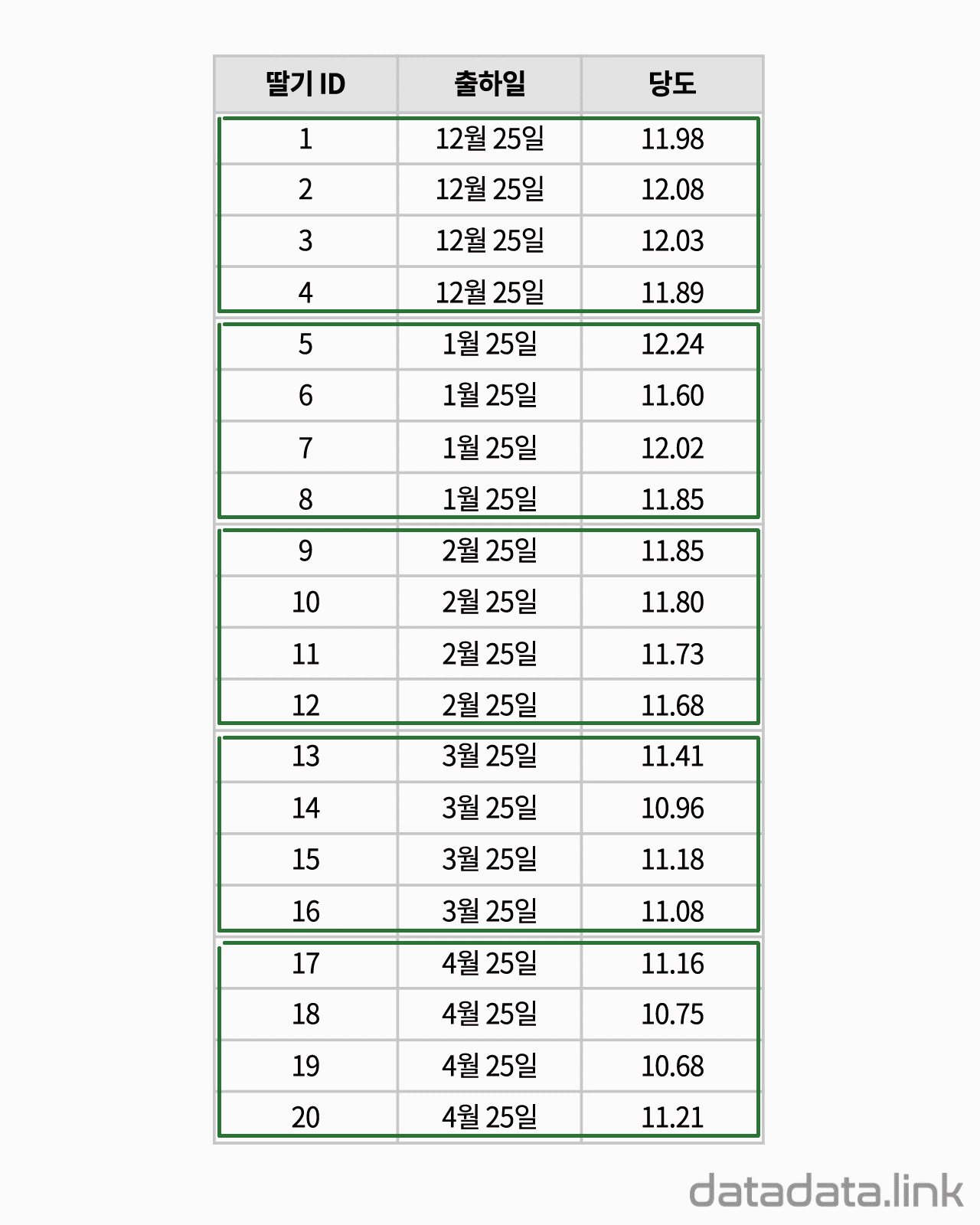
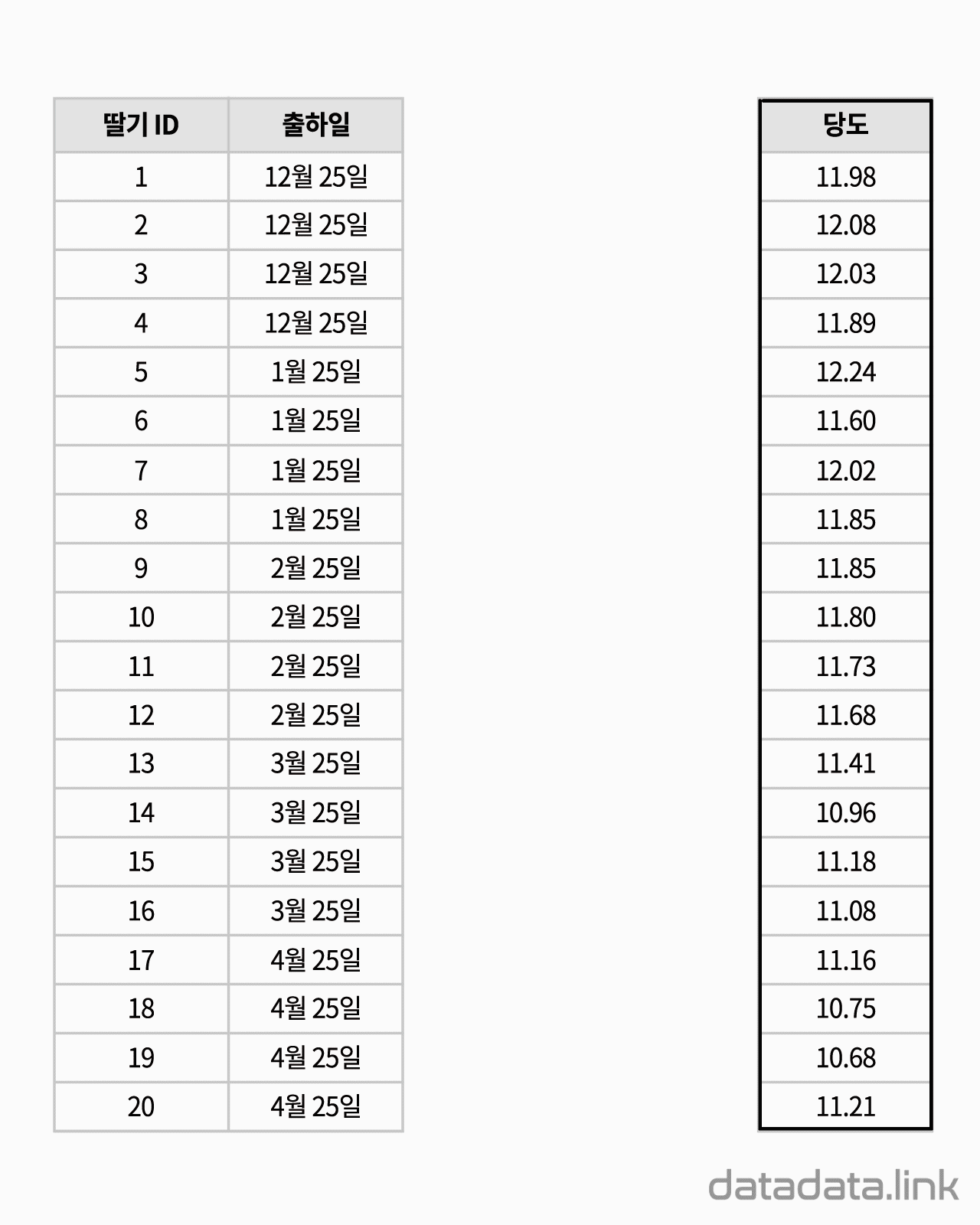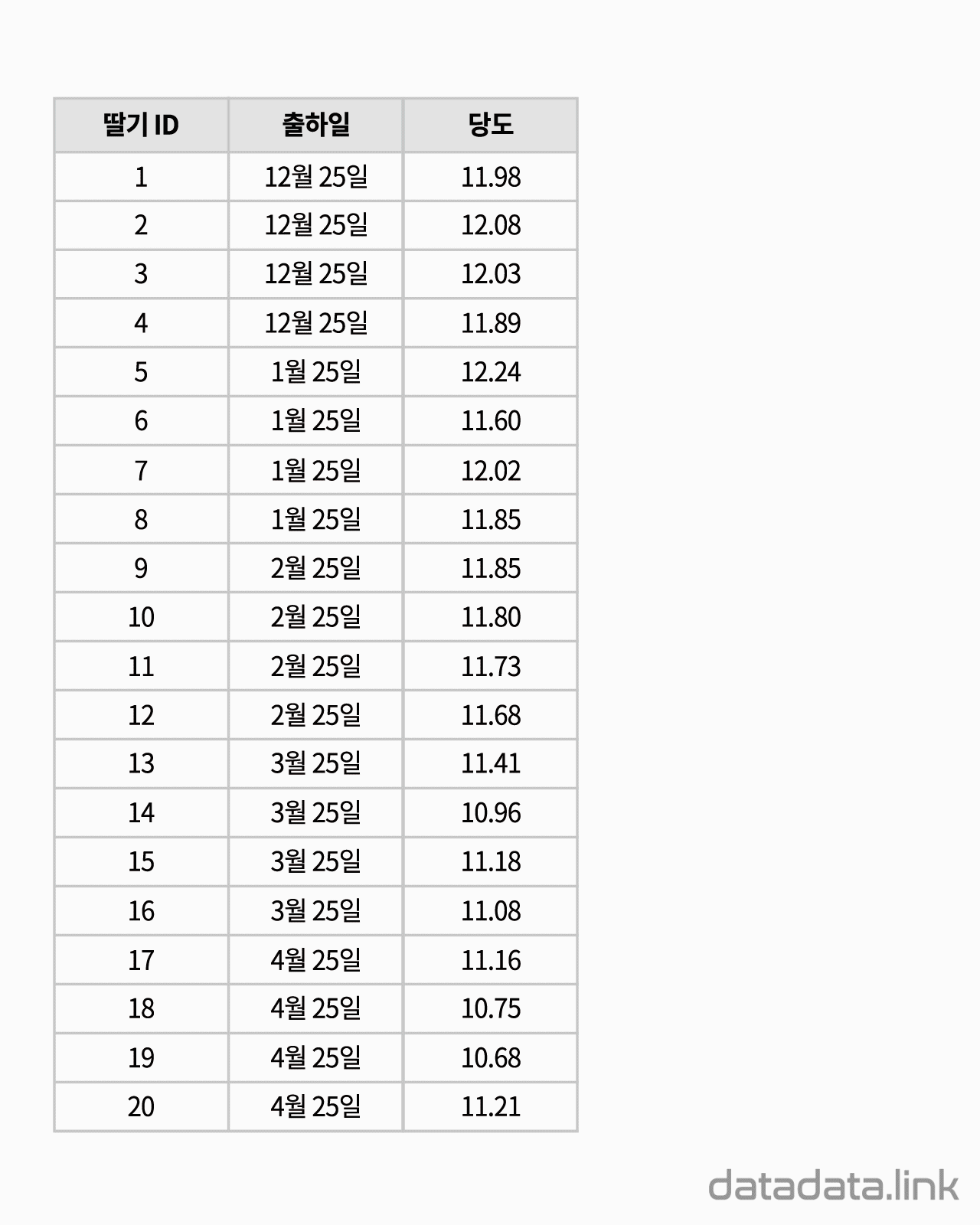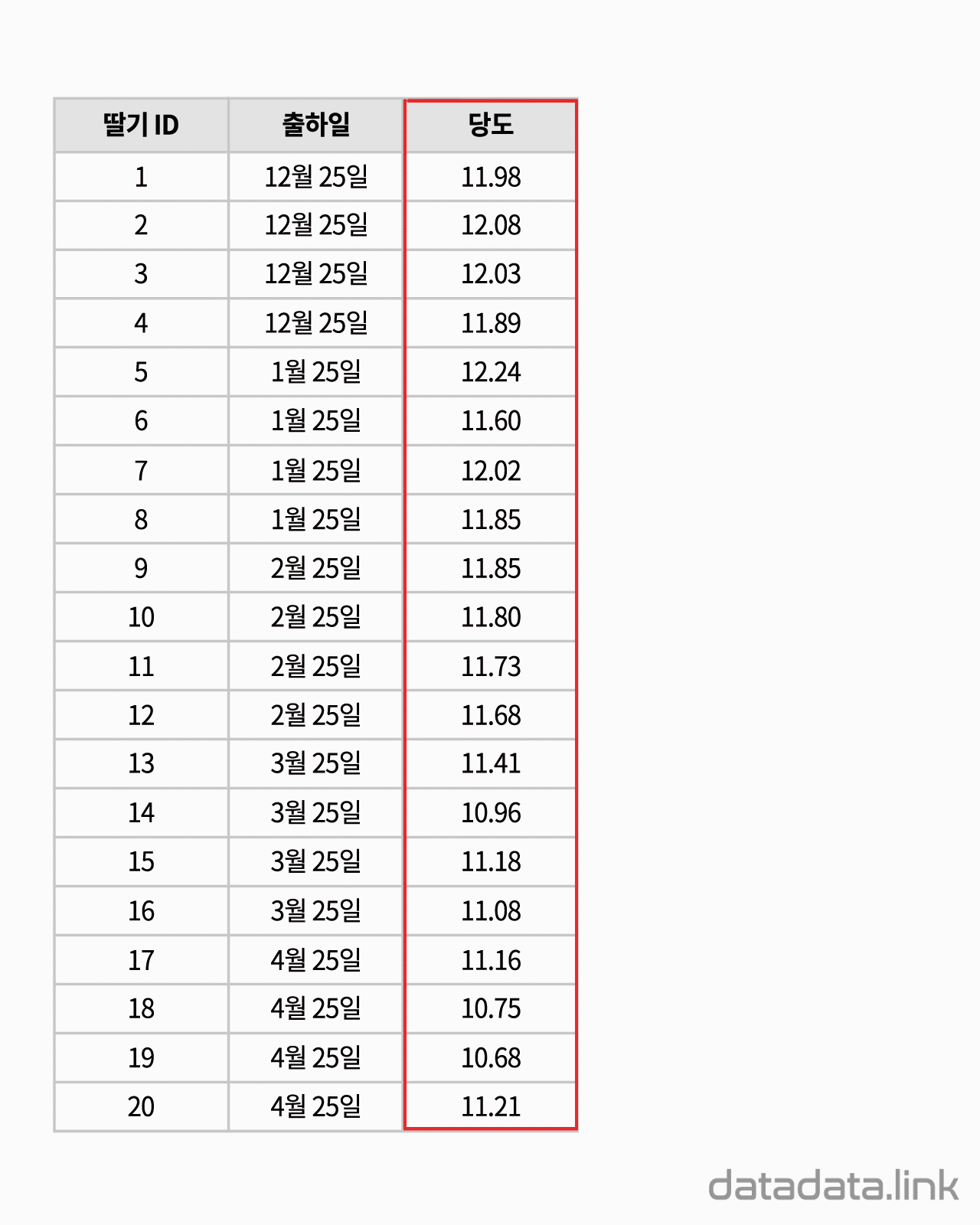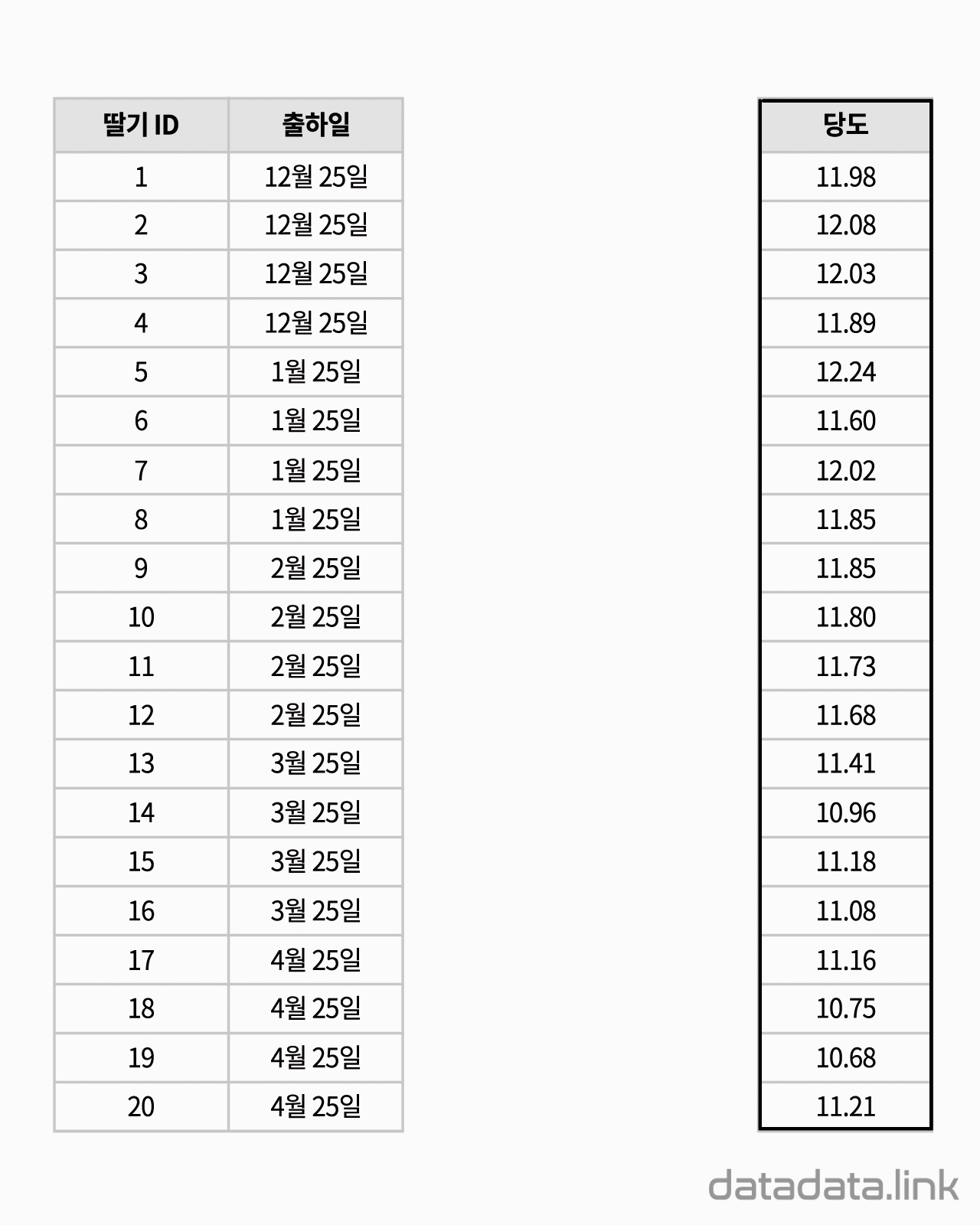
교차표(cross table)은 두 확률변수의 확률분포를 나타내기 위해서 사용합니다. 참고로 한 확률변수의 확률분포를 나타내는 것은 도수분포표입니다. 대응된 두 변수의 데이터로 교차표(cross table)를 만듭니다.
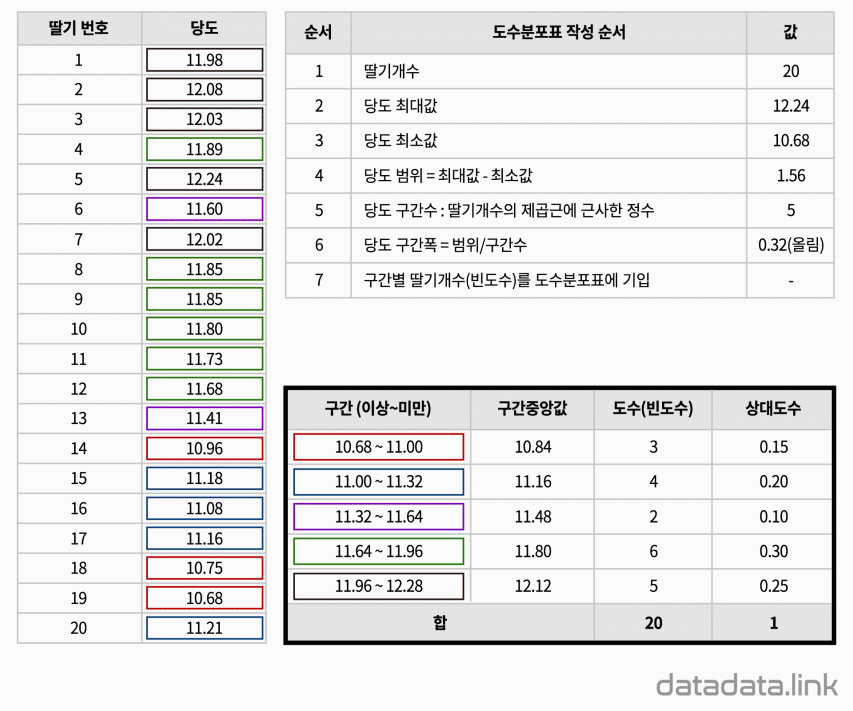
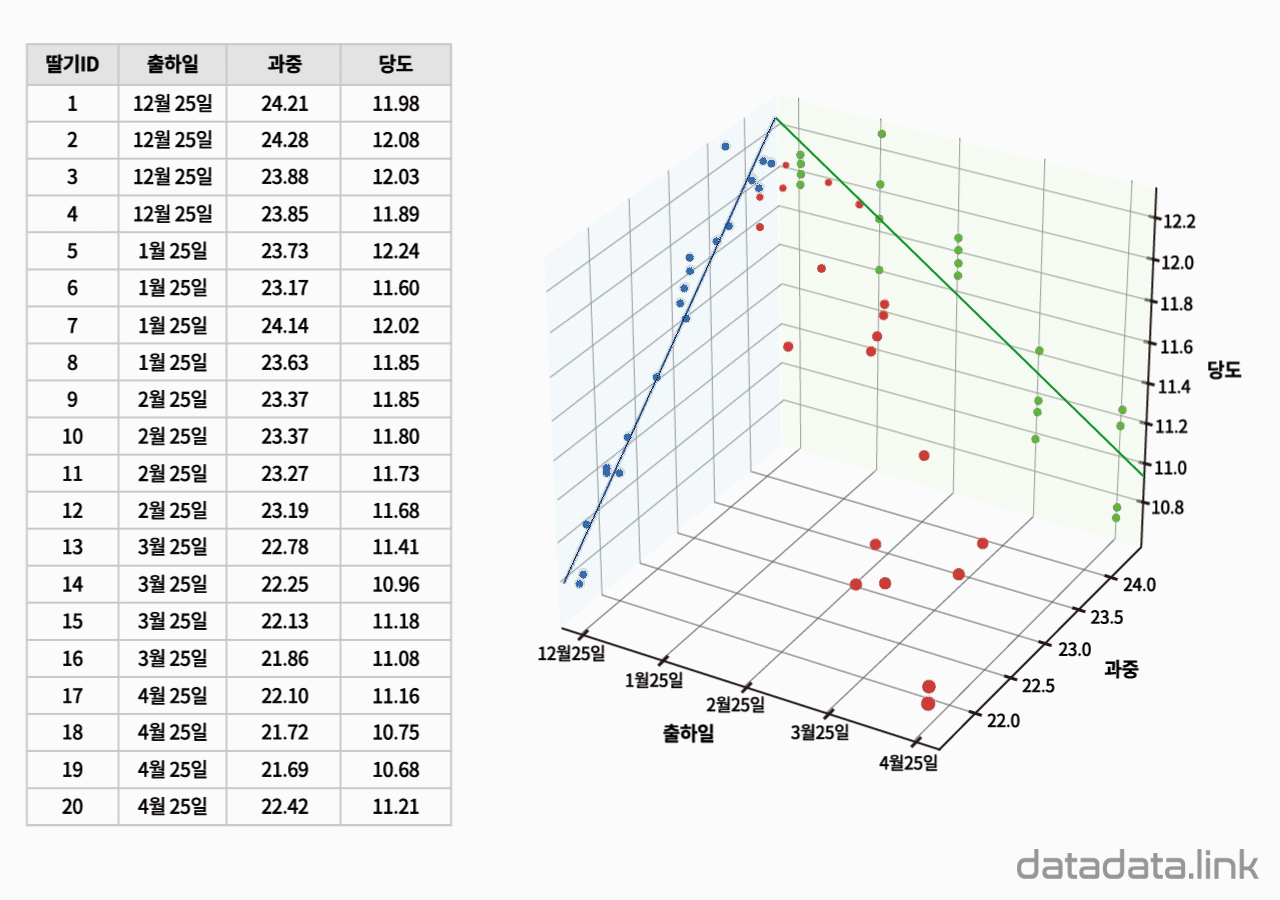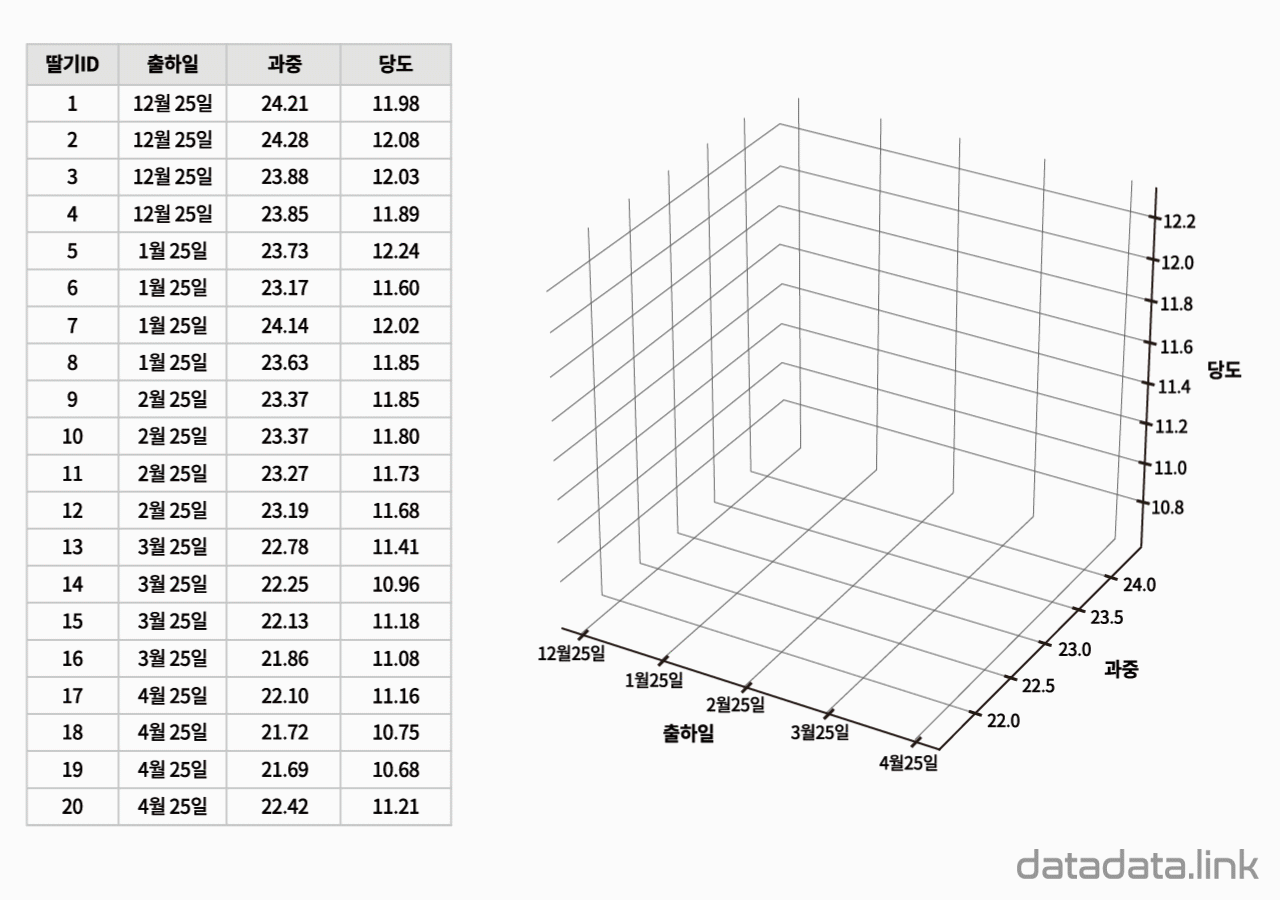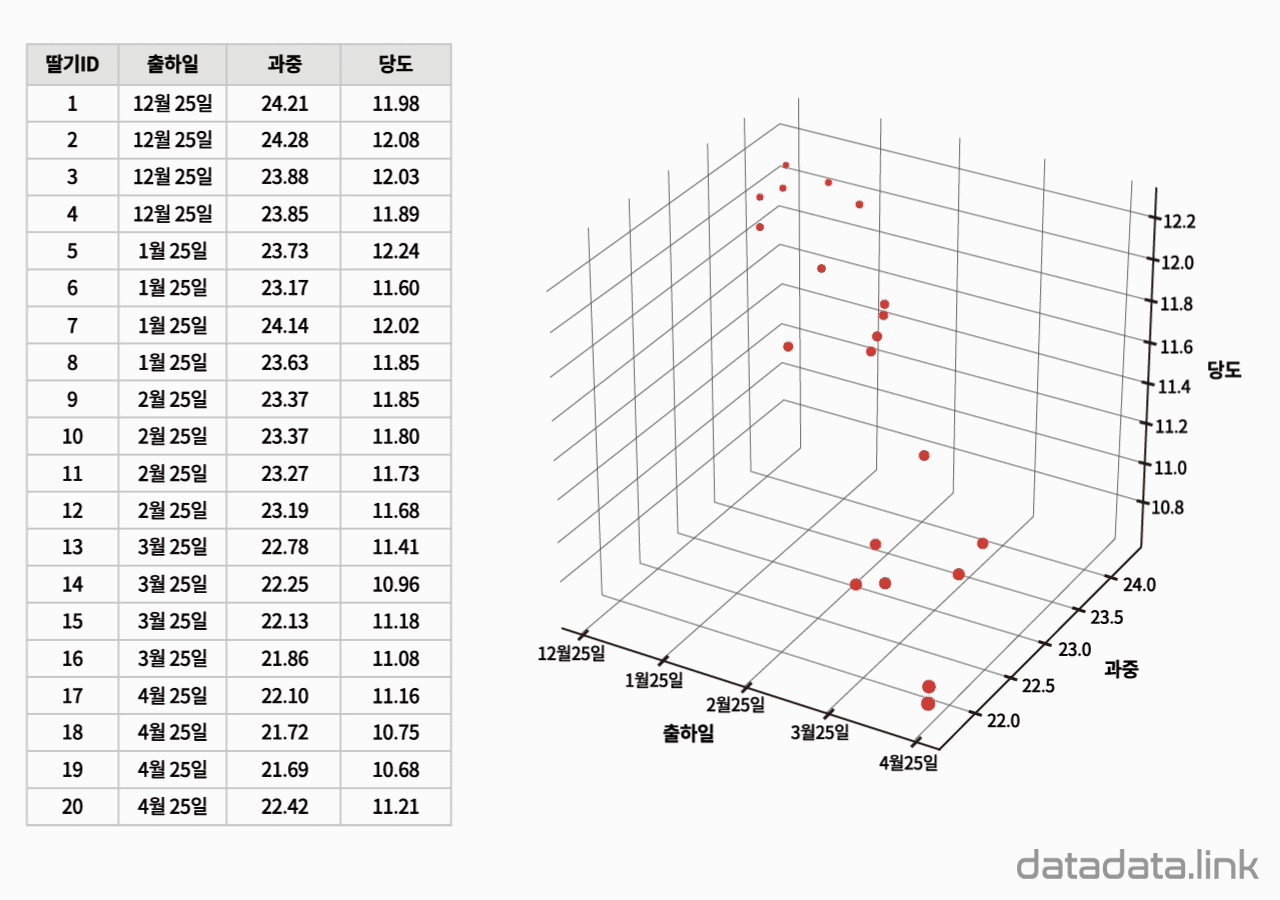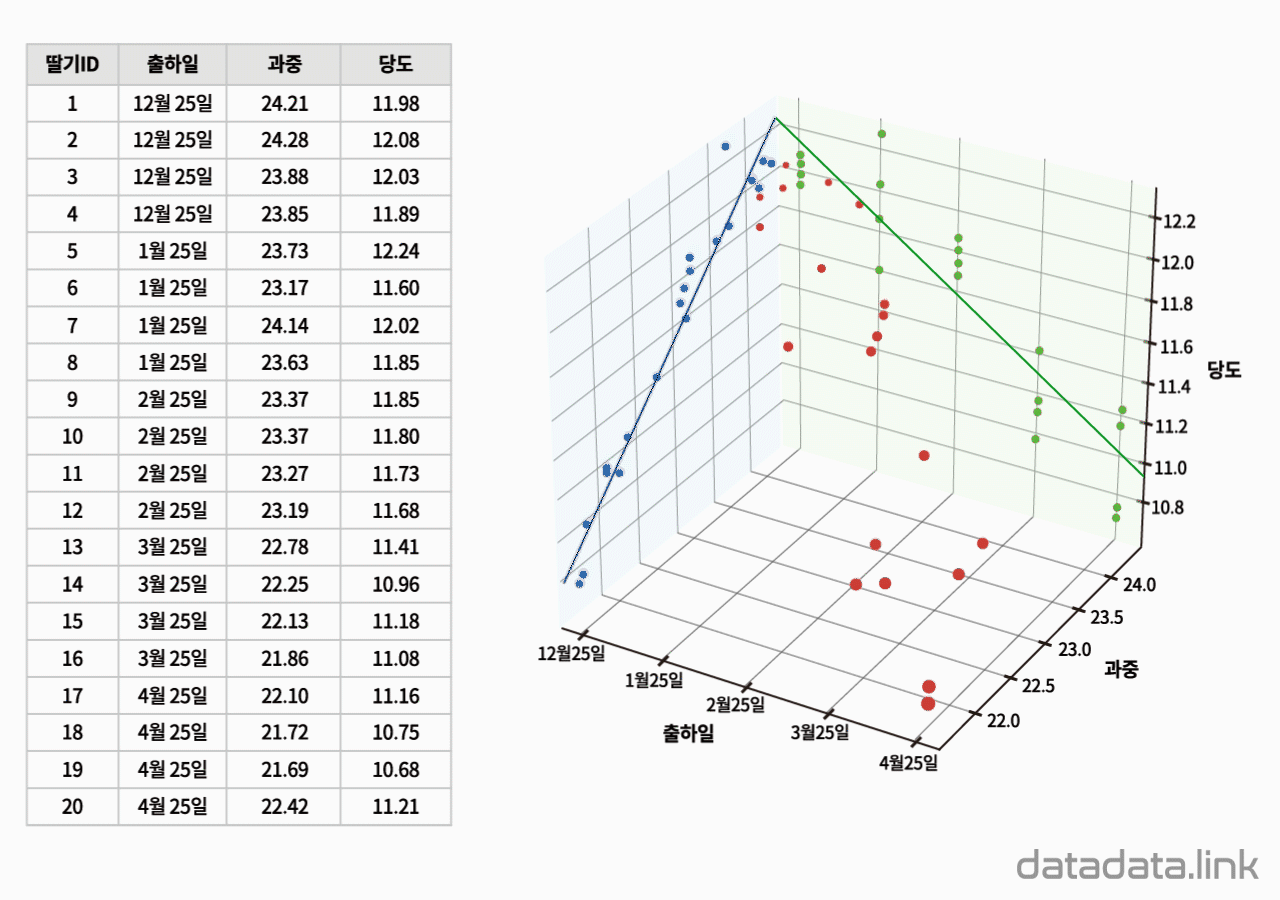
위 애니메이션에서 표본을 이루는 개체는 딸기품종 중에서 설이고 개체가 가지는 확률변수는 과중과 당도입니다. 그리고 20개의 표본크기를 가지고 있습니다. 연속형 확률변수를 구간화하여 범주형 확률변수로 만듭니다. 여기서는 등간격으로 5구간과 4구간으로 나누었습니다. 만일 , 두 변수가 범주형 확률변수인 경우에는 구간을 나눌 필요가 없이 바로 교차표를 만들 수 있습니다. 교차표가 만드는 각 칸(cell)에는 빈도수가 들어갑니다. 빈도수가 높은 칸은 개체가 나타날 확률이 높은 구간입니다. 구간의 수를 정할 때 확률분포의 모양이 잘 나타나도록 하는 것이 중요합니다. 구간의 수는 데이터의 개수와 데이터의 범위를 함께 고려하여 정합니다.
두 확률변수의 확률분포는 교차표의 주변에 표시합니다.교차표의 주변에 표시한다고 하여 이 확률분포를 주변확률분포(marginal probability distribution)라 합니다. 두 확률변수의 관계를 나타내는 빈도수 분포는 교차표 안에 나타납니다. 빈도수가 클수록 진하게 표시하여 분포를 시각화하여 보았습니다. 대응된 두 확률변수의 분포를 보여준다고 하여 결합확률분포(joint probability distribution)라고 합니다. 결합확률분포는 주변확률분포를 반영하고 동시에 두 확률변수의 상관을 보여줍니다. 상관에는 대표적으로 선형상관이 있습니다.
2.2. 교차표
데이터로 교차표(cross table or contingency table)를 만듭니다. 두 개의 확률변수를 분류(categorize)하여 집단을 만들고 각 집단에 속하는 데이터의 빈도수를 확률변수가 교차하여 만들어진 칸(cell)에 나타냅니다. 교차표는 두 확률변수의 관계를 나타내는 표라고 할 수 있습니다. 교차표는 서로 다른 두 확률변수의 도수분포표를 2차원으로 확장하여 도수분포표의 구간이 교차하는 칸(cell)을 만들어서 빈도수를 적은 것입니다. 간단하게 2차원 도수분포표라고 할 수 있습니다. 연속형 데이터의 경우 도수분포표를 만들 때와 같이 구간을 나누어 빈도수를 조사한 다음 교차표를 만듭니다.
두 변수가 범주형 확률변수일때 교차표의 쓰임새는 여러가지 검정에 사용할 수 있습니다. 이 때 교차표는 한 변수의 속성(범주형 확률변수값, 수준)을 행에 놓고 나머지 변수의 속성(범주형 확률변수값, 수준)을 열에 놓아 셀(Cell)을 만듭니다. 행변수의 속성과 열변수의 속성이 교차하는 셀(cell)에 두 속성을 동시에 가지는 데이터의 빈도수를 넣습니다. 교차표를 작성하여 도수분포를 살펴보면 대략 두 변수 사이의 관계를 알 수 있습니다. 분석을 위해 각 셀의 빈도수 밑에 행의 합에 대한 백분율, 열의 합에 대한 백분율, 그리고 전체 백분율을 표시하기도 합니다.
3. 실습

3.2. 구글시트 함수
=COUNTIF(C3:C22,”>=12″) : 조건에 맞는 데이터 개수. C3에서 C22 범위에 있는 데이터 중에서 12 이상의 데이터 개수를 세어서 표시함.
=SUM(G5:H5) : 합계. G5에서 H5에 있는 데이터들의 합계.
3.3. 실습강의
– 데이터
– 교차표
– 실습 안내
4. 용어
4.1 용어
빈도수
통계에서 사건의 빈도 (또는 절대 빈도)는 실험이나 연구에서 사건이 발생한 횟수입니다. 이러한 빈도수는 종종 히스토그램으로 표현됩니다.
Reference
Frequency (statistics) – Wikipedia
도수분포
통계에서 도수분포(빈도수분포)는 표본의 실험이나 측정항목의 빈도수를 표시하는 표(도수분포표)나 그래프(도수분포도)로 나타냅니다. 도수분포표의 각 항목에는 특정 집단 또는 특정 구간 내의 값이 발생하는 빈도수가 나타납니다. 도수분포표는 표본의 변수 분포를 요약하는 효과적인 방법입니다.
Reference
Frequency distribution – Wikipedia